↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
High annotation costs and limitations of existing large language model (LLM)-based approaches are major hurdles in many machine learning projects. LLM-based methods often involve expensive API calls and the resulting datasets are challenging to adapt or audit. This research addresses these limitations. The proposed approach generates code (programs) that act as data labelers, thereby drastically reducing the reliance on expensive API calls and making auditing easier.
The system, called Alchemist, achieves comparable or better performance in various tasks at a fraction of the cost. The core innovation is the use of program synthesis instead of directly querying LLMs for labels. The generated programs are locally executable, enabling cost-effective and easily adaptable labeling pipelines. Alchemist demonstrates its capabilities across multiple datasets and extends beyond text modalities to images via a simple multimodal extension, offering a versatile solution for researchers.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers seeking cost-effective and efficient data annotation methods. It introduces a novel approach that significantly reduces annotation costs while maintaining or even improving accuracy, impacting various fields relying on labeled datasets. The open-source code and extension to non-text modalities further enhance its impact, opening doors for diverse applications and future research. This will be highly beneficial for researchers that lack big budget.
Visual Insights#

This figure shows two examples of Python code generated by GPT-4 to perform labeling tasks. The left example uses regular expressions to identify spam in YouTube comments, while the right example uses keyword matching to classify biomedical documents by cancer type (colon, lung, or thyroid). This illustrates how the ALCHEMist system generates programs for labeling, rather than directly generating labels.
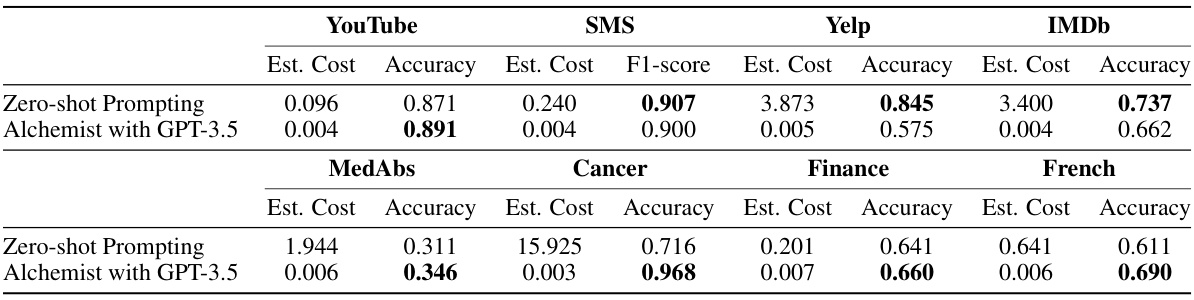
This table presents the results of using a distilled model trained on labels generated by Alchemist and compares its performance with labels generated using zero-shot prompting. It shows the accuracy and estimated cost (based on GPT-3.5 pricing) for various datasets across different tasks, highlighting the cost-effectiveness of the Alchemist approach. The cost reflects the number of tokens processed by the language model.
In-depth insights#
Cost-Effective Labeling#
The concept of ‘Cost-Effective Labeling’ in machine learning centers on reducing the expenses associated with data annotation while maintaining or improving data quality. Traditional methods, such as hiring human annotators, are expensive and time-consuming. The paper explores innovative approaches to decrease these costs, such as employing large pre-trained models (LLMs) as annotators. However, using LLMs directly can be prohibitively costly due to API call expenses. Therefore, the paper proposes an alternative: using LLMs to generate programs that can perform labeling tasks. This approach significantly lowers the cost by enabling local execution and reuse of generated programs, rather than repeated API calls for every data point. The key benefit is that the initial investment in program generation leads to substantial cost savings in the long run, making the overall labeling process significantly more efficient and affordable. Alchemist, the proposed system, demonstrates the effectiveness of this strategy, achieving considerable cost reductions (approximately 500x) while also enhancing accuracy on several datasets.
