↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Motion retargeting, transferring animations between characters, is crucial in fields like gaming and VR. Existing methods often fall short, failing to accurately capture and maintain the complex geometric interactions between body parts, leading to issues like mesh interpenetration and unnatural movements. This is particularly challenging with characters with diverse body shapes, and the existing methods are often computationally expensive and produce suboptimal results.
The proposed MeshRet framework tackles this problem by directly modeling dense geometric interactions. It introduces Semantically Consistent Sensors (SCS) to establish mesh correspondences and a novel Dense Mesh Interaction (DMI) field to represent these interactions effectively. MeshRet’s single-pass approach avoids the conflicts inherent in multi-stage methods, and experiments show that it achieves state-of-the-art performance in terms of accuracy and realism, especially regarding contact preservation and reduced interpenetration.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in computer graphics: realistic motion retargeting for skinned characters. Current methods often struggle with maintaining accurate geometric interactions between body parts, leading to unnatural results. This research presents a novel framework that directly models these interactions, resulting in significantly improved realism and potentially impacting various applications like virtual reality and game development.
Visual Insights#
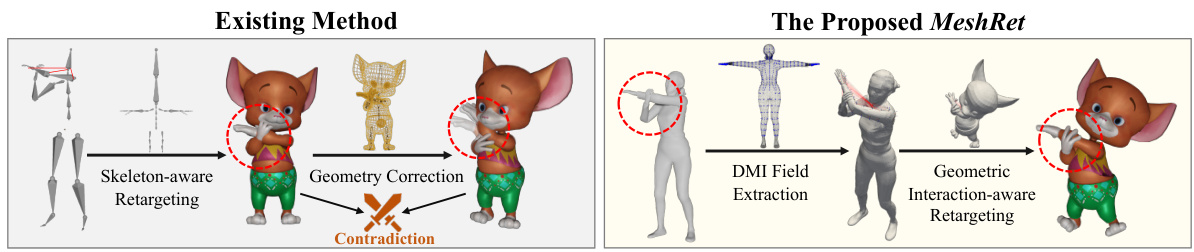
This figure compares the proposed MeshRet method with existing methods for skinned motion retargeting. Existing methods typically involve a two-stage process: first, skeleton-aware retargeting, then geometry correction. However, these stages often conflict, resulting in issues such as mesh interpenetration, jittery motion, and inaccurate contact representation. In contrast, MeshRet directly models dense geometric interactions using a Dense Mesh Interaction (DMI) field, eliminating these conflicts and improving the accuracy of retargeted motion.

