↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Many high-quality images, audios, and videos are generated by diffusion models, which benefit greatly from extensive pre-training on large-scale datasets. However, these datasets often contain corrupted data where conditions don’t accurately describe the data. This study examines this problem by exploring the impact of such condition corruption during pre-training. It found that introducing slight corruption can improve the models’ quality, diversity, and fidelity.
This research systematically investigates the impact of synthetically introducing various types of slight condition corruption into pre-training data. The study uses over 50 conditional diffusion models trained on ImageNet-1K and CC3M. Experiments show that slight corruption enhances the models’ performance. A new method, Condition Embedding Perturbation (CEP), is proposed to improve model training by adding controlled perturbations, significantly enhancing performance in both pre-training and downstream tasks. This work provides valuable insights into optimizing data and pre-training processes for diffusion models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in diffusion models and generative AI. It challenges the conventional wisdom about data quality, offering a novel approach to improve model performance and opens new avenues for exploring the data-model relationship in deep learning. Its findings have significant implications for training more effective and efficient generative models using large-scale datasets.
Visual Insights#

This figure displays image samples generated by four different diffusion models (LDM-4 IN-1K, DiT-XL/2 IN-1K, LDM-4 CC3M, and LCM-v1.5 CC3M) trained under three different conditions: clean, slight corruption, and severe corruption. Each row represents a different level of corruption in the pre-training data, and each column represents a different model. The results show that a slight amount of corruption in the pre-training data leads to significantly better image quality and diversity compared to models trained on clean data, while severe corruption negatively impacts the results.
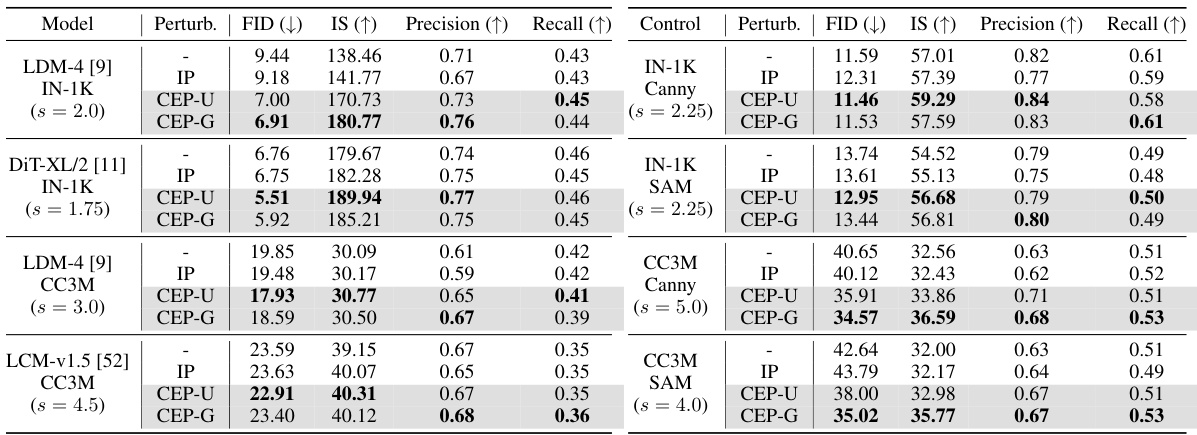
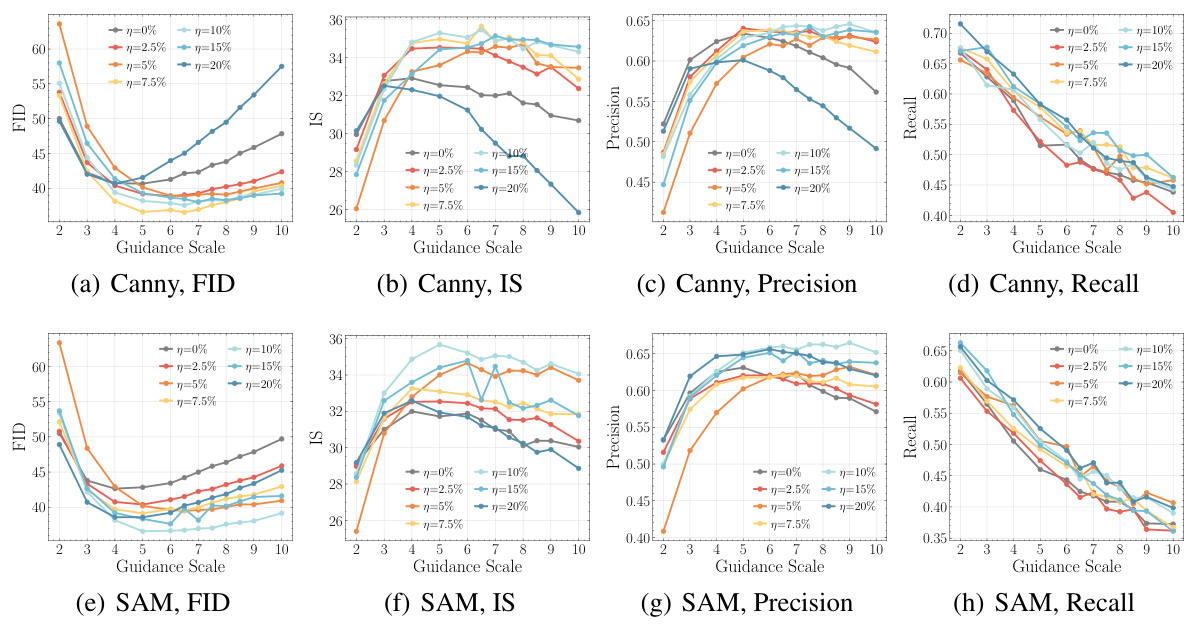
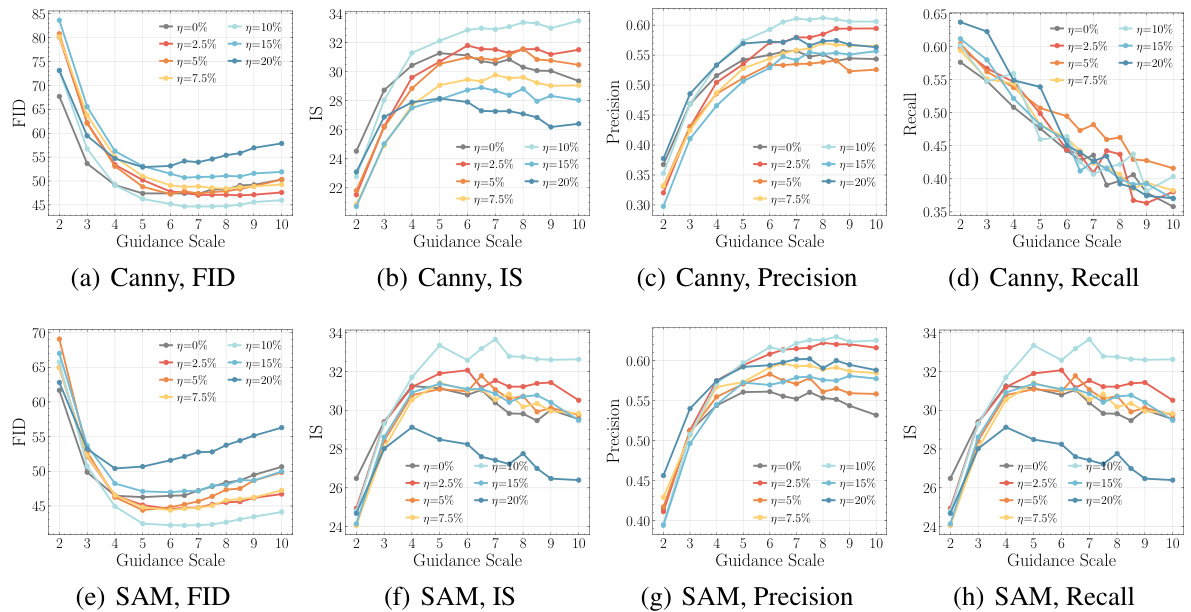
This table presents the results of personalizing pre-trained diffusion models on the ImageNet-100 dataset using the ControlNet method. The models were pre-trained with different types of conditional embedding perturbations (CEP), including uniform and Gaussian noise, as well as a baseline with no perturbation (IP). The table shows the FID (Fréchet Inception Distance), IS (Inception Score), Precision, and Recall metrics for each model and perturbation type. Canny edge detection and Segment Anything (SAM) segmentation masks were used as spatial controls. The results demonstrate that models pre-trained with CEP generally achieve better personalization performance than those pre-trained without perturbations, suggesting that introducing controlled noise during pre-training can enhance the quality and diversity of generated images.
In-depth insights#
Data Corruption Impact#