Program Synthesis#
Program synthesis, in the context of this research paper, is a powerful technique for automating data labeling. Instead of directly querying a large language model (LLM) for labels, which can be expensive, the approach focuses on prompting the LLM to generate programs that can produce labels. This is a significant cost reduction strategy, as these generated programs are reusable and can be applied locally, eliminating the need for repeated API calls. Furthermore, this method offers improved auditability and extensibility. The programs themselves can be inspected and modified, allowing for easy adaptation and improvements. However, challenges exist, including the potential for inaccurate or flawed programs. Therefore, weak supervision techniques are employed to aggregate outputs from multiple programs, mitigating the effects of noisy predictions. The integration of weak supervision, coupled with the program synthesis approach, creates a robust and cost-effective data labeling system that enhances performance while dramatically lowering costs.
Multimodal Extension#
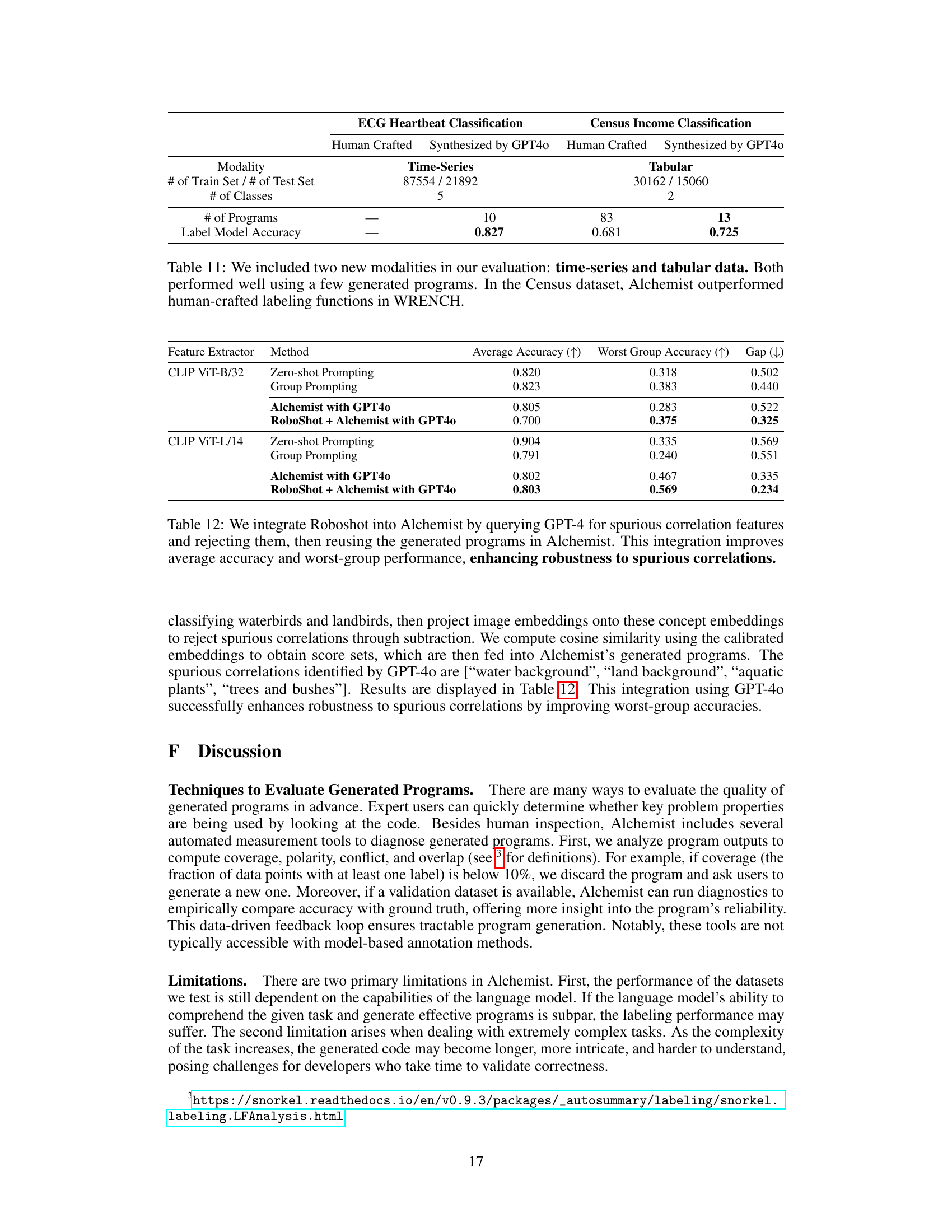
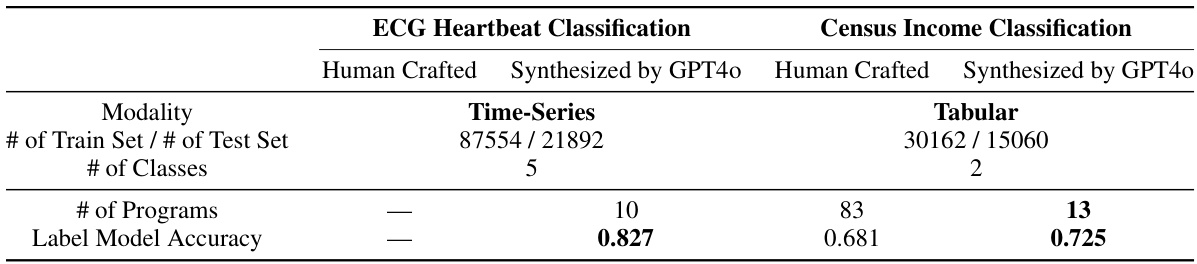
The multimodal extension in this research paper is a crucial advancement, addressing a key limitation of traditional text-based approaches. By incorporating non-text modalities, such as images, the system overcomes the narrow scope of text-only processing and expands its applicability to a wider range of tasks. This is achieved by a two-step process: First, a language model identifies high-level concepts relevant to the task. Then, a local multimodal model extracts features for these concepts, effectively translating diverse data types into a unified representation suitable for program generation. This methodology enhances the system’s robustness by mitigating the effects of spurious correlations, those misleading connections that can arise from raw, unprocessed data. The successful application of this extension to the Waterbirds dataset, with improved performance and robustness, showcases its potential and provides a template for other modalities.
Weak Supervision#
Weak supervision is a powerful paradigm in machine learning that addresses the challenge of acquiring large, high-quality labeled datasets. It leverages multiple noisy, inexpensive sources of supervision, such as heuristics, noisy labels from crowdsourcing, or even the outputs of less accurate models. Instead of relying on perfectly clean labels, weak supervision combines these weaker signals, creating a more robust