This table compares the performance of the proposed MeshRet method against several existing methods (Copy, PMnet [15], SAN [1], R2ET [32]) across different metrics: MSE (Mean Squared Error) for joint position accuracy, both globally and locally, contact error representing the accuracy of contact preservation, and penetration ratio indicating the level of mesh interpenetration. The evaluation is performed on two datasets: ScanRet (a new dataset introduced in the paper), and Mixamo+ (a combination of Mixamo and ScanRet datasets). Lower values are better for all metrics. The results show that MeshRet significantly outperforms existing methods across both datasets and various metrics.
In-depth insights#
Dense Mesh Retargeting#
Dense mesh retargeting presents a significant advancement in character animation, moving beyond skeletal methods to directly model and preserve geometric interactions during motion transfer. This approach is crucial because it addresses limitations of traditional techniques that often result in artifacts like mesh interpenetration, jittering, and inaccurate contact. By focusing on dense mesh correspondences and the interactions between mesh elements, this method promises more natural and realistic motion retargeting across diverse character models. Semantic Consistent Sensors (SCS), a key innovation, enables robust correspondence establishment even with varying mesh topologies. The Dense Mesh Interaction (DMI) field further enhances the method’s capability by encoding both contact and non-contact interactions, providing a comprehensive representation of geometric relationships. This allows for the preservation of subtle nuances in movement that would otherwise be lost in simpler retargeting approaches. The result is a technique with the potential to greatly enhance the quality and realism of character animation in various applications.
SCS & DMI Field#
The effectiveness of the proposed method hinges on its ability to accurately capture and model dense geometric interactions between different body parts of a character. This is achieved through two key components: Semantically Consistent Sensors (SCS) and the Dense Mesh Interaction (DMI) field. SCS establishes dense mesh correspondences across diverse character meshes, which is crucial for transferring motion. Unlike traditional approaches relying on vertex-based or skeletal correspondences that are topology dependent, SCS leverages semantic coordinates derived from skeleton bones to define dense mesh correspondences, making the method robust to various mesh topologies. Building upon this dense correspondence, the DMI field serves as a novel spatio-temporal representation skillfully capturing both contact and non-contact interactions. By encoding these interactions as pairwise features between sensors derived from SCS, the DMI field provides a rich representation for training a network to directly retarget motion while preserving intricate geometric interactions. This direct modeling, in contrast to traditional methods that involve separate skeletal retargeting and geometry correction stages, effectively eliminates inconsistencies and artifacts, thereby resulting in improved motion quality.
Geometric Interaction#
The concept of geometric interaction in the context of skinned character animation is crucial for achieving realistic and believable motion. It refers to the accurate modeling and preservation of the spatial relationships and contact between different body parts of a character. Simply animating a skeleton isn’t sufficient; the surface geometry must also correctly interact, preventing self-interpenetration and accurately simulating collisions and contacts. Ignoring or inadequately addressing geometric interactions often results in artifacts like jittery movements, mesh interpenetration, and inaccurate contact representations. Approaches that focus on skeletal motion retargeting alone often fail to capture these subtleties, necessitating post-processing correction steps which may create further inconsistencies. A successful approach to geometric interaction modeling should consider both contact and non-contact interactions, requiring a robust method for representing and aligning the dense geometric information across different characters. Techniques that leverage dense mesh correspondences and spatial-temporal representations of the interaction field are promising avenues for accurately capturing and transferring geometric interactions during motion retargeting. This complex challenge necessitates innovative solutions that move beyond simple skeletal alignment, achieving natural-looking character animation.
ScanRet Dataset#
The creation of the ScanRet dataset represents a significant contribution to the field of motion retargeting. Addressing limitations in existing datasets like Mixamo, ScanRet focuses on high-quality motion capture data from real human actors, capturing detailed contact semantics and minimizing mesh interpenetration. This meticulous data collection, involving 100 human participants performing 83 diverse actions, and rigorous review by human animators, ensures data integrity. The emphasis on diverse body types expands the applicability of research findings beyond cartoon characters. The availability of this dataset, combined with its detailed annotations, will facilitate advancements in motion retargeting algorithms. ScanRet directly addresses the lack of high-quality, realistic human motion data, a critical bottleneck in the development and benchmarking of improved retargeting techniques. Its use enables researchers to more accurately evaluate algorithms and evaluate their robustness in real-world scenarios.
MeshRet Limitations#
MeshRet, while demonstrating state-of-the-art performance in geometric interaction-aware motion retargeting, has limitations. Its primary weakness is its sensitivity to noisy input data, particularly motion clips with significant mesh interpenetration. The method struggles in these scenarios, failing to accurately preserve motion semantics and resulting in suboptimal results. The reliance on Semantically Consistent Sensors (SCS) for dense mesh correspondence, while effective across various topologies, can be compromised by noisy or incomplete mesh data, leading to inaccuracies in geometric interaction modeling. Another key limitation is the method’s inability to handle characters with missing limbs. The current framework lacks the capacity to address such scenarios effectively, which significantly limits the range of characters applicable to MeshRet. Future work should focus on improving robustness to noisy inputs, enhancing SCS robustness, and expanding MeshRet’s capabilities to handle incomplete character models for broader applicability.
More visual insights#
More on figures
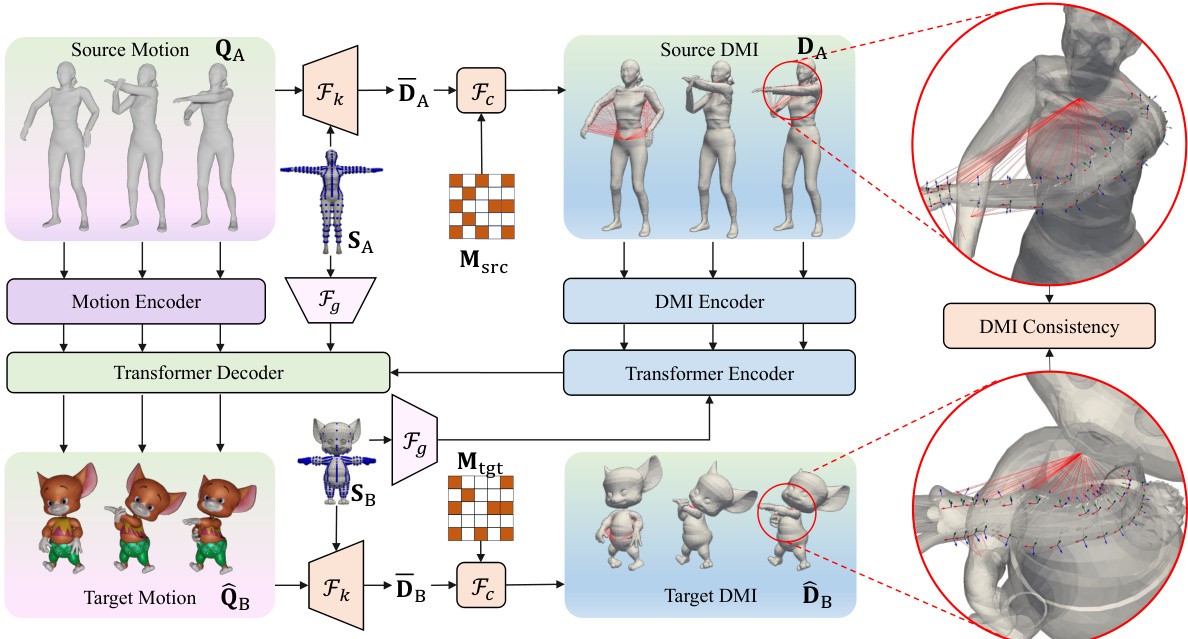
This figure illustrates the MeshRet framework, which processes source motion and geometry to generate target motion. It highlights the key stages: extracting the Dense Mesh Interaction (DMI) field from source motion data using sensor kinematics and feature selection, encoding both the DMI and geometric features, decoding to obtain target motion, and ensuring consistency between the source and target DMI fields. This approach directly models geometric interactions, unlike previous methods.

