↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current image generation and editing methods struggle with complex tasks, lack self-correction, and often specialize in specific areas. This leads to unreliable results and limits their practical applications. A single model is often insufficient to fulfill diverse user requirements.
GenArtist overcomes these limitations by using a multimodal large language model (MLLM) as an intelligent agent. This agent orchestrates a collection of existing models, breaking down complex requests into simpler steps, planning the process, and incorporating verification and self-correction. The results demonstrate that GenArtist achieves state-of-the-art performance across various generation and editing tasks, surpassing existing models like SDXL and DALL-E 3. The system’s unified approach and ability to handle complex instructions significantly advance AI image manipulation capabilities.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel unified image generation and editing system, addressing limitations of existing models. GenArtist’s agent-based approach and ability to handle complex tasks make it highly relevant to current research in AI, particularly in multimodal learning and large language models. Its success opens avenues for creating more versatile and reliable AI systems for image manipulation.
Visual Insights#

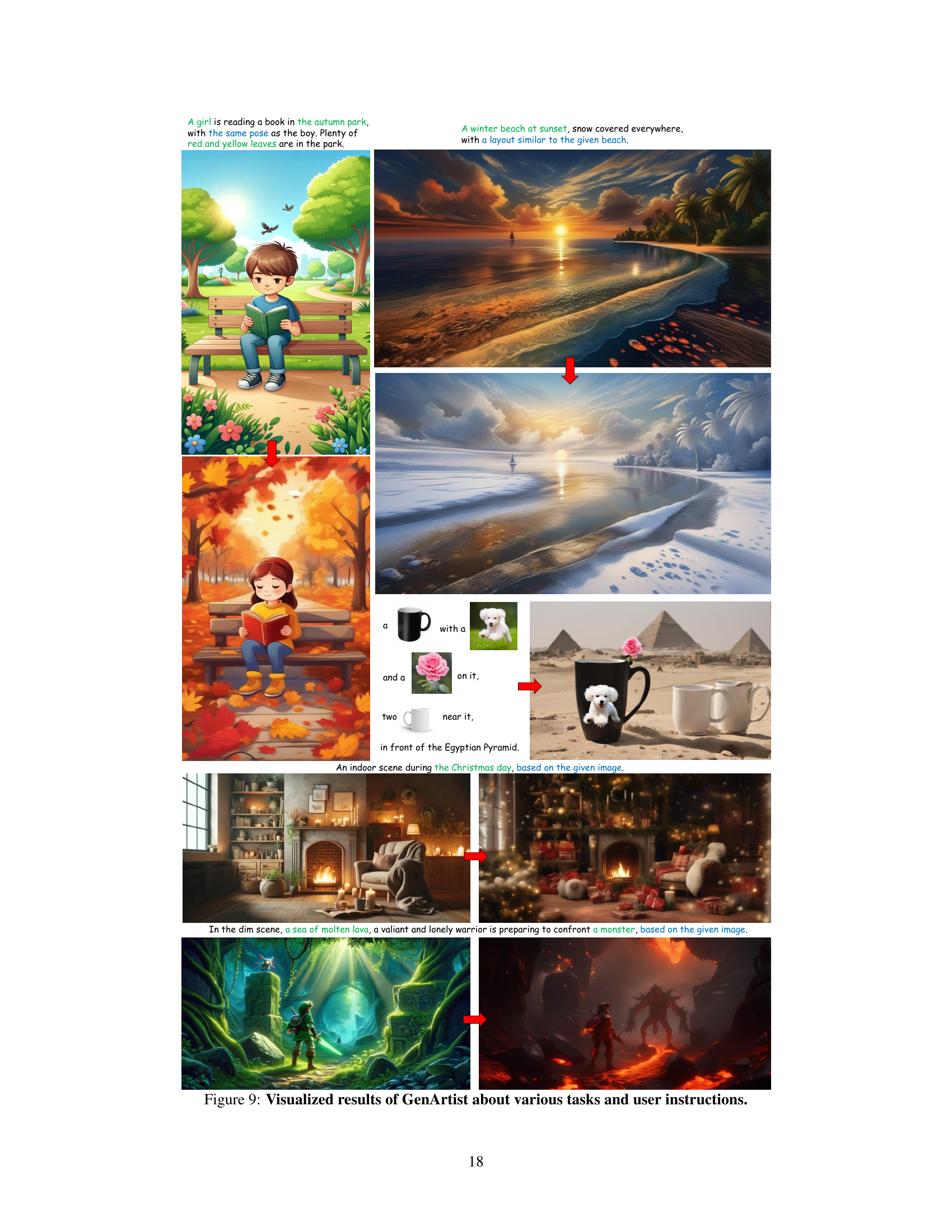
This figure shows several examples of images generated and edited by GenArtist, highlighting its ability to perform both tasks effectively and accurately. The examples demonstrate GenArtist’s superior performance compared to existing models (SDXL and DALL-E 3) in text-to-image generation and its ability to handle complex image editing tasks.