and comprehensive training set. This approach reduces the cost and time associated with manual labeling, a significant bottleneck in many machine learning projects. A key advantage is its scalability: it can effectively handle large datasets and adapt to various modalities of data. While weak supervision offers significant advantages, it also presents challenges. Robust techniques for aggregating and reconciling conflicting signals from diverse sources are critical for obtaining reliable pseudo-labels. The development of sophisticated algorithms, like those implemented in the Snorkel framework, is essential for achieving high performance. This technique has seen increasing popularity and application in various domains, demonstrating its effectiveness in resolving the data scarcity issue.
Future Directions#
Future research could explore enhancing Alchemist’s capabilities by integrating more sophisticated prompting techniques, potentially incorporating external knowledge sources or leveraging advanced language models to generate more robust labeling programs. Investigating alternative weak supervision strategies beyond Snorkel, and evaluating their effectiveness with Alchemist, warrants further study. Expanding Alchemist’s adaptability to a wider array of data modalities (e.g., audio, video, time-series data) presents a significant opportunity, demanding the development of efficient feature extraction methods and the adaptation of program generation to these new domains. Furthermore, research into techniques for improving the robustness of generated programs to noisy or ambiguous data is crucial. This may involve incorporating error correction or refinement processes into the program synthesis pipeline, or employing ensemble methods to aggregate outputs from multiple programs. Finally, a thorough examination of the ethical implications of using large language models for data annotation, including issues of bias, fairness, and transparency, is imperative for responsible development and deployment.
More visual insights#
More on figures

The figure illustrates the overall workflow of the Alchemist system. It starts with specialized prompt design, which is fed into a language model for program generation. These generated programs then collect outputs, which are finally aggregated for use in a downstream task. This shows how Alchemist uses language models to generate programs that perform the labeling task, rather than directly querying labels from the models. This approach allows for significant cost reductions and improvements in label quality.