This figure illustrates two key aspects of the MeshRet framework. The left panel demonstrates how sensor features are derived from semantic coordinates, combining bone index, ray origin, and ray direction to create a representation that encapsulates both location and tangent space information. The right panel visually depicts the dense mesh interaction (DMI) field, showing how it captures both contact and non-contact interactions between different body parts. The use of yellow and blue points to illustrate contact and non-contact is clearly shown.

This figure compares the results of the proposed MeshRet method with several baseline methods for skinned motion retargeting. It visually demonstrates the superior performance of MeshRet in terms of maintaining precise contact between body parts and minimizing geometric artifacts such as mesh interpenetration and jittering. The figure showcases several motion sequences with different characters and highlights areas where the baseline methods fail to accurately preserve contact and introduce undesirable artifacts, while MeshRet successfully handles these challenges.

This figure compares the proposed MeshRet method with existing methods for skinned motion retargeting. Existing methods often separate skeleton-aware retargeting from geometry correction, leading to issues such as jittery motion, mesh interpenetration, and contact mismatches. MeshRet, in contrast, directly models dense geometric interactions using a DMI field, resulting in more accurate and natural-looking animations.

This figure compares the Mixamo and ScanRet datasets. The left panel shows that the Mixamo dataset does not always show characters maintaining correct hand contact during clapping actions, even when the characters have varying body types. The right panel shows that the ScanRet dataset shows characters of diverse body types consistently maintaining correct hand contact during clapping actions. This highlights one of the key differences between the two datasets and underscores the improved quality of the ScanRet dataset for motion retargeting.

