↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Dataset distillation aims to replace large datasets with smaller, representative synthetic ones, lowering costs and improving efficiency. However, existing methods often struggle to generate truly diverse synthetic data, impacting model performance. This limits the benefit of the approach, as homogenous synthetic datasets do not effectively represent the original dataset’s variability.
The proposed method, Diversity-Driven Synthesis, addresses this by using dynamic and directed weight adjustment techniques during the synthesis process. This ensures that each batch of synthetic data reflects the characteristics of a large, diverse subset of the original data. The method significantly enhances diversity and representativeness. Experiments across various datasets showcase that the method achieves superior performance with minimal computational overhead.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers dealing with large datasets. It offers a computationally efficient method to improve dataset distillation, a critical area for reducing data storage and processing costs. Its findings open new avenues for research in synthesizing diverse and representative datasets, benefiting various machine learning applications.
Visual Insights#

The figure consists of two parts. The left part shows the t-SNE visualization of the logit embeddings on the CIFAR-100 dataset. It compares the distribution of synthetic data instances generated by SRe2L and the proposed DWA method. The DWA method shows a more diverse and widespread distribution, suggesting better generalization. The right part presents a bar chart comparing the performance improvement achieved by the DWA method across three different datasets (Tiny-ImageNet, ImageNet-1K, and CIFAR-100), demonstrating its superior performance.

This table presents a comparison of the proposed DWA method against several state-of-the-art (SOTA) dataset distillation methods on the CIFAR-10 and CIFAR-100 datasets. The table shows the top-1 accuracy achieved by models trained on the synthetic datasets generated by each method, using different numbers of images per class (ipc). The results highlight DWA’s superior performance compared to existing methods, particularly when using the larger ResNet-18 model.
In-depth insights#
Diversity-Driven Synthesis#
The concept of “Diversity-Driven Synthesis” in the context of dataset distillation focuses on generating synthetic datasets that are both representative of the original data and internally diverse. Diversity is crucial because homogeneous synthetic datasets may hinder the generalization ability of models trained on them, leading to poor performance on unseen data. The core idea is to actively modulate the synthesis process to maximize the variability of generated instances. This can involve techniques like dynamic weight adjustments, carefully designed perturbation mechanisms, or other methods to ensure each synthetic sample captures unique characteristics or features. Achieving this balance between representativeness and diversity is a key challenge. The benefits are potentially significant: improved model performance with reduced computational cost due to smaller training sets, which is extremely valuable when dealing with large datasets and limited computational resources.
Directed Weight Tuning#
Directed weight tuning, in the context of dataset distillation, presents a novel approach to enhance the diversity and representativeness of synthetic datasets. Instead of relying solely on random weight perturbations, which can introduce noise and hinder performance, this technique strategically adjusts the weights of the teacher model. This adjustment is guided by a process that aims to maximize the variance of the synthetic data, thus promoting a wider range of features in the synthesized dataset. This directed approach contrasts with previous methods that treat synthetic instances in isolation, potentially improving the overall generalization ability of models trained on the distilled data. A key aspect is the decoupling of the mean and variance components of the Batch Normalization (BN) loss, focusing primarily on maximizing the variance to ensure diversity. By carefully modulating weight adjustments, the method seeks to generate a highly diverse, representative synthetic dataset while minimizing computational overhead, making it an efficient and effective way to improve the dataset distillation process.