Analyzing the impact of data corruption is crucial for understanding the reliability and robustness of machine learning models. Slight corruption can be surprisingly beneficial, enhancing model generalization and diversity, potentially by encouraging exploration of a wider range of features and preventing overfitting to the training data’s specific idiosyncrasies. Conversely, severe corruption typically degrades performance, leading to decreased accuracy and unreliable outputs. The type and extent of data corruption significantly affect outcomes. Systematic studies using synthetically corrupted datasets enable controlled experimentation, allowing researchers to measure the impact of different corruption levels and types. Theoretical analysis provides valuable insights into the mechanisms through which corruption influences model behavior, but careful consideration of the model’s learning process and data distribution is necessary for accurate predictions. The interplay between data corruption and model architecture warrants further exploration to develop robust and reliable systems.
CEP Methodology#
The CEP (Conditional Embedding Perturbation) methodology, as described in the research paper, presents a novel approach to enhance diffusion models. It addresses the limitations of directly corrupting pre-training data by instead introducing perturbations directly into the conditional embeddings during training. This method is computationally efficient and avoids the complexities of dataset manipulation. The core idea is that slight perturbations improve model performance by increasing entropy and reducing the Wasserstein distance to the ground truth, thereby encouraging the generation of diverse, high-quality images. Theoretical analysis supports the efficacy, demonstrating improved generation diversity and quality with slight corruption. The practical implementation is straightforward, adding flexibility to existing training pipelines. The results show significant improvements across various diffusion model architectures and downstream tasks. While the method is primarily focused on image generation, its principles could potentially be extended to other modalities. Future research could explore optimal perturbation strategies and the impact of varying perturbation levels on specific diffusion model architectures.
Gaussian Mixture Model#
A Gaussian Mixture Model (GMM) is a probabilistic model that assumes data points are generated from a mixture of several Gaussian distributions. In the context of diffusion models, GMMs provide a powerful theoretical framework for understanding the impact of data corruption, particularly in the context of conditional generation. Slight corruption, by introducing perturbations into the conditional embeddings, increases the entropy of the model’s generated data distribution. This means the model generates a wider variety of outputs, rather than collapsing onto a few common ones. Theoretically, this higher entropy is proven to reduce the 2-Wasserstein distance between the GMM’s generated data and the true, underlying data distribution. This reduction in distance implies improved fidelity and better alignment with the ground truth. The GMM framework allows researchers to mathematically analyze how different types and levels of corruption affect the model’s learning and generalization capabilities, providing valuable insights into the optimization and performance of diffusion models and explaining the unexpected benefits of introducing slight noise into training data. The analysis suggests a nuanced relationship between corruption level and model performance; too much corruption is detrimental while a small amount can enhance generation quality. Therefore, the GMM is a crucial analytical tool for analyzing data corruption in diffusion models, offering mathematical rigor and theoretical justification for empirical observations.