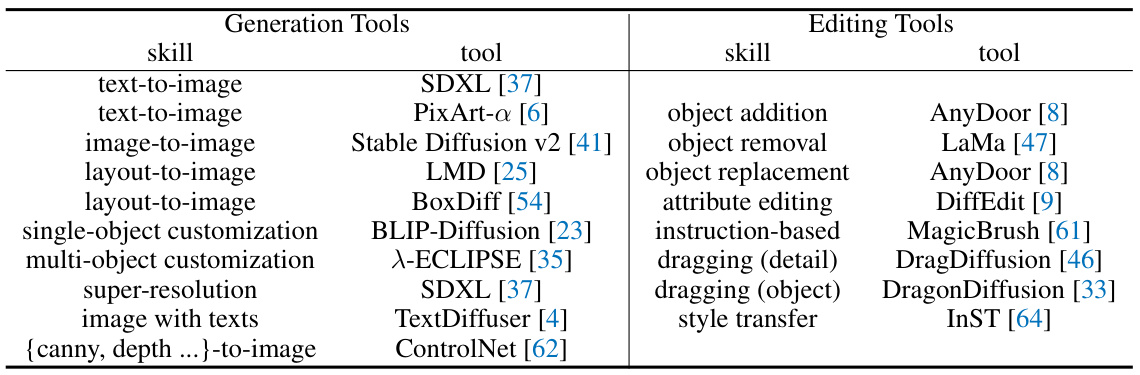
This table lists the various tools integrated into the GenArtist system, categorized into generation and editing tools. Each tool is specified by its skill (e.g., text-to-image, object addition) and the specific model used to implement that skill (e.g., SDXL, LaMa). The table shows the breadth of functionalities covered by GenArtist, emphasizing its capacity for diverse image generation and manipulation tasks.
In-depth insights#
Unified Image Editing#
Unified image editing represents a significant advancement in AI-powered image manipulation. Instead of relying on separate, specialized models for different editing tasks (e.g., inpainting, object removal, style transfer), a unified approach aims to integrate these capabilities into a single, versatile system. This offers several key advantages. First, it simplifies the user experience by providing a consistent interface for all editing needs. Second, it potentially allows for more complex, multi-step edits to be performed seamlessly within the same framework. Third, a unified model could learn synergistic relationships between different editing operations, leading to improved overall editing quality and more creative possibilities. However, challenges remain. Building such a system requires careful consideration of model architecture, training data, and computational resources. Balancing the efficiency and versatility of a unified model with its potential complexity is a crucial design consideration. Furthermore, the robustness of the system in handling diverse and unexpected inputs must be carefully evaluated. Despite these challenges, the potential benefits of unified image editing are substantial, paving the way for more intuitive and powerful image manipulation tools in the future.
MLLM Agent Control#
Employing a Multimodal Large Language Model (MLLM) as an agent for controlling image generation and editing presents a compelling approach to unify these tasks. The agent acts as a central orchestrator, breaking down complex user requests into smaller, manageable sub-problems. This decomposition allows the agent to select and sequence appropriate tools from a library of specialized models, each designed for specific generation or editing operations. A key advantage is the creation of a dynamic planning tree, enabling the agent to adapt its strategy in response to intermediate results. The incorporation of verification and self-correction mechanisms significantly improves the reliability and accuracy of the final outputs. Position-aware tool execution is crucial, addressing the limitation of MLLMs in providing precise spatial information. Auxiliary tools automatically generate missing positional inputs needed by many tools, enhancing the precision of manipulation. Although this approach promises a significant advance, challenges remain in terms of efficient tool selection from a large library and ensuring the robustness of the entire system against potential tool failures. The system’s performance heavily relies on the underlying MLLM’s capabilities, creating a dependency that could limit its adaptability and generalizability.