Dataset Distillation#
Dataset distillation is a crucial technique in machine learning addressing the challenges of high data storage and processing costs. It aims to condense large datasets into smaller, representative synthetic datasets without significant performance loss in downstream tasks. This is achieved by generating synthetic data points that capture the essential features and distribution characteristics of the original data. The core of dataset distillation lies in creating a balance between representing the original data’s diversity and avoiding redundancy in the synthetic dataset. Methods employ various techniques, including gradient matching, trajectory matching, and distribution matching, each offering different tradeoffs between computational cost and data fidelity. The success of dataset distillation depends greatly on the selection of appropriate methods tailored to the specific dataset and task, as well as managing the balance between diversity and representativeness in synthesized data.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a proposed model. In this context, it would involve removing or modifying specific parts of the diversity-driven synthesis method, such as the dynamic weight adjustment or the decoupled variance regularization, to assess their impact on the overall performance. The results would reveal the relative importance of each component, clarifying whether they are essential for achieving high diversity in synthesized datasets and superior model performance. For example, removing the dynamic weight adjustment would reveal whether the static weight setting is sufficient or whether the dynamic adjustment significantly enhances the quality of synthetic data. Similarly, examining the decoupled variance regularization would quantify the contribution of variance enhancement in achieving diversity compared to the coupled mean and variance approach. The ablation study will therefore provide crucial insights into the design choices of the proposed method, offering a strong empirical justification for design decisions and demonstrating the effectiveness of the key contributions.
Future Work#
The paper’s exploration of dataset distillation offers exciting avenues for future research. One key area is improving the diversity of synthesized datasets, especially for large-scale datasets like ImageNet. While the proposed directed weight adjustment method enhances diversity, further investigation into more sophisticated techniques, perhaps incorporating generative models or advanced sampling strategies, could yield even better results. Another promising direction is exploring the application of dataset distillation to more complex tasks, such as continual learning or few-shot learning. The current experiments show promise, but more thorough investigation is needed to fully understand its potential and limitations in these challenging scenarios. Finally, the computational efficiency of the method, while impressive, could be further optimized, potentially by leveraging more efficient deep learning techniques or hardware acceleration. This would allow the application of dataset distillation to even larger and more complex datasets, broadening its impact on machine learning research.
More visual insights#
More on figures
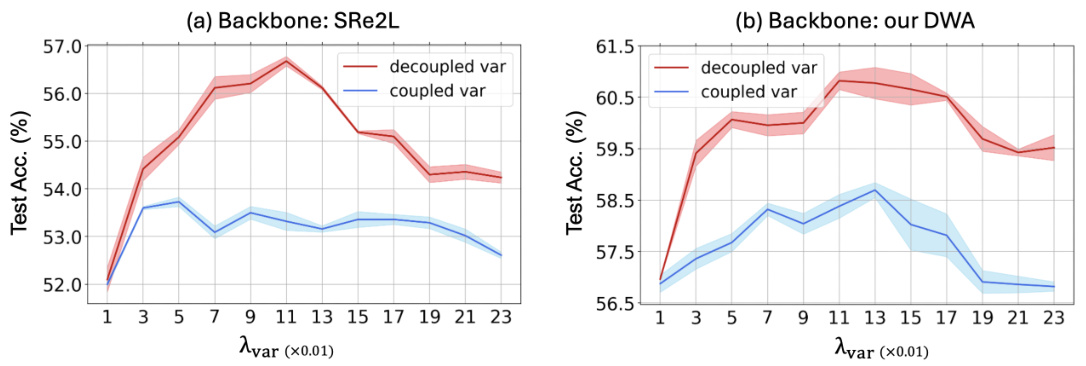
This figure analyzes the impact of the decoupled variance regularizer (Lvar) in the batch normalization (BN) loss on the diversity of synthesized datasets. It compares two approaches: (a) decoupled variance, where the variance regularizer is adjusted independently, and (b) coupled variance, where both mean and variance regularizers are adjusted simultaneously. The x-axis represents different values of the decoupled Lvar coefficient (Avar), while the y-axis shows the test accuracy achieved on CIFAR-100 using ResNet-18. The results demonstrate that adjusting the variance regularizer independently leads to better performance compared to adjusting it along with the mean regularizer, highlighting the importance of decoupling the two terms in enhancing diversity.