Downstream Personalization#
The section on “Downstream Personalization” explores the adaptability of pre-trained diffusion models. It investigates how models, initially trained on massive datasets, can be effectively fine-tuned for specific downstream tasks. This is crucial because pre-trained models often lack the precise control needed for many applications. The research likely evaluates various personalization techniques, comparing their performance on specific metrics (like FID or IS). A key insight might be that models pre-trained with slight data corruption show improved personalization results, suggesting that a certain level of noise during initial training can enhance the model’s capacity for adaptation. This section likely demonstrates that even with limited data, downstream fine-tuning can dramatically improve results. The research might also analyze factors influencing personalization, such as the choice of techniques, the size of the personalization dataset, and the type of corruption employed during pre-training. This provides insights into the practical deployment of large language models, highlighting the importance of balancing generalization and specialized adaptation for specific user needs.
Future Research#
Future research directions stemming from this paper could explore several avenues. Expanding the types of corruption beyond class and text labels to encompass other modalities, such as image corruption or combined corruptions, would offer a more holistic understanding. Investigating the effects of corruption at different stages of the diffusion model training process is critical. Additionally, a deeper theoretical analysis, perhaps focusing on alternative model architectures or different noise schedules, could further refine our understanding of the mechanisms by which slight corruption improves performance. The impact of varying the level of corruption across different datasets requires investigation. Determining the optimal level and type of corruption for different diffusion model architectures could have significant practical implications. Finally, exploring the implications of these findings for improving the robustness and safety of generative models more broadly would be a significant contribution.
More visual insights#
More on figures
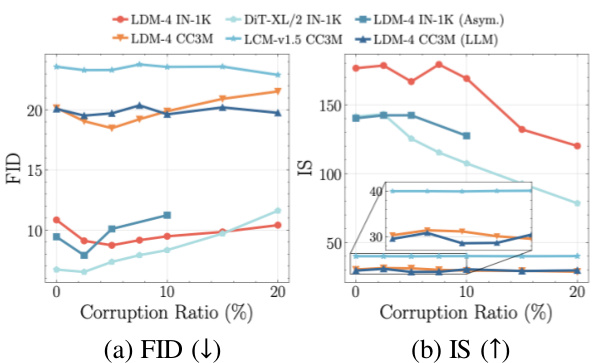
This figure shows the Fréchet Inception Distance (FID) and Inception Score (IS) for diffusion models trained on ImageNet-1K (IN-1K) and Conceptual Captions 3M (CC3M) datasets with varying levels of synthetic condition corruption. The x-axis represents the percentage of corrupted conditions, while the y-axis displays FID (lower is better) and IS (higher is better). The results indicate that introducing a small amount of corruption during pre-training improves the performance of the diffusion models, as measured by both FID and IS, compared to models trained on clean data. Different types of corruption were tested, showing that slight corruption is beneficial regardless of the specific corruption type. This suggests that a degree of noise or imperfection in the training data might be beneficial to model generalization and performance.