Position-Aware Tools#
The concept of ‘Position-Aware Tools’ in the context of a multimodal image generation and editing system is crucial. It addresses a significant limitation of many existing models: the inability to precisely manipulate objects within an image based on natural language instructions. Many models struggle with incorporating spatial information, relying on implicit cues or requiring meticulous manual specification of coordinates. Position-aware tools directly tackle this by incorporating object detection or segmentation models, which identify the location and extent of objects within the image. This information then informs the operations performed by subsequent editing or generation tools, ensuring accurate and contextually relevant modifications. This positional awareness is particularly important for complex tasks involving multiple objects and intricate spatial relationships. For example, accurately moving an object ’to the left of the tree’ requires not only identifying the object but also precisely determining the spatial context. A unified system utilizing these tools, therefore, offers a significant advancement over previous approaches. The system can intelligently choose the most appropriate tool based on both user instructions and the positional information provided by these preliminary steps. This improves accuracy, efficiency and usability of the whole image editing process.
Planning Tree Method#
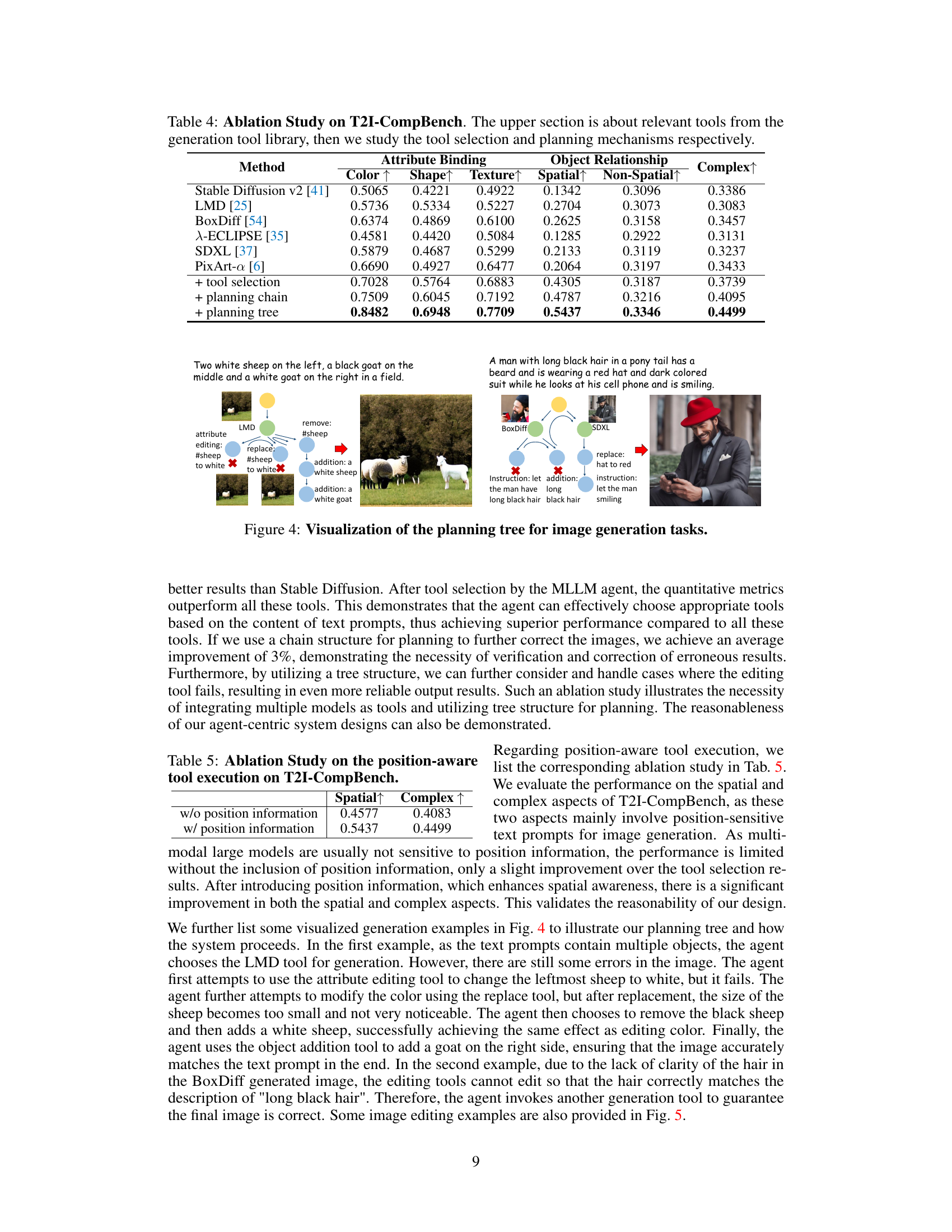
A planning tree method offers a structured approach to complex AI tasks, particularly in image generation and editing. The core idea is to decompose a complex request into smaller, manageable sub-tasks, represented as nodes in a tree. This hierarchical decomposition simplifies problem-solving, enabling the AI agent to address each sub-task sequentially. The tree structure facilitates step-by-step verification, ensuring that each sub-task is successfully completed before moving to the next. This iterative verification significantly improves the reliability of the overall process. Furthermore, the use of a tree allows for exploring multiple solution paths for a given sub-task, represented as branches. This offers flexibility and robustness, allowing the system to recover from failures in one branch by exploring alternatives. The planning tree method, therefore, provides a principled way to manage complexity in AI applications that require multi-step operations, enhancing accuracy, reliability, and efficiency.
Future Work: Scaling#
Future work in scaling multimodal large language models (MLLMs) for unified image generation and editing, like GenArtist, should prioritize several key areas. Improving the efficiency of the MLLM agent is crucial; current agents may be computationally expensive for complex tasks. Exploring more efficient tool integration methods would enhance scalability. This could involve optimizing tool selection and execution or developing specialized tools for