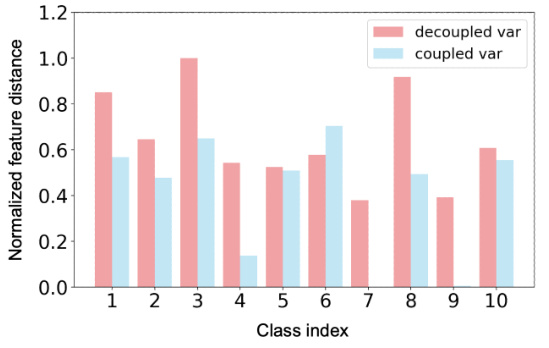
This figure compares the normalized feature distance between synthetic data instances generated using a decoupled variance coefficient (λvar = 0.11) against those generated with a coupled variance and mean coefficient (λBN = 0.11). The results illustrate the superior diversity achieved by the decoupled approach, showcasing that focusing solely on variance regularization, rather than jointly regularizing mean and variance, leads to more diverse synthetic data instances. The analysis is performed on the last convolutional layer’s outputs of ResNet-18, and the data is from ten randomly selected classes within the CIFAR-100 dataset. The graph visually represents the normalized distance for each class, emphasizing the difference in diversity obtained by each method.
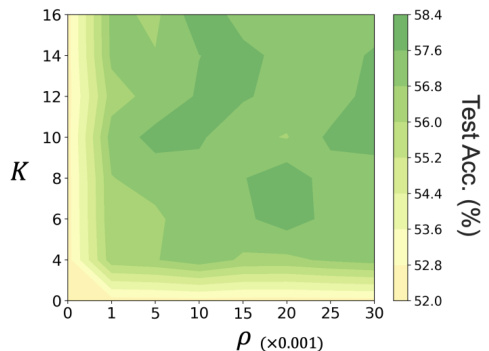
This figure shows a grid search on hyperparameters K (number of steps) and p (magnitude of perturbation) used in the gradient descent approach for solving Δθ. The heatmap displays the test accuracy achieved by ResNet-18 on CIFAR-100. Different color shades represent different test accuracies, ranging from approximately 52% to 58%. The optimal test accuracy seems to be achieved around K=12 and p=0.015.
More on tables
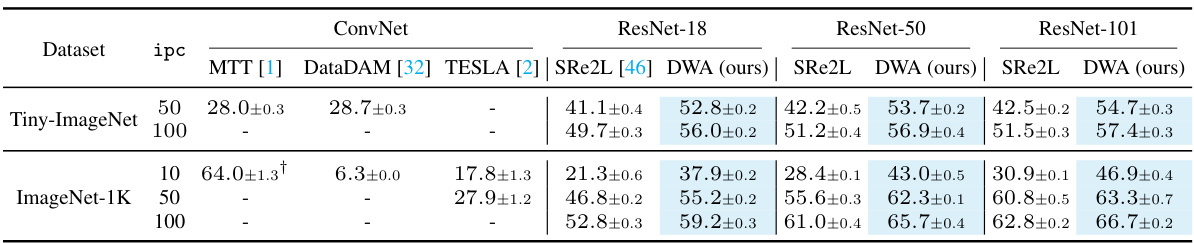
This table compares the performance of the proposed Diversity-Driven Weight Adjustment (DWA) method against other state-of-the-art (SOTA) dataset distillation methods on the Tiny-ImageNet and ImageNet-1K datasets. It shows the top-1 accuracy achieved by models trained on the synthetic datasets generated by each method, using different network architectures (ConvNet, ResNet-18, ResNet-50, ResNet-101) and varying numbers of images per class (ipc). The results highlight the superior performance of DWA, particularly on larger datasets and with more complex network architectures.

