↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Generating consistent images and videos that tell a coherent story is a major challenge in current diffusion models. Existing methods struggle to maintain consistent subjects and details over long sequences, or lack user control. This is particularly difficult in video generation, where smooth transitions are crucial for a believable narrative.
StoryDiffusion tackles this by introducing Consistent Self-Attention, a mechanism that boosts consistency between generated images by incorporating reference tokens. It’s also combined with a Semantic Motion Predictor to generate videos with smooth transitions. Unlike other methods, StoryDiffusion is training-free and easily added to existing models, making it readily accessible to researchers. The experimental results showcase StoryDiffusion’s superior performance in generating consistent and high-quality images and videos, demonstrating its potential to revolutionize visual storytelling.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a significant challenge in diffusion-based image and video generation: maintaining consistent content across long sequences. The proposed method, StoryDiffusion, offers a novel, zero-shot approach to improving consistency, opening new avenues for research in visual storytelling and long-form video generation. Its training-free, plug-and-play nature makes it easily adaptable to existing models. This work is highly relevant to current research trends in diffusion models, controllable generation, and video synthesis.
Visual Insights#

This figure showcases the capabilities of StoryDiffusion in generating both image and video content based on textual descriptions. Panel (a) demonstrates a comic strip illustrating a jungle adventure, while (b) depicts a comic strip about an astronaut’s moon landing, incorporating reference image control for character consistency. Panel (c) displays examples of videos generated using the model, emphasizing smooth transitions and consistent subject representation.