This figure shows the FID (Fréchet Inception Distance) and IS (Inception Score) for diffusion models trained on ImageNet-1K (IN-1K) and Conceptual Captions 3 Million (CC3M) datasets with varying levels of synthetic condition corruption. The x-axis represents the percentage of corruption, and the y-axis represents FID and IS. Lower FID and higher IS indicate better image quality and diversity. The results demonstrate that a small amount of corruption improves model performance compared to training with clean data.
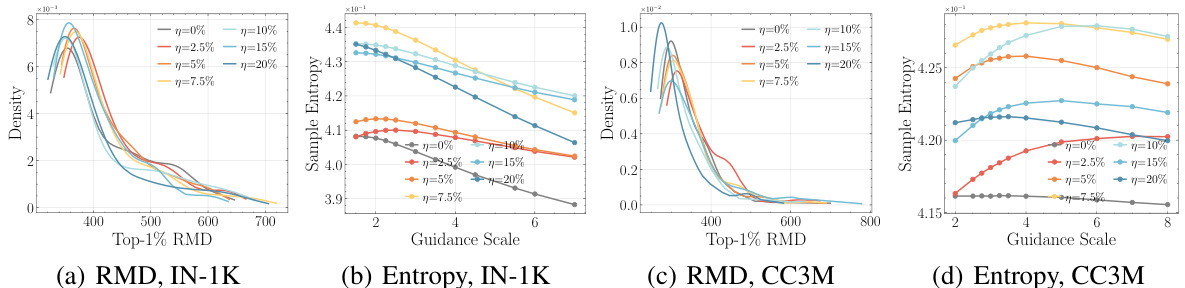
This figure quantitatively evaluates the complexity and diversity of generated images from class and text-conditional diffusion models. It uses two metrics: Top-1% Relative Mahalanobis Distance (RMD) and sample entropy. RMD assesses complexity and diversity, while sample entropy directly measures diversity. The results are shown for different guidance scales, revealing that models pre-trained with slight condition corruption produce samples with significantly higher complexity and diversity compared to those trained on clean data.