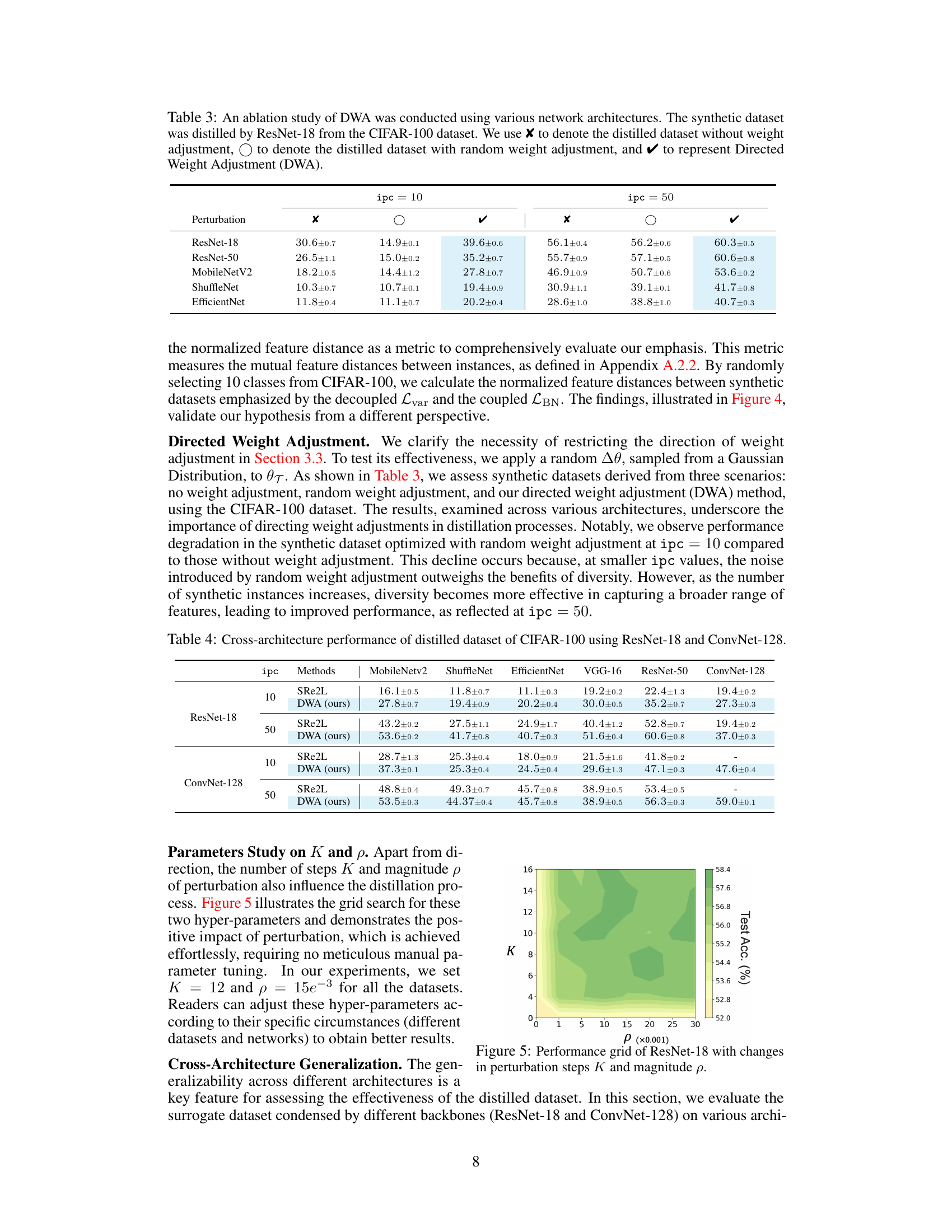
This ablation study evaluates the impact of different weight adjustment methods on the performance of dataset distillation using various network architectures. It compares the results of using no weight adjustment (X), random weight adjustment (○), and the proposed directed weight adjustment (DWA)(✓) method on the CIFAR-100 dataset with ResNet-18 as the backbone. The results are shown for different image-per-class (ipc) settings: 10 and 50.