specific sub-tasks. Addressing the scalability of the tool library itself is essential; expanding the library while maintaining performance requires careful planning and efficient architecture. Finally, developing robust and scalable self-correction mechanisms is vital for reliable and high-quality results as complexity increases. Research into novel verification methods and strategies for automatically correcting errors will improve output across the board. Efficient parallel processing techniques will also be important to handle increasingly large-scale image data and complex prompts.
More visual insights#
More on figures

This figure shows examples of text-to-image generation and image editing tasks performed by GenArtist. The top row demonstrates the system’s ability to generate images from complex text descriptions, outperforming existing models in terms of accuracy and detail. The bottom rows show the system’s image editing capabilities, highlighting its ability to handle complex multi-step edits. The examples illustrate the unified nature of the system, seamlessly handling both generation and editing tasks.

This figure showcases several examples of GenArtist’s capabilities in both image generation and editing. The top row demonstrates text-to-image generation, highlighting GenArtist’s superior accuracy compared to existing models (SDXL and DALL-E 3) by showing the results of each model side-by-side for the same prompt. The bottom rows display GenArtist’s ability to handle complex image editing tasks, including multi-round interactive generation and complex edits involving object removal and style changes.

This figure presents a schematic overview of the GenArtist system architecture. The multimodal large language model (MLLM) agent is central; it acts as a coordinator, breaking down complex user requests into simpler sub-tasks. This decomposition is shown at the left of the figure. The agent then uses a planning tree (shown in the center) to systematically approach the task, verifying the results of each step. The process utilizes three main tool libraries: a generation tool library, an auxiliary tool library (providing missing positional information), and an editing tool library. The output of the plan shows a position-aware tool execution on the right side, ensuring that the correct tools are used for each step and any positional requirements are met. The final result is a unified image generation and editing system.

This figure illustrates the structure of the planning tree used in GenArtist. The tree is a hierarchical structure, starting with an initial node representing the user’s input. The tree branches into generation nodes that represent different tools for generating the image, and then into editing nodes that represent operations used for self-correction. The use of a tree structure allows for a systematic approach to image generation and editing, ensuring that the final result accurately reflects the user’s intent.