This figure shows a qualitative comparison of image generation results from circular walks in the latent space of trained diffusion models. The images are generated using class-conditional IN-1K LDMs (left) and text-conditional CC3M LDMs (right). Each row represents a different corruption ratio in the pre-training data. The results show that pre-training with a slight amount of corruption leads to significantly more diverse image generations in both IN-1K and CC3M model comparisons.
This figure presents a comprehensive quantitative evaluation of 50,000 images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with various levels of synthetic condition corruption. The evaluation uses multiple metrics (FID, IS, Precision, Recall, sFID, TopPR F1, Top-1% RMD, Memorization Ratio, Avg L2 Dist, CLIP Score) across different guidance scales, comparing the results against 50,000 validation images from ImageNet-1K. The purpose is to demonstrate the impact of different corruption levels on the quality and diversity of the generated images.

This figure shows a qualitative comparison of images generated using ControlNet and T2I-Adapter for both ImageNet-1K and Conceptual Captions 3M datasets. It visualizes the impact of slight condition corruption during pre-training on the diversity and quality of generated images for different conditional image generation tasks.

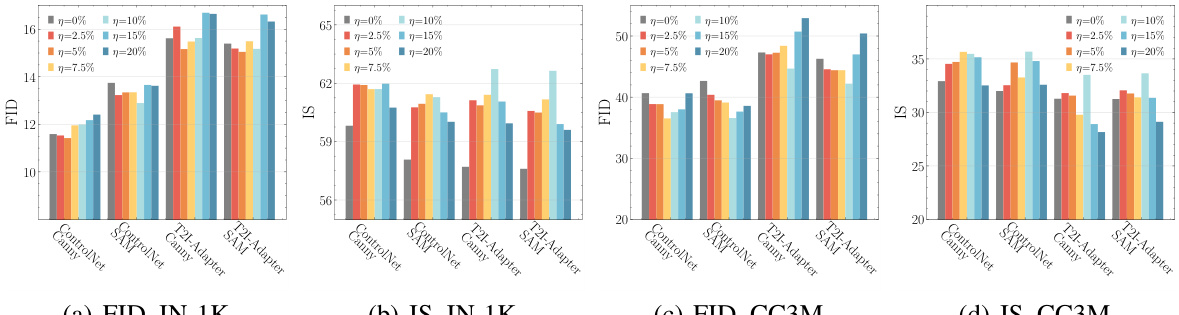
This figure shows the ablation study of the conditional embedding perturbation (CEP) method. It compares the FID (Fréchet Inception Distance) performance with different levels of perturbation added to the conditional embeddings in the training process. Part (a) shows an ablation study of the perturbation magnitude (γ), comparing it to the performance when training using a fixed corruption ratio (η). Part (b) shows the performance of CEP-U and CEP-G on the corrupted ImageNet-1K dataset (IN-1K) with varying corruption levels.

This figure shows a qualitative comparison of images generated by diffusion models (DMs) pre-trained with three different methods: clean (no corruption), input perturbation (IP), and conditional embedding perturbation (CEP). The comparison is made across different model families (LDM-4 and DiT-XL/2 on ImageNet-1K, LDM-4 and LCM-v1.5 on CC3M) and across pre-training and downstream personalization tasks (using ControlNet). The image samples illustrate the impact of each pre-training method on the quality and diversity of generated images, highlighting the advantages of CEP in improving image fidelity and diversity.

This figure shows example images from the ImageNet-100 dataset used for downstream personalization. Each row shows the same image with different annotations: the original image, the canny edge detection result, a segmentation mask generated by SegmentAnything, and the BLIP caption. This illustrates the types of annotations used to personalize the models for downstream tasks.

This figure displays the quantitative results of image generation using class-conditional diffusion models pre-trained on ImageNet-1K with various levels of synthetic condition corruption. Multiple metrics (FID, IS, Precision, Recall, sFID, TopPR F1, Top-1% RMD, Memorization Ratio, Avg L2 Dist, CLIP score) are plotted against different guidance scales, showing how slight corruption affects the quality and diversity of generated images compared to clean and heavily corrupted training data.

This figure shows the quantitative evaluation results of 50,000 images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with different levels of synthetic condition corruptions. The evaluation metrics used include FID, IS, Precision, Recall, sFID, TopPR F1, Top-1% RMD, Memorization Ratio, Average L2 Distance, and CLIP Score. The x-axis represents the guidance scale used during image generation, and each line represents a different level of corruption in the pre-training data. The results indicate that slight corruption can improve the quality and diversity of the generated images as measured by these metrics.

This figure shows the quantitative evaluation results for 50,000 images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with different levels of synthetic condition corruption. The metrics used (FID, IS, Precision, Recall, sFID, TopPR F1, Top-1% RMD, and Memorization Ratio) are plotted against various guidance scales. The results demonstrate the impact of different levels of corruption on the quality and diversity of the generated images compared to clean ImageNet-1K data.
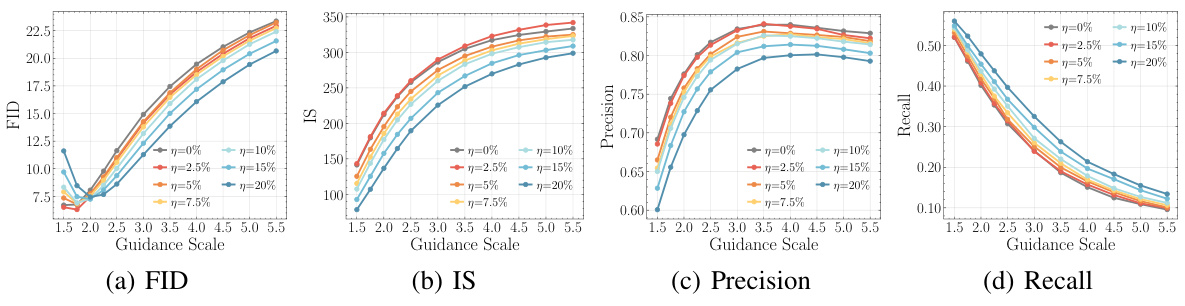
This figure presents a quantitative evaluation of images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with varying degrees of synthetic condition corruption. The evaluation metrics include FID (Fréchet Inception Distance), IS (Inception Score), Precision, Recall, sFID, TopPR F1, Top-1% RMD (Relative Mahalanobis Distance), and Memorization Ratio. The x-axis represents different guidance scales used during image generation. The results show how different levels of corruption in the pre-training data affect the quality and diversity of the generated images.