This table compares the performance of the proposed DWA method against other state-of-the-art (SOTA) dataset distillation methods on Tiny-ImageNet and ImageNet-1K datasets. It shows the top-1 classification accuracy achieved using models trained on the synthesized datasets. The table highlights the superior performance of DWA, especially on the larger ImageNet-1K dataset, across different model sizes (ResNet-18, 50, and 101). The choice of backbone network for different methods is also specified.

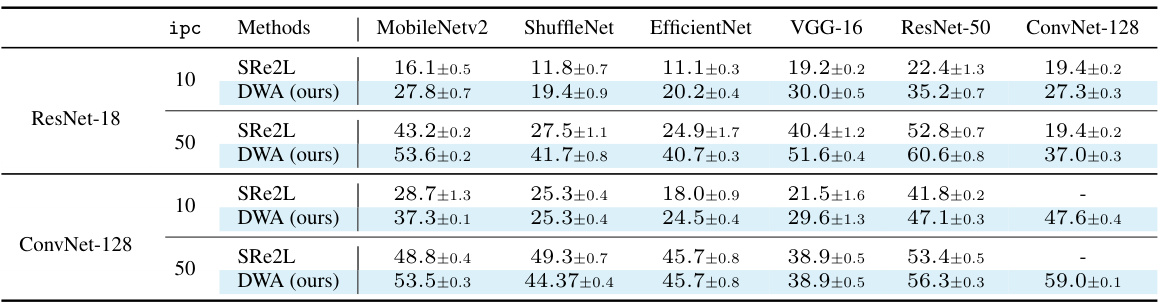
This table compares the performance of the proposed DWA method against state-of-the-art (SOTA) dataset distillation methods on Tiny-ImageNet and ImageNet-1K datasets. It shows the Top-1 classification accuracy achieved by models trained on the distilled datasets generated by each method. Different network architectures (ConvNet-128 and ResNet-18, 50, 101) are used for evaluation, highlighting the generalizability of the methods. Note that MTT results are based on a 10-class subset of ImageNet-1K.

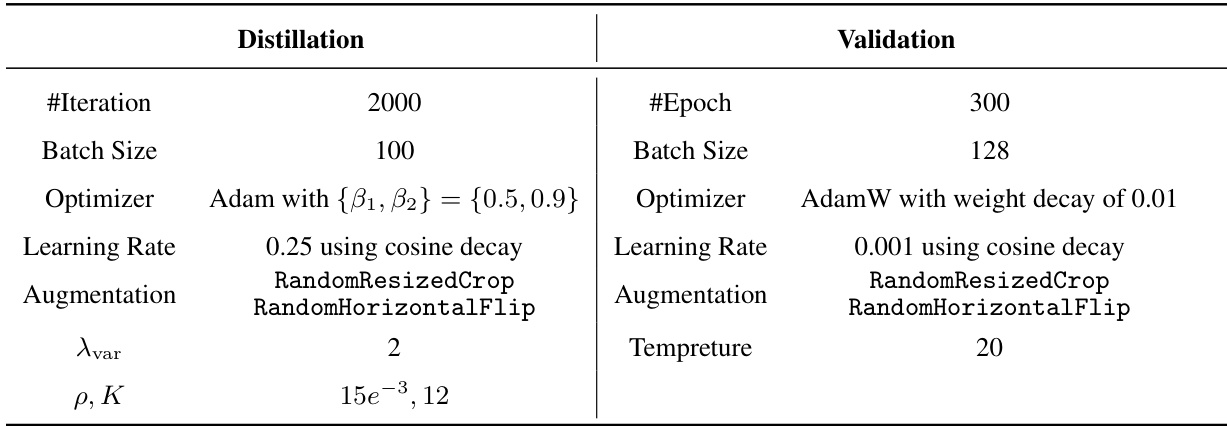
This table details the hyperparameters used for both the distillation and validation phases of the CIFAR-10/100 dataset experiments. For distillation, it shows the number of iterations, batch size, optimizer (Adam), learning rate (using cosine decay), and augmentation strategy. The validation settings similarly list the number of epochs, batch size, optimizer (AdamW with weight decay), learning rate (cosine decay), augmentation techniques (RandomCrop and RandomHorizontalFlip), and temperature. The table also specifies the values used for λvar (variance regularization strength), and the parameters ρ and K related to the directed weight adjustment method.