This figure showcases various examples of GenArtist’s capabilities in both image generation and editing. The top row demonstrates text-to-image generation, comparing GenArtist’s output to those of SDXL and DALL-E 3 for complex prompts. GenArtist’s results show improved accuracy. The bottom rows illustrate complex image editing tasks successfully performed by GenArtist, highlighting its ability to handle multiple edits and nuanced instructions more effectively than other models.

This figure showcases various examples of image generation and editing tasks performed by the GenArtist model. The examples demonstrate its ability to handle complex text prompts for image generation, resulting in higher accuracy than existing models like SDXL and DALL-E 3. It also shows GenArtist successfully completing complex multi-step image editing tasks.

This figure showcases GenArtist’s capabilities in both text-to-image generation and image editing. It presents several examples, comparing GenArtist’s output to those of SDXL and DALL-E 3 for text-to-image tasks, highlighting GenArtist’s superior accuracy. It also demonstrates GenArtist’s ability to handle complex image editing tasks, exceeding the performance of other models.

This figure showcases various examples of GenArtist’s capabilities in both image generation and editing. It demonstrates GenArtist’s ability to handle complex text prompts for image generation, surpassing the performance of existing state-of-the-art models like SDXL and DALL-E 3. Furthermore, the figure presents examples of intricate image editing tasks, highlighting GenArtist’s ability to effectively combine and sequence multiple editing operations to achieve complex results.