The figure compares the proposed MeshRet method with existing methods for skinned motion retargeting. Existing methods often separate skeletal retargeting and geometry correction, leading to problems like jittering, mesh interpenetration, and inaccurate contact. MeshRet, on the other hand, directly models dense geometric interactions using a DMI field, resulting in more natural and accurate retargeting.
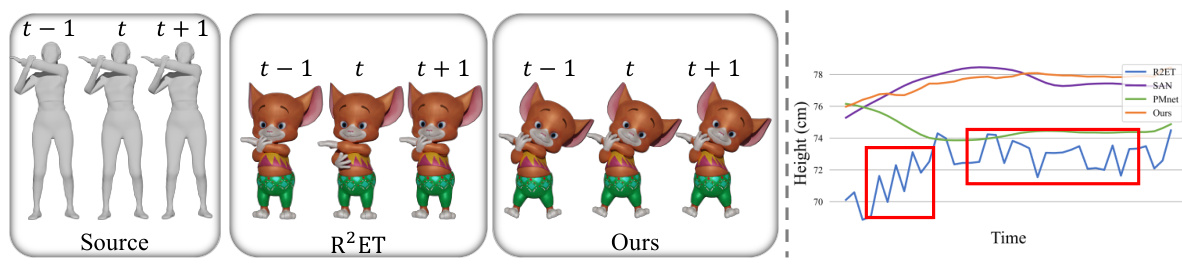
This figure compares the proposed MeshRet method with existing methods for skinned motion retargeting. Existing methods often use a two-stage process (skeleton retargeting followed by geometry correction) that leads to problems like jittering, mesh interpenetration, and inaccurate contact representation. MeshRet, in contrast, directly models dense geometric interactions using a DMI (Dense Mesh Interaction) field, leading to more accurate and natural results.

This figure compares the results of the proposed MeshRet method with several baseline methods for skinned motion retargeting. The comparison is qualitative and shows the effectiveness of MeshRet in terms of preserving precise contact and minimizing geometric interpenetration. The images display several different characters performing the same action; MeshRet produces more realistic results with proper contact and avoidance of mesh artifacts compared to the other methods.