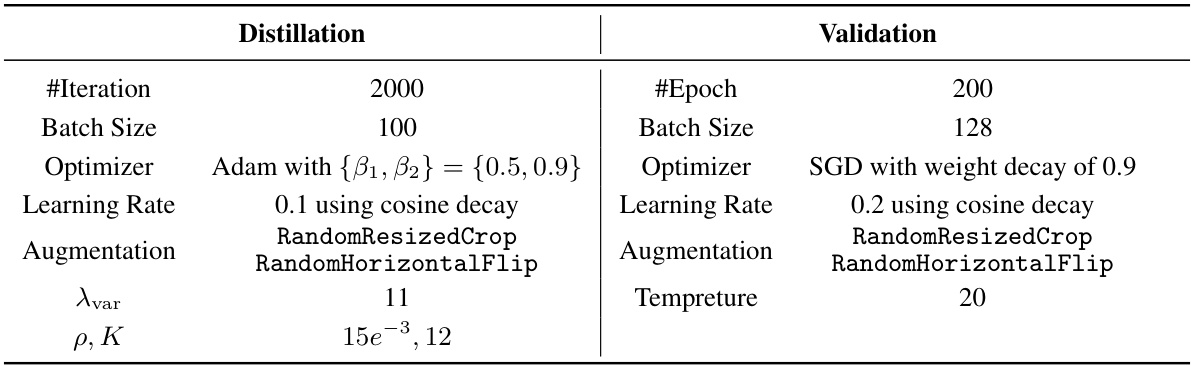
This table presents the hyperparameter settings used for both the distillation and validation phases of the Tiny-ImageNet experiments. It shows settings for the number of iterations/epochs, batch size, optimizer, learning rate, augmentation techniques, the decoupled variance coefficient (λ_var), and the parameters ρ and K used in the directed weight adjustment (DWA) method. These hyperparameters were crucial in fine-tuning the model’s performance for this specific dataset.
This table details the hyperparameters used during both the distillation and validation phases for the Tiny-ImageNet dataset. It specifies settings for the number of iterations, batch size, optimizer (Adam with beta1 and beta2 parameters), learning rate (using cosine decay), augmentations (random resized crop and random horizontal flip), the decoupled variance coefficient (λ_var), and the parameters ρ, k, and K used in the weight adjustment. The validation settings differ slightly, employing AdamW with weight decay and a different learning rate, while other settings like augmentation are kept the same.