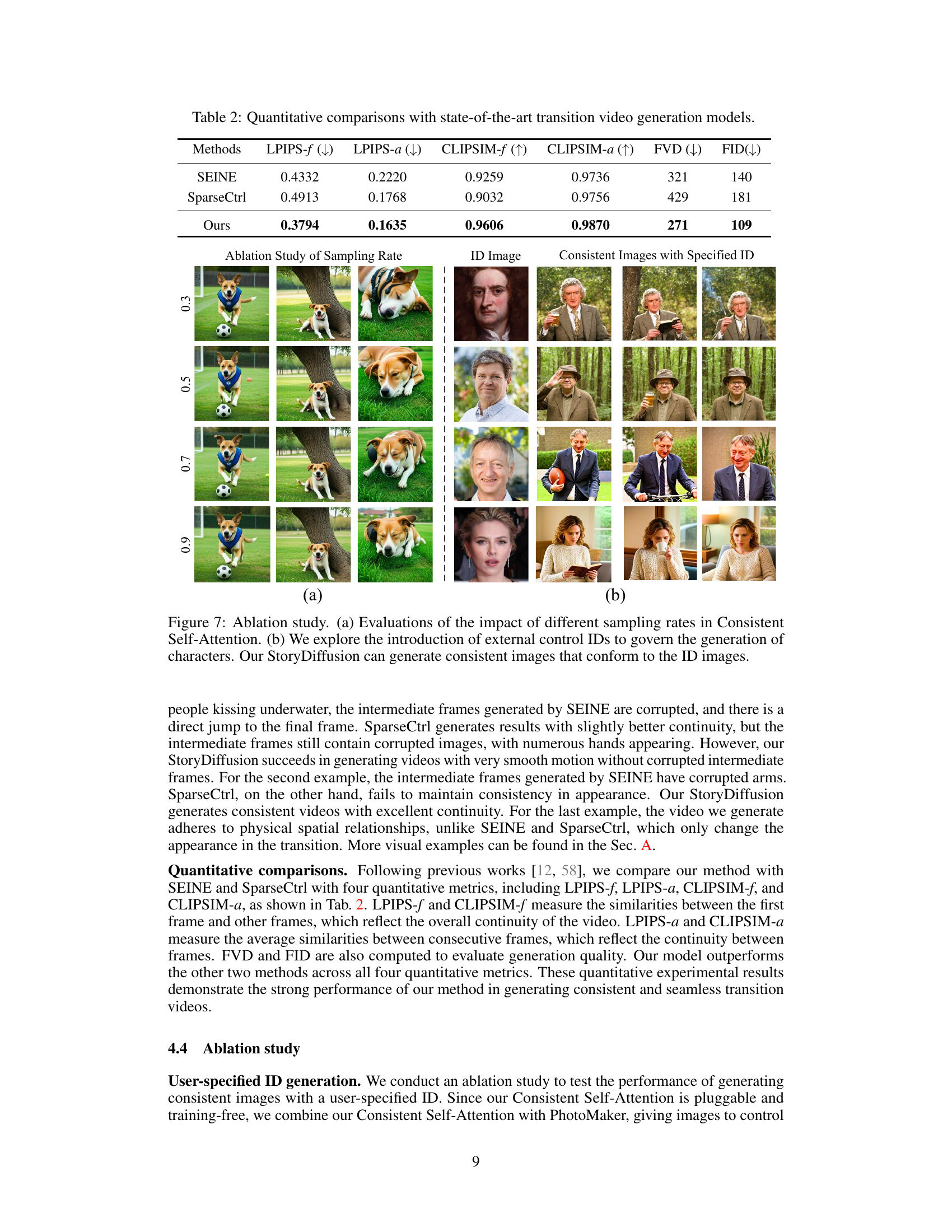
This table presents a quantitative comparison of consistent image generation methods, including IP-Adapter, Photo Maker, and the proposed StoryDiffusion. The metrics used are Text-Image Similarity and Character Similarity, both measured using CLIP scores. The results show that StoryDiffusion achieves higher scores in both metrics compared to the other two methods, indicating better performance in generating images that are both consistent with the text prompt and consistent in terms of character identity and appearance. Importantly, StoryDiffusion achieves this superior performance without requiring any training.
In-depth insights#
Consistent Image Gen#
The concept of “Consistent Image Generation” in the context of visual storytelling using diffusion models is crucial. It addresses the challenge of maintaining visual consistency across multiple images generated from a textual narrative. The core issue is how to ensure that characters, settings, and overall style remain coherent throughout the generated sequence. Existing approaches often struggle with this, leading to inconsistencies in character appearance, attire, and scene details. The proposed solution likely involves novel self-attention mechanisms or other techniques to establish and maintain visual relationships between generated images. This might be achieved by employing shared latent representations across a batch of images or by using prior images to guide the generation of subsequent ones. A key aspect would be the balance between maintaining consistency and allowing sufficient variability to convey the narrative effectively. Successfully addressing this challenge would represent a significant advancement in the field, potentially leading to the generation of higher-quality and more engaging visual stories. The method’s efficiency and zero-shot capability are also important factors to consider. The evaluation of the method likely involves qualitative assessments based on visual coherence and quantitative metrics comparing consistency levels achieved compared to prior art.
Semantic Motion Pred#
The proposed “Semantic Motion Pred” module is a crucial component for generating high-quality and consistent videos. It operates within semantic spaces, which offers advantages over traditional methods relying on latent spaces. Operating in semantic spaces allows the model to focus on higher-level motion characteristics and relationships between images, rather than being restricted to pixel-level changes. This is particularly beneficial for long-range video generation where large motion discrepancies between keyframes would be difficult to bridge in latent space. The training procedure of the Semantic Motion Predictor is key; it should be designed to capture complex motion patterns effectively without relying on extensive data or time-consuming processes. A training-free approach or efficient zero-shot adaptation would be highly desirable. By predicting motions directly in the semantic space, the module enables smooth transitions and maintain consistent characters, providing more natural and coherent video storytelling compared to latent-space-only approaches. The effectiveness of this method depends on the quality of the semantic image representations; therefore, the choice of image encoder and its effectiveness in representing higher-level semantic information is extremely important. Integration of the Semantic Motion Predictor with the consistent image generation component is another critical aspect for the success of StoryDiffusion. A seamless connection would be necessary to ensure subject consistency throughout the video generation process.
Zero-shot Learning#
Zero-shot learning (ZSL) is a fascinating area of machine learning research that tackles the problem of classifying unseen classes during the testing phase. This is achieved without requiring any labeled examples of these unseen classes during training. Instead, ZSL leverages auxiliary information, such as semantic attributes, word embeddings, or visual features of seen classes, to bridge the gap between seen and unseen classes. The core challenge in ZSL lies in effectively transferring knowledge learned from seen classes to predict the labels of unseen ones. This often involves tackling the semantic gap, which refers to the difference in representation between visual features and semantic descriptions. Various approaches exist, including methods that employ generative models to synthesize images of unseen classes, or those that learn a shared embedding space between visual and semantic representations. Despite significant advancements, ZSL remains a challenging problem because of issues like data scarcity for unseen classes and domain shift between training and testing data. However, its potential is immense, promising significant progress in AI’s ability to generalize to novel scenarios and learn from limited data. Future research directions include developing more robust methods for handling the semantic gap and domain adaptation, as well as exploring more effective ways to leverage knowledge graphs and external knowledge bases.
Long-Range Video#
Generating long-range videos presents a significant challenge in video generation, demanding the maintenance of consistent content and smooth transitions across extended sequences. Existing methods often struggle with this, especially when dealing with complex scenes and detailed subjects. StoryDiffusion addresses this limitation by introducing the Semantic Motion Predictor module. This innovative component operates within the semantic space of images to predict motion between frames, resulting in more natural and stable video generation, in contrast to techniques confined to the latent space. The semantic space approach proves superior, especially for long videos, as it accounts for larger-scale subject movements that might otherwise lead to inconsistencies or artifacts. Consistent Self-Attention, another key component of StoryDiffusion, enhances inter-frame consistency by creating correlations between images within a batch. This facilitates the smooth transitions and consistent identities crucial for storytelling across extended video timelines. By synergistically employing these techniques, StoryDiffusion showcases substantial progress in generating long-range videos that are both visually appealing and narratively coherent.
Future Work#
The paper’s ‘Future Work’ section presents exciting avenues for research. Extending StoryDiffusion to handle longer stories and videos is paramount, addressing the current limitation on video length and consistency in extremely long narratives. This likely involves exploring more sophisticated temporal modeling techniques beyond the Semantic Motion Predictor, perhaps integrating advanced memory mechanisms or hierarchical structures. Improving controllability over character attributes and scene details is another key area, potentially through incorporating fine-grained control mechanisms or leveraging external knowledge sources. Investigating alternative self-attention mechanisms to further enhance consistency while preserving computational efficiency is another avenue. Further research could explore different sampling strategies, token representations, or attention architectures. Finally, thorough evaluation across diverse datasets and story types would strengthen the model’s generalizability and robustness, including comparisons with other state-of-the-art methods in a wider variety of scenarios and story lengths. Addressing these points could lead to a significant advance in the field of visual storytelling.
More visual insights#
More on figures