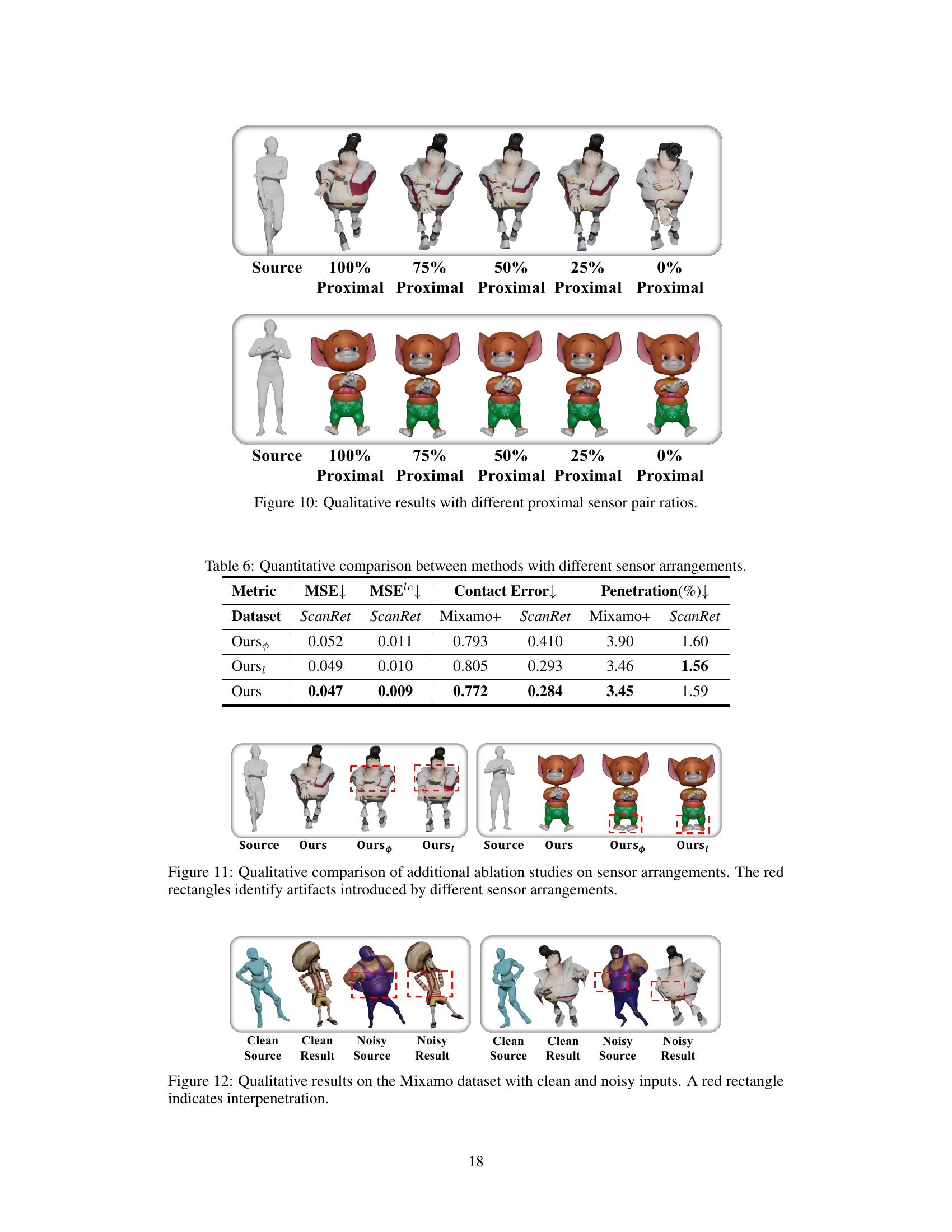
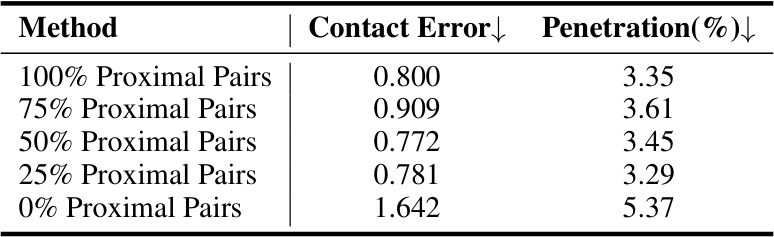
This figure shows a qualitative comparison of the results obtained using different ratios of proximal sensor pairs. The top row displays results for a human-like character, while the bottom row shows results for a cartoon character. In both cases, using 100% proximal pairs yields the best results in terms of preserving contact and avoiding interpenetration. As the percentage of proximal pairs decreases, the results gradually deteriorate, with 0% proximal pairs producing the poorest results. This illustrates the importance of including proximal sensor pairs in the DMI field to capture detailed geometric interactions.
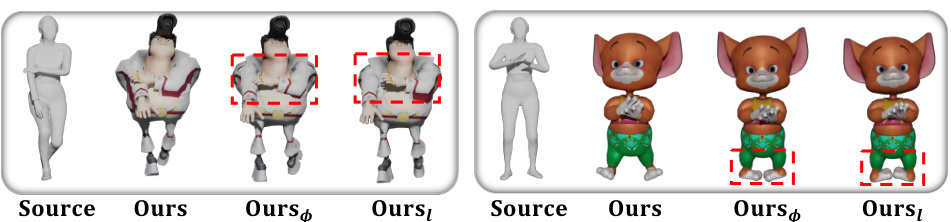
The figure compares the proposed MeshRet method with existing methods for skinned motion retargeting. Existing methods often involve a two-stage pipeline: skeletal retargeting followed by geometry correction. This approach leads to inconsistencies and artifacts such as jittering, interpenetration, and inaccurate contact. In contrast, MeshRet directly models dense geometric interactions using a DMI field, resulting in more accurate and natural motion with preserved contact.
This figure compares the proposed MeshRet method with existing methods for skinned motion retargeting. Existing methods often suffer from contradictions between skeleton-based retargeting and geometry correction, resulting in issues like mesh interpenetration, jittery motion, and inaccurate contact representation. In contrast, MeshRet directly models dense geometric interactions using a Dense Mesh Interaction (DMI) field, effectively resolving these issues and producing more natural and accurate results.
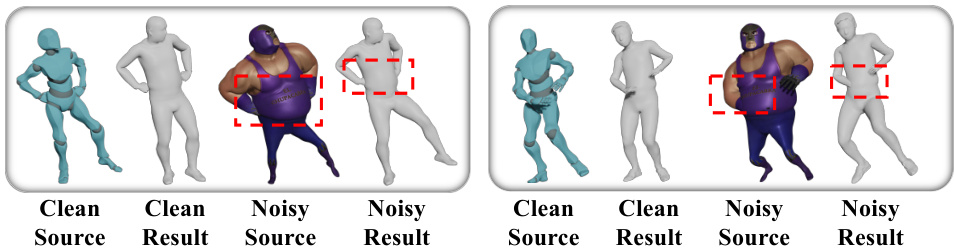
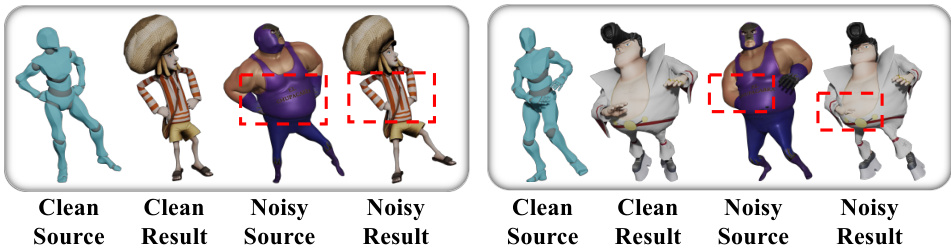
This figure shows a qualitative comparison of the proposed MeshRet method’s performance on the Mixamo dataset with both clean and noisy inputs. The results demonstrate the method’s ability to accurately retarget motion in the presence of clean data, while highlighting its sensitivity to noise. The red rectangles highlight areas where mesh interpenetration occurs, indicating the limitations of the approach when dealing with noisy data.