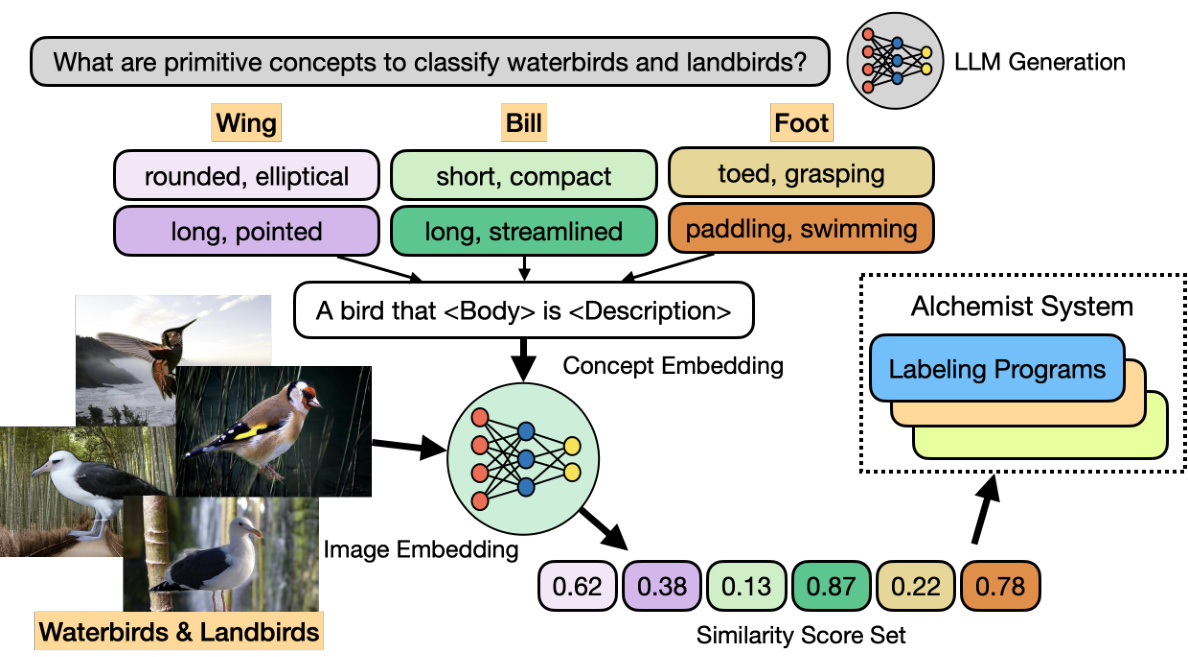
This figure illustrates how Alchemist extends its capabilities to handle non-text modalities, such as images. It shows a two-step process: 1) A language model identifies key concepts for classifying the data (e.g., ‘wing shape’, ‘bill length’), and 2) A local multimodal model extracts features representing these concepts from the raw image data, generating low-dimensional vectors. These vectors are then used as input to the generated labeling programs produced by Alchemist.

This figure shows two example programs generated by GPT-4 for the Waterbirds dataset. The left program attempts to classify birds as landbirds or waterbirds based directly on raw pixel data from images, using color as a proxy for the environment. This method is prone to errors due to spurious correlations (e.g., a bird in a green field might incorrectly be classified as a landbird). The right program uses Alchemist’s extension, which leverages higher-level concepts and similarity scores from a multimodal model. This approach is more robust to spurious correlations.

This figure displays the impact of the number of collected programs on the performance of a label model in three different datasets: SMS, Yelp, and IMDb. The x-axis represents the number of programs collected, and the y-axis shows the average F1-score or accuracy for each dataset. The shaded areas represent the standard deviation, indicating the variability in performance. The results suggest that increasing the diversity of programs can improve the label model’s performance.