This figure shows the quantitative evaluation results of 50,000 images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with synthetically introduced corruptions at various levels. The metrics used to evaluate the generated images include Fréchet Inception Distance (FID), Inception Score (IS), Precision, Recall, sFID, Top-1% Relative Mahalanobis Distance (RMD), and average L2 distance. The results show that slight corruption helps achieve a better trade-off between image quality (FID, IS, sFID) and diversity (RMD, L2). The different lines correspond to different corruption levels.

This figure presents a comprehensive quantitative evaluation of 50,000 images generated by class-conditional Latent Diffusion Models (LDMs) trained on ImageNet-1K with varying levels of synthetic condition corruption. The evaluation metrics include Fréchet Inception Distance (FID), Inception Score (IS), Precision, Recall, sFID, TopPR F1, Top-1% Relative Mahalanobis Distance (RMD), Memorization Ratio, and Average L2 Distance. The x-axis represents different guidance scales used during image generation, showcasing the impact of corruption on image quality and diversity at various guidance levels. The results demonstrate that slight condition corruption improves most metrics compared to clean pre-training, suggesting a benefit to introducing carefully controlled noise into the training data.
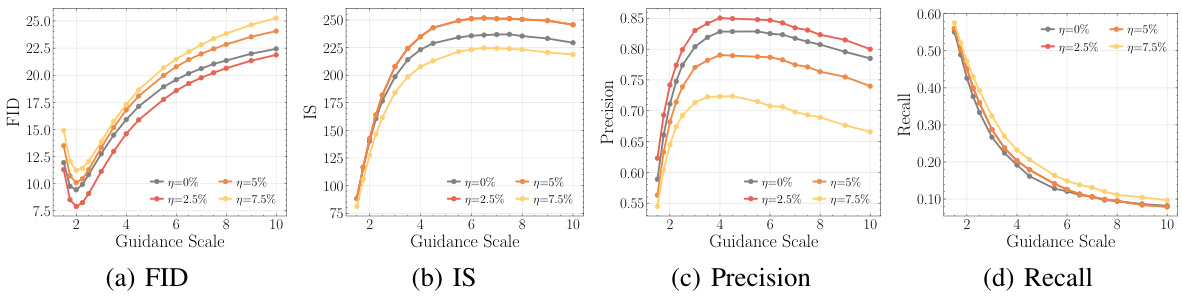
This figure presents a comprehensive quantitative analysis of images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with varying levels of synthetic condition corruption. The evaluation metrics used include Fréchet Inception Distance (FID), Inception Score (IS), Precision, Recall, sFID, TopPR F1, Top-1% Relative Mahalanobis Distance (RMD), and Memorization Ratio. Each metric is plotted against different guidance scales, revealing the impact of corruption levels on image quality, fidelity, diversity, and memorization. The results show that slight corruption enhances model performance across several metrics.

This figure visualizes the results of pre-training Latent Diffusion Models (LDMs) on the ImageNet-1K dataset. It shows example images generated by the LDMs with varying degrees of synthetic condition corruption. The rows represent different classes of images (e.g., Ptarmigan, Carbonara, etc.), and the columns represent different levels of corruption, ranging from clean data to 20% corruption. The figure aims to visually demonstrate the impact of condition corruption on the generated images’ quality and diversity.

This figure visualizes the IN-1K pre-training results for the DiT-XL/2 model. It shows a grid of images for several classes, with each row representing a different class (e.g., Tiger Shark, Ostrich, Junco, etc.). Within each row, the images show the model’s output at different levels of synthetic condition corruption (η), ranging from clean data (0%) to highly corrupted data (20%). This illustrates how the introduction of slight corruption affected image generation quality and diversity across various corruption levels.