This figure showcases the capabilities of StoryDiffusion in generating both image and video content. Panel (a) shows a comic illustrating a jungle adventure, panel (b) depicts a comic of a moon exploration by Lecun (with a reference image used for control), and panel (c) displays example videos produced, highlighting smooth transitions and consistent subjects.
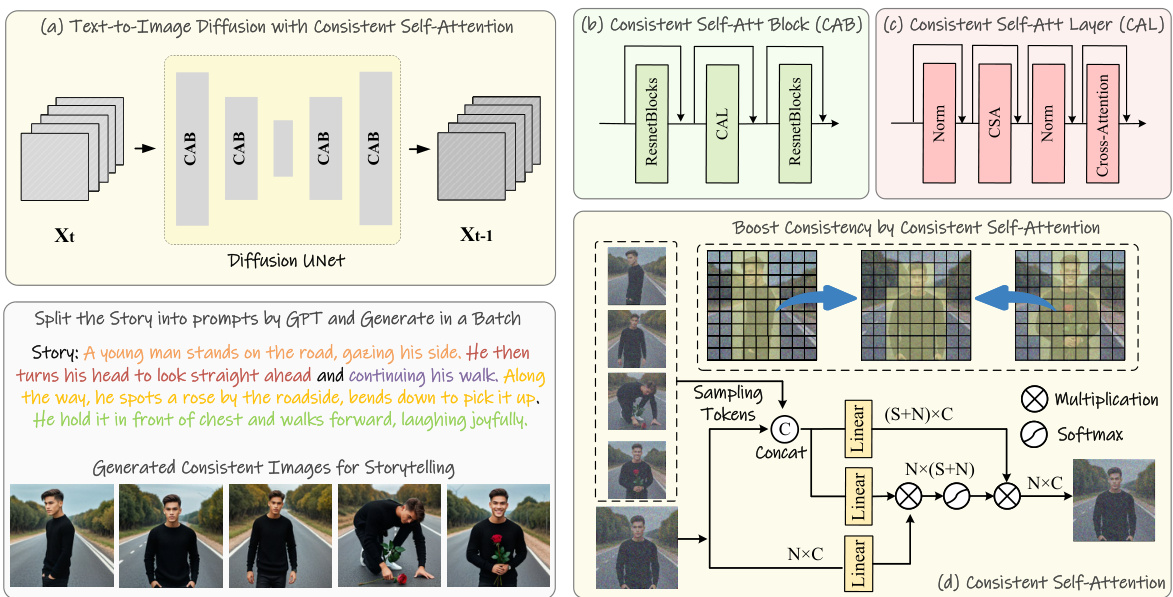
This figure illustrates the overall pipeline of StoryDiffusion for generating subject-consistent images. It shows how a story is split into prompts, fed into a pre-trained text-to-image diffusion model enhanced with Consistent Self-Attention, and how this module builds connections between multiple images within a batch to ensure consistency. The figure also provides a detailed breakdown of the Consistent Self-Attention module itself, showing its internal operations and how it boosts consistency in the generated images.