This figure showcases example outputs from the GenArtist model, demonstrating its capability in both image generation and editing tasks. It compares the model’s performance against existing state-of-the-art models, such as SDXL and DALL-E 3, highlighting its improved accuracy in text-to-image generation and superior performance in complex image editing scenarios. The examples show diverse tasks, ranging from generating images from complex text descriptions to performing intricate multi-step image edits.

This figure shows the architecture of GenArtist, a unified image generation and editing system. A multimodal large language model (MLLM) acts as the central agent, responsible for task decomposition, planning (using a tree structure), and tool selection and execution. The system integrates multiple tools for generation and editing, leveraging the agent’s intelligence to choose the most appropriate tool for each sub-task. This allows for complex and multifaceted image manipulation.

This figure visualizes the step-by-step process of image editing using GenArtist. The example shows how the MLLM agent handles complex instructions by breaking them down into smaller steps. It uses multiple tools (e.g., LaMa, Diffedit, MagicBrush, AnyDoor) sequentially. The process shows verification and correction at each step, to ensure the final output meets the requirements.
More on tables
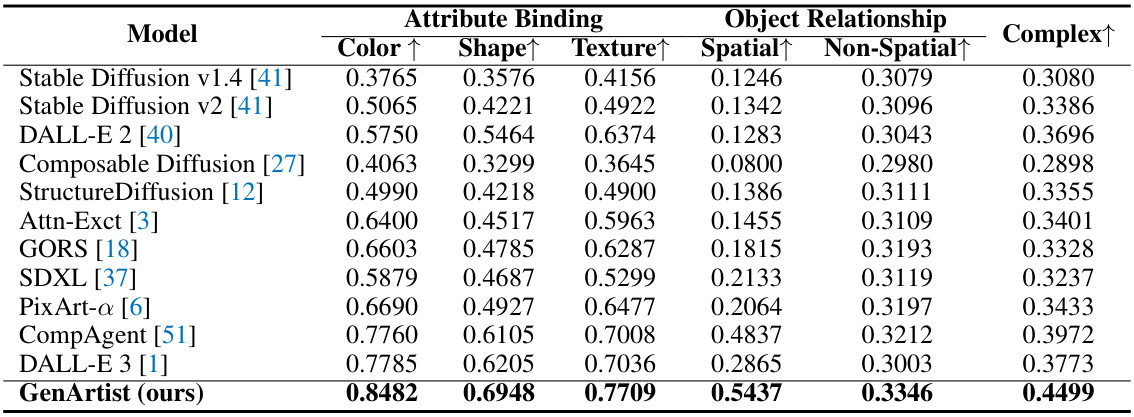
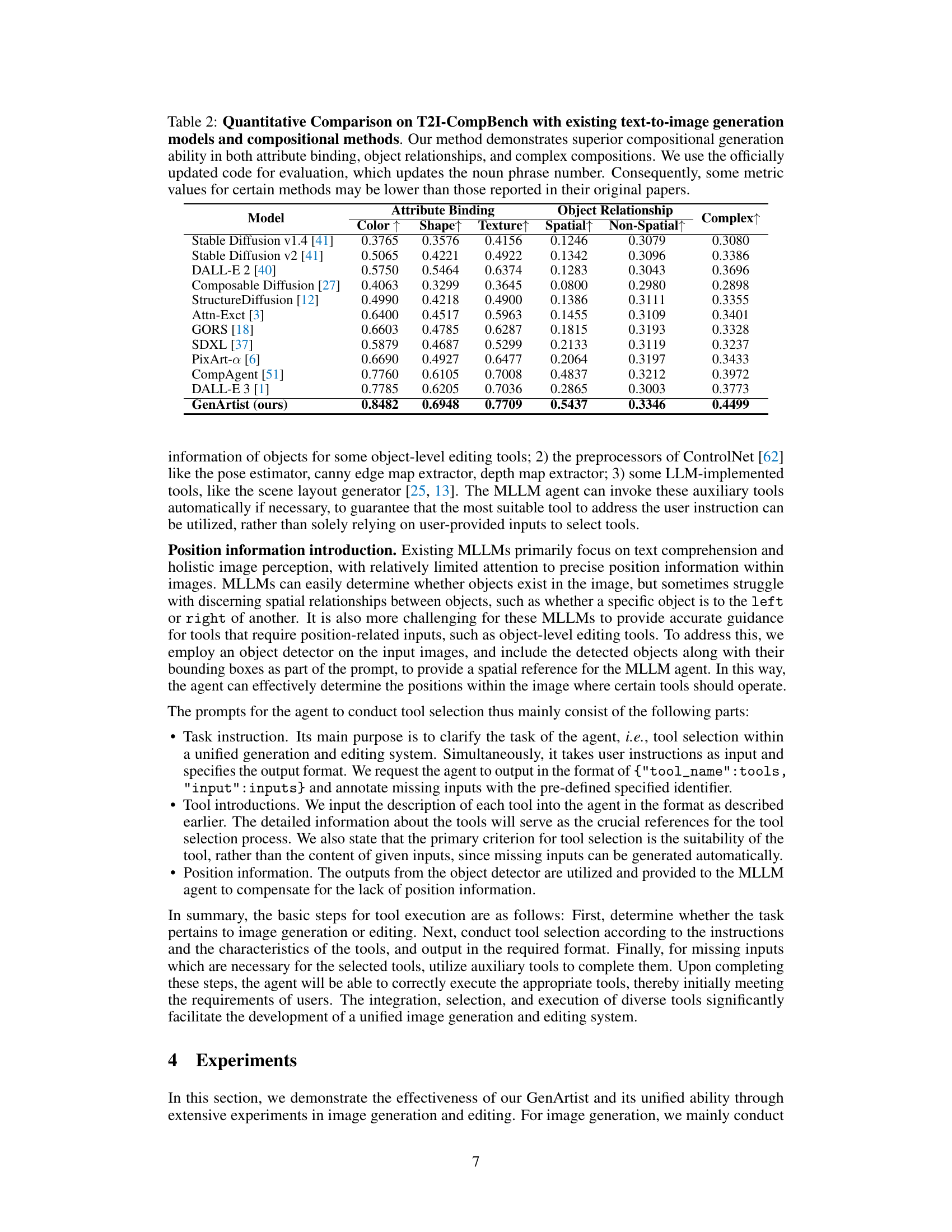
This table presents a quantitative comparison of GenArtist with other state-of-the-art text-to-image generation models on the T2I-CompBench benchmark. It evaluates performance across three key aspects: Attribute Binding (how well the model associates attributes like color and shape with objects), Object Relationship (how well the model understands spatial relationships between objects), and Complex Composition (how well the model handles complex scenes with multiple objects and attributes). The results show that GenArtist significantly outperforms existing models in all three areas, demonstrating its superior ability to generate images that accurately reflect complex textual descriptions.