This figure displays image samples generated by different diffusion models trained with varying levels of synthetic condition corruption in their pre-training data. The three columns represent models trained on ‘clean’ data (no corruption), data with ‘slight’ corruption, and data with ‘severe’ corruption. Each row shows examples of images generated based on a specific class or text prompt. The caption highlights that introducing a slight level of corruption during pre-training leads to higher image quality and diversity compared to using clean data or severely corrupted data.

This figure shows sample images generated by different diffusion models (DMs). The models were pre-trained using three different conditions: clean data, data with slight corruption, and data with severe corruption. The ‘clean’ images show the results when the model is trained on accurate data. The ‘slight corruption’ images demonstrate that introducing minor errors during training enhances the overall quality and variety of the generated images. Conversely, ‘severe corruption’ shows a drop in quality and diversity, illustrating the optimal level of data corruption for enhancing DM performance.

This figure presents a quantitative analysis of images generated by class-conditional diffusion models trained on ImageNet-1K with varying levels of synthetic condition corruption. Multiple metrics are plotted against different guidance scales to assess the impact of corruption on image quality, fidelity, and diversity. The metrics shown include FID, IS, Precision, Recall, sFID, TopPR F1, Top-1% RMD, and Memorization Ratio. The results demonstrate that a small amount of corruption can improve several key metrics, while excessive corruption leads to diminished performance.

This figure presents a comprehensive quantitative evaluation of images generated by class-conditional diffusion models pre-trained on ImageNet-1K with varying levels of synthetic condition corruption. It uses multiple metrics (FID, IS, Precision, Recall, SFID, TopPR F1, Top-1% RMD, Memorization Ratio, Average L2 Distances, CLIP Score) to assess image quality, fidelity, diversity, and memorization across different guidance scales. The results demonstrate the impact of slight corruption on these metrics, indicating its potential benefits for model training.
This figure presents a quantitative evaluation of 50K images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with synthetically introduced condition corruptions. The evaluation metrics used include FID (Fréchet Inception Distance), IS (Inception Score), Precision, Recall, sFID (modified FID), TopPR F1, Top-1% RMD (Relative Mahalanobis Distance), and Memorization Ratio. Each metric is plotted against different guidance scales, revealing the impact of various corruption ratios (η) on the quality and diversity of generated images. The results illustrate that slight corruption improves several image quality metrics, indicating the beneficial impact of this corruption on the pre-training process.
This figure presents a quantitative evaluation of images generated by class-conditional Latent Diffusion Models (LDMs) pre-trained on ImageNet-1K with varying levels of synthetic condition corruption. It shows multiple metrics plotted against guidance scale, assessing the impact of corruption on image quality, fidelity, and diversity. The metrics include FID (Fréchet Inception Distance), IS (Inception Score), Precision, Recall, sFID, TopPR F1, Top-1% RMD, Memorization Ratio, and Average L2 Distance. Each line represents a different corruption ratio, allowing for a comparison of the effects of different corruption levels on image generation.

This figure shows a qualitative comparison of images generated by diffusion models (DMs) pre-trained with three different methods: clean data, input perturbation (IP), and conditional embedding perturbation (CEP). The figure demonstrates the effect of each method on both pre-training and personalization stages. For pre-training, diverse examples across various categories are shown, highlighting the effect of each method on image diversity and quality. In the personalization section, the same categories are shown with additional spatial control (Canny edge detection), further illustrating the impact of the pre-training methods on controlled image generation.

This figure shows the qualitative results of personalization experiments using ControlNet with SAM segmentation masks on LDMs pre-trained on IN-1K. Different corruption levels (η) are compared with clean and IP (input perturbation) baselines. The images illustrate the effects of slight condition corruption on the diversity and quality of generated images across various control styles and corruption levels. The results show that using models trained with slight corruption levels produces superior image quality and diversity.

This figure shows the qualitative results of personalization experiments on text-conditional LDMs pre-trained on CC3M using ControlNet with Canny edge as spatial control. Different levels of synthetic condition corruption (η) are tested, ranging from clean (no corruption) to 20% corruption. The results are shown for four different prompts, demonstrating the effect of corruption level on the quality and diversity of generated images. Each row represents a different prompt, while each column shows the generated images under various corruption ratios. The spatial control (canny edge) is consistent across all conditions, revealing how corruption influences the generated images.

This figure shows the qualitative results of personalization experiments using ControlNet with SAM segmentation masks on text-conditional LDMs pre-trained on CC3M. The results are presented for various levels of condition corruption (η). Each row displays a specific prompt and the corresponding images generated by models trained with different levels of corruption, ranging from clean to highly corrupted. The goal is to visually compare the image quality and diversity across different levels of corruption.