This figure compares the results of the proposed MeshRet method with several baseline methods for skinned motion retargeting. It showcases several motion sequences applied to different characters (a cartoon character, a muscular character, and a realistic character). The goal is to highlight that MeshRet accurately preserves contact between body parts and avoids mesh interpenetration, unlike the baseline methods which suffer from issues like jittering, self-interpenetration, and contact mismatches.

This figure compares the results of the proposed MeshRet method with several baseline methods for skinned motion retargeting. It shows several motion sequences, each retargeted to different characters with various body shapes. The ‘Source’ column demonstrates the original motion. The other columns represent the outputs of different methods: Copy (simple copying), PMnet, SAN, R2ET, and the proposed method (Ours). The images highlight the effectiveness of MeshRet in maintaining precise contact preservation between body parts and minimizing self-interpenetration, issues often encountered with other techniques. The differences in geometric accuracy and contact preservation between MeshRet and the baseline methods are clearly visible.

This figure compares the results of the proposed MeshRet method with several baseline methods for skinned motion retargeting. The top row shows the source motion. Subsequent rows display the retargeting results for different characters using various methods: Copy (simple copying of the motion), PMnet, SAN, R2ET, and finally the authors’ method (Ours). The comparison highlights MeshRet’s success in maintaining precise contact preservation and minimizing geometric artifacts like interpenetration, which are notable issues with the baseline methods. MeshRet’s superior performance in handling complex geometric interactions during motion retargeting is evident.