More on tables
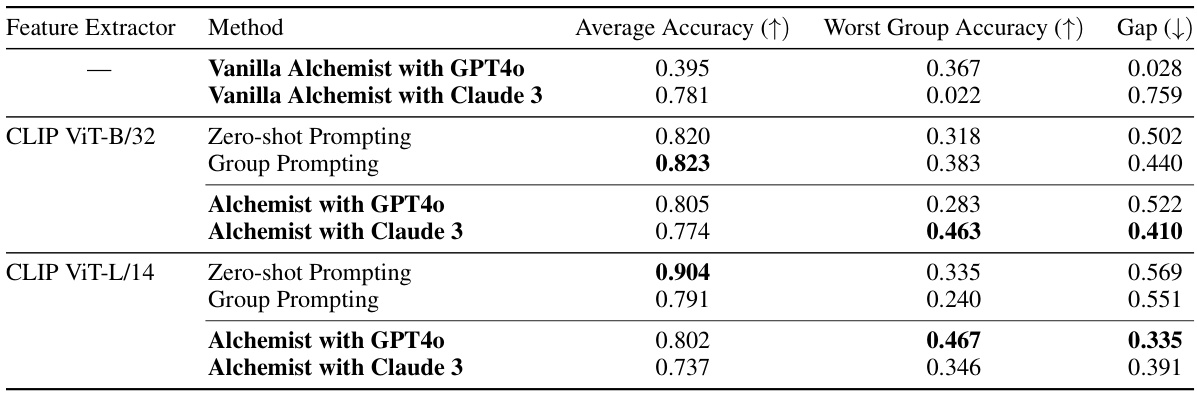
This table presents the results of experiments conducted to evaluate Alchemist’s performance on non-text modalities (images). Three different feature extractors were used: none, CLIP VIT-B/32, and CLIP VIT-L/14. For each feature extractor, three methods were compared: standard Alchemist, a group prompting approach, and CLIP prompting baselines. The table shows the average accuracy, worst group accuracy, and the difference between them (gap). The results demonstrate that Alchemist’s extension, utilizing local multimodal models as feature extractors, improves robustness to spurious correlations, achieving comparable average accuracy with better worst-group accuracy.

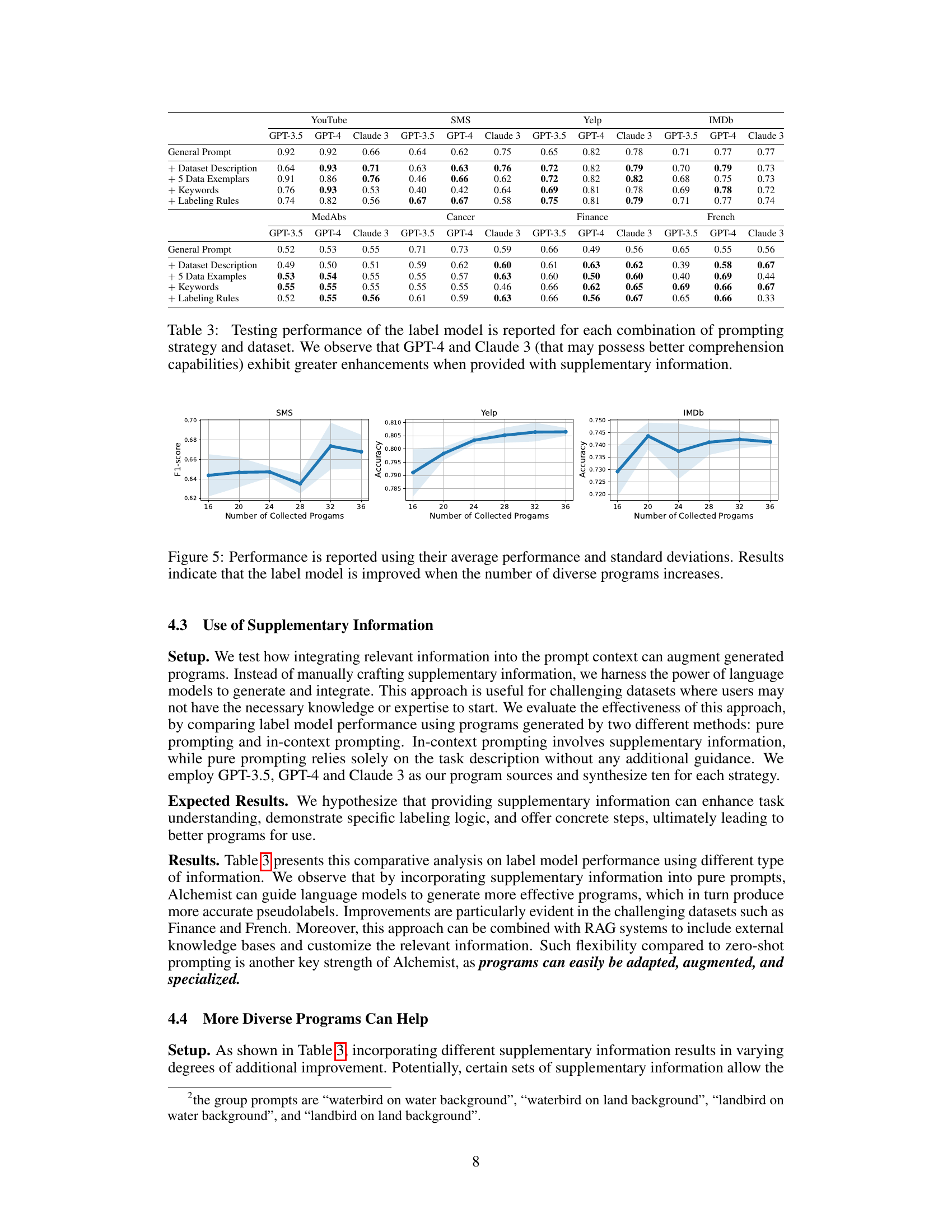
This table presents the results of an experiment evaluating the performance of a label model under different prompting strategies and datasets. The prompting strategies involved incorporating various types of supplementary information (dataset description, data exemplars, keywords, and labeling rules) to enhance the language model’s ability to generate effective