This figure shows a qualitative comparison of images generated by two different diffusion models (LDM-4 and DiT-XL/2) trained on the ImageNet-1K dataset using three different methods: clean training, input perturbation (IP), and conditional embedding perturbation (CEP). The images are arranged in rows, each row showing different classes from the dataset and the three generation methods, to compare their image quality and diversity. This figure helps demonstrate the impact of conditional embedding perturbation on the quality and variety of images produced by the diffusion models.

This figure visualizes the results of applying Conditional Embedding Perturbation (CEP) to pre-trained diffusion models, specifically Latent Diffusion Models (LDM-4) and Latent Consistency Models (LCM-v1.5), on the CC3M dataset. It compares the image generation capabilities of models trained with clean data, data with input perturbations, and data with CEP-Uniform and CEP-Gaussian perturbations. Each row shows examples generated from different models under the same text prompt, illustrating the impact of CEP on image generation quality and diversity. The results show that CEP generally leads to more visually appealing and realistic image generations than the other methods.

This figure shows a qualitative comparison of images generated by two different diffusion models (LDM-4 and DiT-XL/2) pre-trained on ImageNet-1K using different methods: clean, input perturbation (IP), and conditional embedding perturbation (CEP). The images are grouped by class, and each class shows the images generated using each of the three methods, allowing for a visual comparison of the effect of the different pre-training methods on image quality and diversity. The results suggest that CEP can improve the quality and diversity of images generated by diffusion models.

This figure visualizes the impact of Conditional Embedding Perturbation (CEP) on the performance of a ControlNet adapted, CC3M pre-trained Latent Diffusion Model (LDM-4). It compares the image generation results from models trained with clean data, input perturbation (IP), uniform CEP (CEP-U), and Gaussian CEP (CEP-G). The results show images generated in response to various text prompts.
More on tables

This table lists the hyperparameters used for training both IN-1K class-conditional and CC3M text-conditional Latent Diffusion Models (LDMs). It details settings such as downsampling factor, latent space shape, vocabulary size, number of diffusion steps, noise schedule, U-Net parameter size, condition network type, number of channels, channel multiplier, number of attention heads, batch size, number of training iterations, and the learning rate. These hyperparameters were crucial in controlling the training process and ultimately the performance of the generated images.

This table lists the hyperparameters used for training the DiT-XL/2 model on the ImageNet-1K dataset. It includes details such as the down-sampling factor used for the VQ-VAE, the dimensions of the latent space, the vocabulary size, the number of parameters in the model, the number of training iterations, the batch size used during training, and the learning rate.
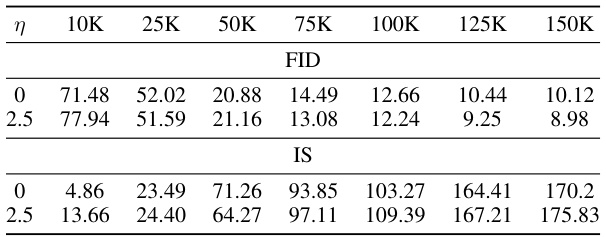
This table presents the FID and IS scores of a Latent Diffusion Model (LDM) trained on ImageNet-1K (IN-1K) at various training iterations (10K, 25K, 50K, 75K, 100K, 125K, 150K). The results are shown for two conditions: a clean dataset (η=0) and a dataset with a 2.5% corruption ratio (η=2.5). The guidance scale is fixed at 2.5. This data illustrates the performance of the LDM over training iterations in terms of both fidelity (FID) and diversity (IS) in the presence and absence of data corruption.

This table presents a comparison of the performance of Latent Diffusion Models (LDMs) trained on ImageNet-1K (IN-1K) using different methods: clean training, adding dropout, applying label smoothing, and using Conditional Embedding Perturbation (CEP) with uniform and Gaussian noise. The metrics used for comparison are FID (Fréchet Inception Distance), a measure of image quality, and IS (Inception Score), a measure of image quality and diversity. The results demonstrate the effectiveness of CEP in enhancing the quality and diversity of generated images compared to other regularization methods.

This table presents the FID and IS scores for ImageNet-1K LDM-4 models trained with different corruption methods: clean, CEP-U (conditional embedding perturbation with uniform distribution), fixed CEP-U (fixed locations for adding uniform noise), random data corruption (randomly corrupting the data), and fixed data corruption (fixed locations for data corruption). The results show that CEP-U achieves the best performance, highlighting its effectiveness in improving the quality and diversity of generated images.
Full paper#



