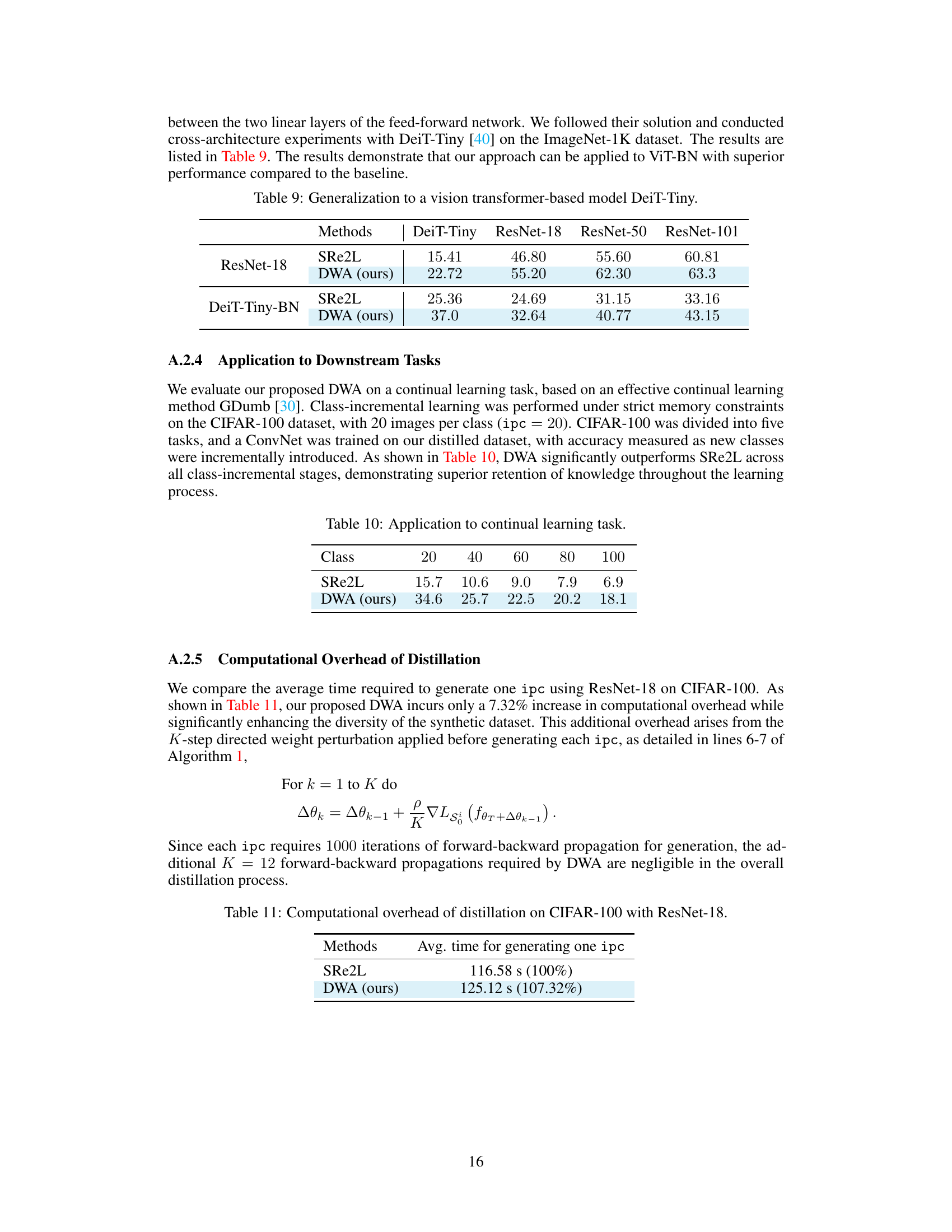
This table presents the results of generalizing the proposed DWA method to a vision transformer-based model, DeiT-Tiny. It compares the performance of DWA and the baseline method, SRe2L, when using different backbone networks (ResNet-18, ResNet-50, and ResNet-101) for the ImageNet-1K dataset. The table demonstrates the superior performance of DWA across different architectures.

This table presents the results of applying the proposed DWA method and the baseline SRe2L method to a continual learning task using the CIFAR-100 dataset. The dataset is divided into five tasks, each with 20 images per class. The table shows the accuracy achieved at each stage of the continual learning process, demonstrating the superior performance of the DWA method in retaining knowledge across tasks.

This table compares the performance of the proposed DWA method against other state-of-the-art (SOTA) dataset distillation methods on CIFAR-10 and CIFAR-100 datasets. It shows the top-1 accuracy achieved by models trained on the synthetic datasets generated by each method. Different image-per-class (ipc) settings are used for a comprehensive evaluation, and the table notes the network architecture used for each method.
Full paper#