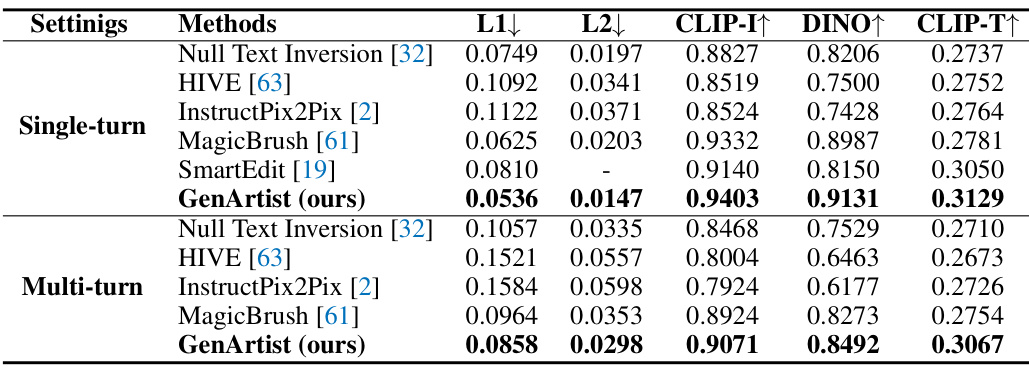
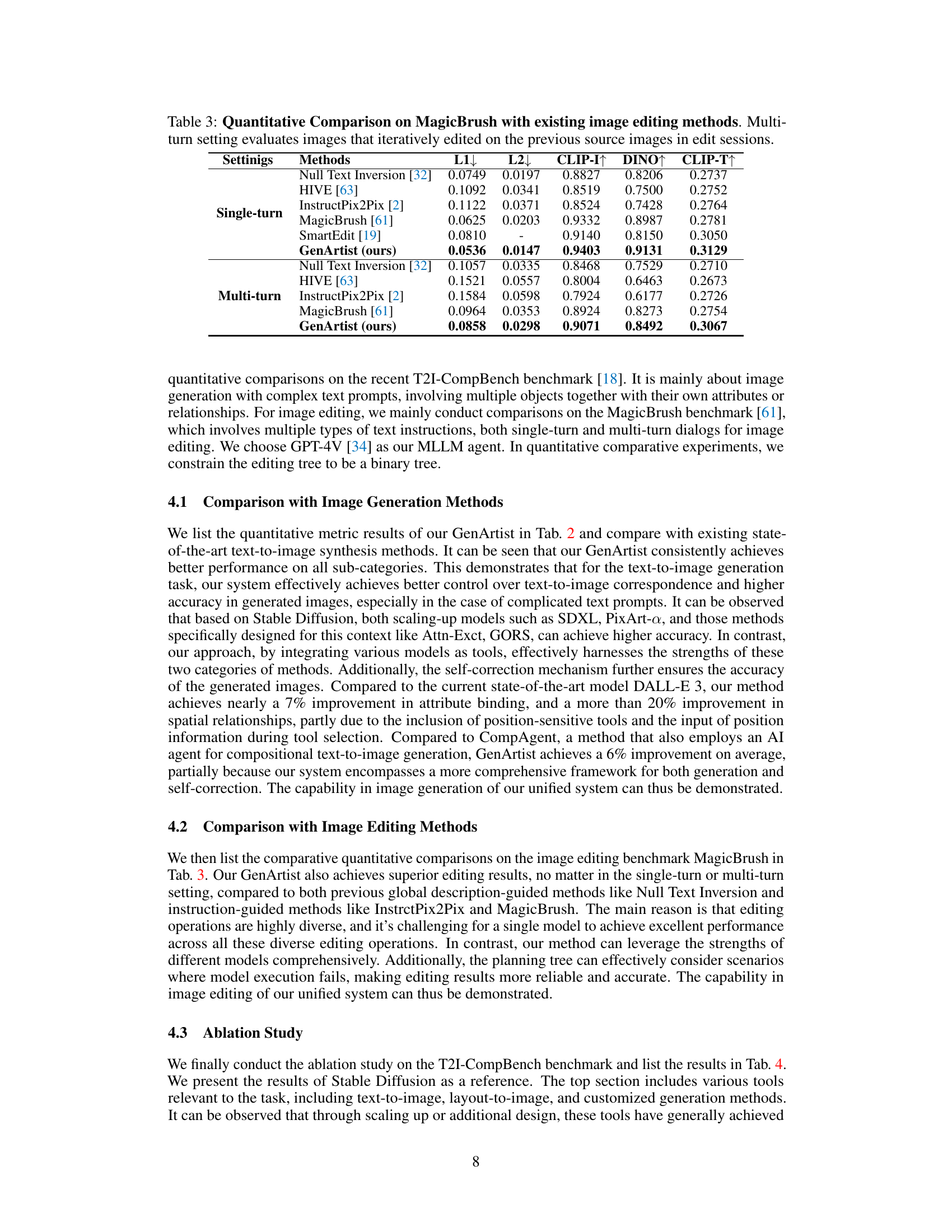
This table presents a quantitative comparison of GenArtist against other state-of-the-art image editing methods on the MagicBrush benchmark. The comparison considers two settings: single-turn (one edit session) and multi-turn (multiple edit sessions). Metrics used are L1 loss, L2 loss, CLIP-I (Image-level CLIP score), DINO (DINO-v2 score), and CLIP-T (text-level CLIP score). Lower L1 and L2 loss values are better, while higher values for CLIP-I, DINO, and CLIP-T are better. The results show GenArtist’s performance relative to other methods across different metrics and editing scenarios.
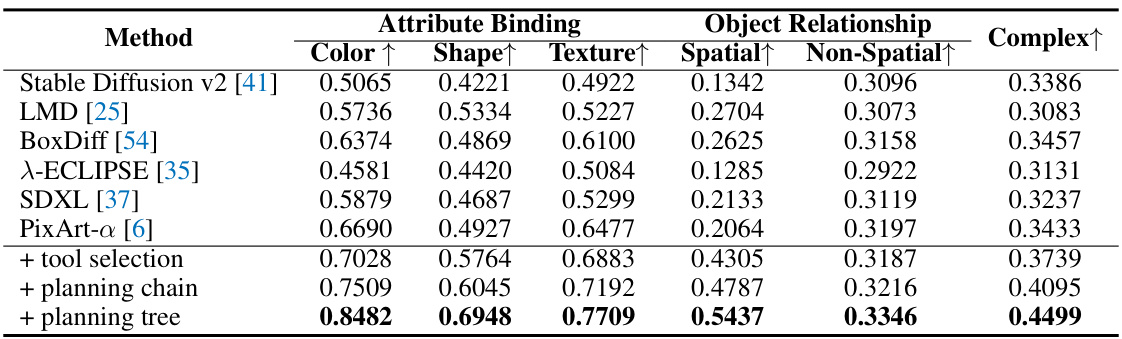
This table presents the ablation study conducted on the T2I-CompBench benchmark. It compares the performance of different model configurations, focusing on the impact of tool selection and planning strategies. The upper part shows the results obtained using individual tools from the generation tool library. The lower part demonstrates the performance improvements achieved by incorporating tool selection, planning with chains, and finally the complete planning tree. The metrics used are Attribute Binding (Color, Shape, Texture) and Object Relationship (Spatial, Non-Spatial, Complex). The results highlight the significant performance gains achieved through the proposed multi-step planning and tool selection approach.

This table presents the ablation study conducted on the T2I-CompBench benchmark to analyze the impact of different components of GenArtist on the performance. It examines the contribution of specific tools from the generation tool library, tool selection strategies, and planning mechanisms (chain vs. tree). The results are presented in terms of the quantitative metrics (Attribute Binding, Object Relationship) which are further broken down into sub-metrics (Color, Shape, Texture, Spatial, Non-Spatial, Complex) for a detailed analysis of the model’s performance.

This table presents a quantitative comparison of GenArtist with other state-of-the-art text-to-image generation models and compositional methods on the T2I-CompBench benchmark. It uses the older version of the evaluation code, which may result in slightly different scores compared to the most recent results, and focuses on evaluating the model’s performance in terms of attribute binding, and object relationships (spatial and non-spatial), and in handling complex compositions. The metrics used are Color, Shape, Texture, Spatial, Non-Spatial, and Complex, all on a scale from 0 to 1, where higher numbers mean better performance.
Full paper#