This figure compares the results of the proposed MeshRet method against several baseline methods for skinned motion retargeting. The top row shows the source motion sequence, which is then retargeted to different target characters in the subsequent rows. Each column represents a different method. The figure visually demonstrates that MeshRet achieves significantly better results than the alternatives in terms of maintaining accurate contact points between body parts and reducing instances of mesh interpenetration (where parts of the mesh overlap or pass through each other). The improvements in visual fidelity indicate more realistic and natural-looking character animation.
More on tables

This table presents a quantitative comparison of the proposed MeshRet method against several state-of-the-art methods for skinned motion retargeting. The evaluation is performed on two datasets: ScanRet and a combined Mixamo+ dataset. Three metrics are used to assess performance: Mean Squared Error (MSE) for joint positions, Contact Error which quantifies the accuracy of contact preservation, and Penetration, indicating the level of mesh interpenetration. Lower values are better for all three metrics, indicating higher accuracy, better contact preservation, and less geometric artifacts.

This table presents a quantitative comparison of the proposed MeshRet method against several state-of-the-art methods for skinned motion retargeting. The comparison uses three metrics: Mean Squared Error (MSE) for joint positions, Contact Error for contact preservation, and Penetration percentage for self-intersection. The results are shown for two datasets: ScanRet (a newly collected dataset with high-quality motion capture data emphasizing contact and non-contact interactions) and Mixamo+ (a combination of the Mixamo dataset and ScanRet). The MSEle metric represents the local MSE, providing a more fine-grained evaluation of joint position accuracy. The table allows for assessment of the relative performance of different retargeting methods across various metrics and datasets.
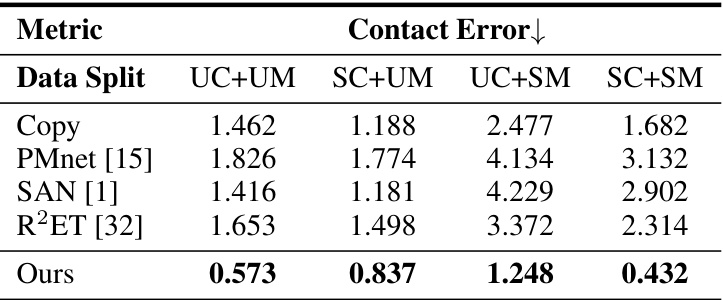
This table presents a quantitative comparison of the proposed MeshRet method against several state-of-the-art methods. The metrics used are Mean Squared Error (MSE) for joint positions, Contact Error (a measure of contact preservation), and the percentage of mesh interpenetration. Results are shown for the ScanRet dataset, the Mixamo dataset, and a combined Mixamo+ScanRet dataset. The results demonstrate the superior performance of MeshRet in terms of accuracy, contact preservation, and minimizing mesh self-interpenetration.

This table presents a quantitative comparison of the proposed MeshRet method against several state-of-the-art methods for skinned motion retargeting. The evaluation metrics include Mean Squared Error (MSE) for joint positions (both global and local), contact error, and the percentage of mesh penetration. The comparison is performed on two datasets: ScanRet (a newly collected dataset with high-quality motion capture data) and Mixamo+ (a combination of ScanRet and the publicly available Mixamo dataset). The results demonstrate MeshRet’s superior performance in terms of accuracy and preservation of geometric integrity.
This table quantitatively compares the performance of the proposed MeshRet method against several state-of-the-art methods. The comparison uses three metrics: Mean Squared Error (MSE) for joint positions, Contact Error for contact preservation, and Penetration Percentage for self-collision avoidance. The evaluation is performed on two datasets: ScanRet (a new dataset created by the authors) and Mixamo+ (a combination of the ScanRet and Mixamo datasets). Lower values indicate better performance for each metric.

This table presents a quantitative comparison of the proposed MeshRet method against several state-of-the-art methods for skinned motion retargeting. The evaluation metrics include Mean Squared Error (MSE) for both global and local joint positions, Contact Error (measuring the discrepancy between contact in source and target motion), and Penetration percentage (representing the degree of mesh interpenetration). The dataset used for the comparison is a combination of the Mixamo and ScanRet datasets, providing a comprehensive evaluation across diverse motion capture data.
Full paper#