programs for labeling data. The table shows the performance (F1-score or Accuracy) achieved by different language models (GPT-3.5, GPT-4, Claude 3) under each prompting strategy and for each dataset. The results suggest that GPT-4 and Claude 3, potentially due to their superior comprehension capabilities, benefit most from the inclusion of supplementary information.

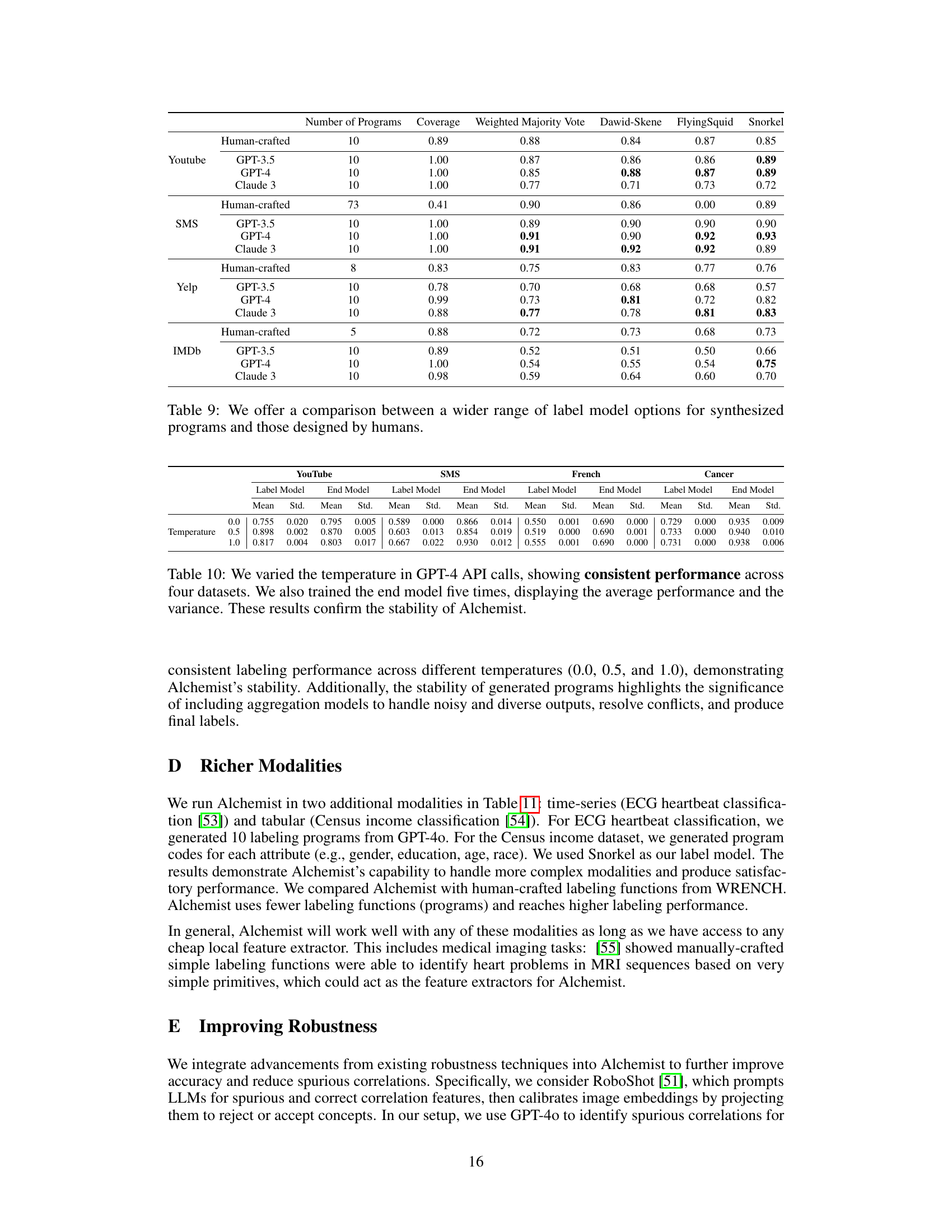
This table compares the performance of Alchemist’s synthesized programs against human-crafted programs in terms of accuracy and coverage for four different datasets (YouTube, SMS, Yelp, and IMDb). It highlights that Alchemist, using a significantly smaller number of generated programs (10 compared to 73 for human-crafted in the SMS dataset), achieves comparable or better results. The ‘Coverage’ metric indicates the proportion of the dataset that can be labeled, while ‘Performance’ likely represents accuracy (F1-score or similar). The table demonstrates Alchemist’s cost-effectiveness and efficiency in data annotation.

This table presents the accuracy and estimated cost of using both zero-shot prompting and Alchemist with GPT-3.5 for different datasets. The cost reflects the number of tokens processed, highlighting Alchemist’s significant cost reduction. The accuracy demonstrates Alchemist’s comparable or superior performance to zero-shot prompting.

This table presents the results of the experiments conducted to evaluate the performance of the distilled model on various datasets. For each dataset and method (zero-shot prompting and Alchemist with GPT-3.5), the estimated cost and accuracy (or F1-score) are shown. The cost is estimated based on the number of tokens processed by GPT-3.5, highlighting the cost savings achieved by the Alchemist method.

This table presents the results of the experiments comparing the performance of the distilled model (using Alchemist) against the zero-shot prompting baseline across eight different datasets. It shows the estimated cost (based on GPT-3.5 pricing) and accuracy (or F1-score for SMS) achieved by each method on each dataset. The table highlights the significant cost reduction achieved by Alchemist while maintaining comparable or even improved performance compared to the baseline.
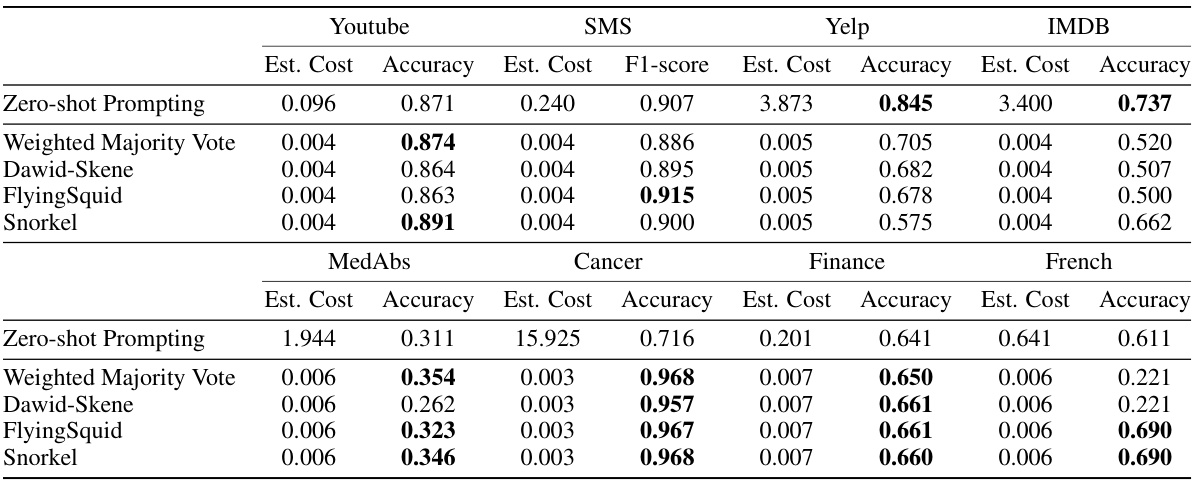
This table presents the results of the distilled model’s performance on eight different datasets using two different methods: zero-shot prompting and Alchemist with GPT-3.5. The accuracy, F1-score (for relevant datasets), and estimated cost are shown for each combination. The cost estimates are based on the GPT-3.5 pricing, indicating that Alchemist offers significant cost savings compared to zero-shot prompting, especially when using more expensive models.

This table presents the results of the distilled model’s performance on eight different datasets using two methods: zero-shot prompting and Alchemist with GPT-3.5. For each dataset and method, the estimated cost and accuracy are shown. The estimated cost is calculated based on the number of tokens used in GPT-3.5 API calls. The results highlight Alchemist’s cost-effectiveness and improved accuracy in several datasets compared to the zero-shot prompting approach.

This table presents the results of the experiments comparing the performance of the distilled model using Alchemist with the baseline method of zero-shot prompting for eight different datasets across four language tasks. For each dataset and method, the estimated cost and accuracy (or F1-score) are shown. The cost is calculated based on the number of tokens processed by GPT-3.5, highlighting the significant cost reduction achieved by Alchemist.
This table shows the accuracy and estimated cost of using Alchemist with GPT-3.5 compared to zero-shot prompting for various text classification tasks. The cost reflects the API calls needed; Alchemist significantly reduces the cost by generating programs to label data instead of directly querying models for each data point. Accuracies are reported for a distilled model trained on pseudolabels created using the generated programs.
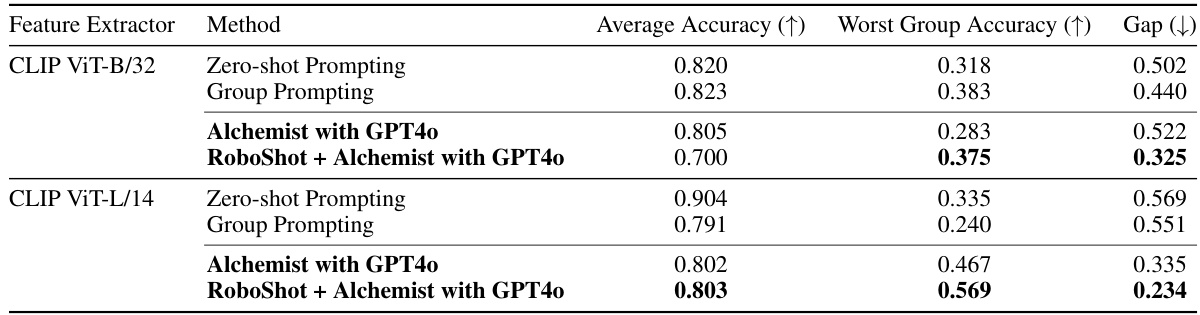
This table presents the results of experiments evaluating Alchemist’s performance on non-text modalities, specifically using image data. Three different methods are compared: the standard Alchemist approach, an extension of Alchemist incorporating CLIP-based local feature extractors, and CLIP prompting baselines. The table shows the average accuracy, worst-group accuracy (accuracy on the group with the lowest accuracy), and the gap between these two metrics for each method. The results demonstrate that while Alchemist’s average accuracy is comparable to the baselines, its extension significantly improves robustness by reducing the gap between average and worst-group accuracy, indicating better handling of potentially problematic data.
Full paper#