This figure illustrates the process of generating transition videos using StoryDiffusion. It starts with a sequence of generated consistent images (or user input). These images are encoded into a semantic space using an image encoder. A Semantic Motion Predictor then takes these semantic embeddings and predicts intermediate frames to smoothly transition between the input images. These predicted frames are used as control signals in a video diffusion model which generates the final consistent videos.

This figure compares the performance of StoryDiffusion with two other state-of-the-art methods (IP-Adapter and PhotoMaker) for generating consistent images given a text prompt. Each row represents a different method, and each column depicts a different activity described by the prompt. The results show that StoryDiffusion generates images with better text controllability, higher face consistency, and better attire cohesion across all the activities compared to the other two methods.

This figure compares the image generation results of StoryDiffusion with three other storybook generation methods: The Chosen One, ConsiStory, and Zero-shot coherent storybook. Each method is given the same prompt to generate a sequence of images depicting a story. The figure shows that StoryDiffusion generates images that are more consistent in terms of character identity, attire, and setting across the different images in the sequence compared to the other methods. This highlights StoryDiffusion’s ability to generate more coherent and visually appealing storybooks.

This figure compares the performance of StoryDiffusion against two state-of-the-art methods (SEINE and SparseCtrl) in generating transition videos. Two example video transitions are shown, each with the generated intermediate frames from the three methods displayed. The figure showcases StoryDiffusion’s ability to generate smoother and more physically plausible transitions compared to the other methods.

This figure presents the results of an ablation study on the StoryDiffusion model. The left side (a) shows how different sampling rates in the Consistent Self-Attention module affect the consistency of generated images. The right side (b) demonstrates the ability of StoryDiffusion to generate consistent images conforming to a specified identity (ID) image provided as an external control.

This figure showcases examples of image and video generation results using StoryDiffusion. Panel (a) presents a comic illustrating a jungle adventure story. Panel (b) shows a comic depicting a moon exploration, incorporating a reference image for control. Panel (c) displays video clips generated by the model, highlighting smooth transitions and consistent subject depiction across longer sequences.

This figure provides a qualitative comparison of consistent image generation results from StoryDiffusion, PhotoMaker, and IP-Adapter across six different scenarios. Each scenario consists of three image generation tasks with varying prompts designed to test the models’ ability to maintain consistency in character appearance and attire, despite changes in the background and actions. The results show that StoryDiffusion excels at maintaining consistency across all scenarios, outperforming PhotoMaker and IP-Adapter which often struggle with attire consistency or fall short in generating images that fully align with the text prompts.

This figure compares the performance of three different methods (SEINE, SparseCtrl, and StoryDiffusion) in generating intermediate frames for transition videos. Each row shows a different video transition example, with the start and end frames shown on the left and right, respectively. The generated intermediate frames are displayed in the center. The red boxes highlight the input frames used for each method. The comparison highlights StoryDiffusion’s superior ability to produce smoother and more coherent intermediate frames, especially when compared to the other two methods that struggle with large motion gaps between start and end frames.

This figure shows the results of combining Consistent Self-Attention with ControlNet for pose-guided image generation. It demonstrates the effectiveness of Consistent Self-Attention in maintaining subject consistency even when using additional control mechanisms like ControlNet’s pose guidance. The figure presents several examples, each showing the generated images with and without Consistent Self-Attention, illustrating how the proposed method improves the consistency of generated images while adhering to the specified pose constraints.

This figure shows the results of applying StoryDiffusion to three different diffusion models: Stable Diffusion 1.5, Stable Diffusion 2.1, and Stable Diffusion XL. The consistent results across these different models demonstrate the plug-and-play nature of the Consistent Self-Attention module, highlighting its adaptability and robustness. The images show a series of consistent images generated for each model, illustrating the subject’s consistent identity and attire.
More on tables

This table presents a quantitative comparison of the proposed StoryDiffusion model against two state-of-the-art transition video generation models, SEINE and SparseCtrl. The comparison uses six metrics: LPIPS-f, LPIPS-a, CLIPSIM-f, CLIPSIM-a, FVD, and FID. Lower values are better for LPIPS-f, LPIPS-a, FVD, and FID, while higher values are better for CLIPSIM-f and CLIPSIM-a. The results show that StoryDiffusion outperforms the other methods across all metrics, indicating superior performance in generating transition videos.

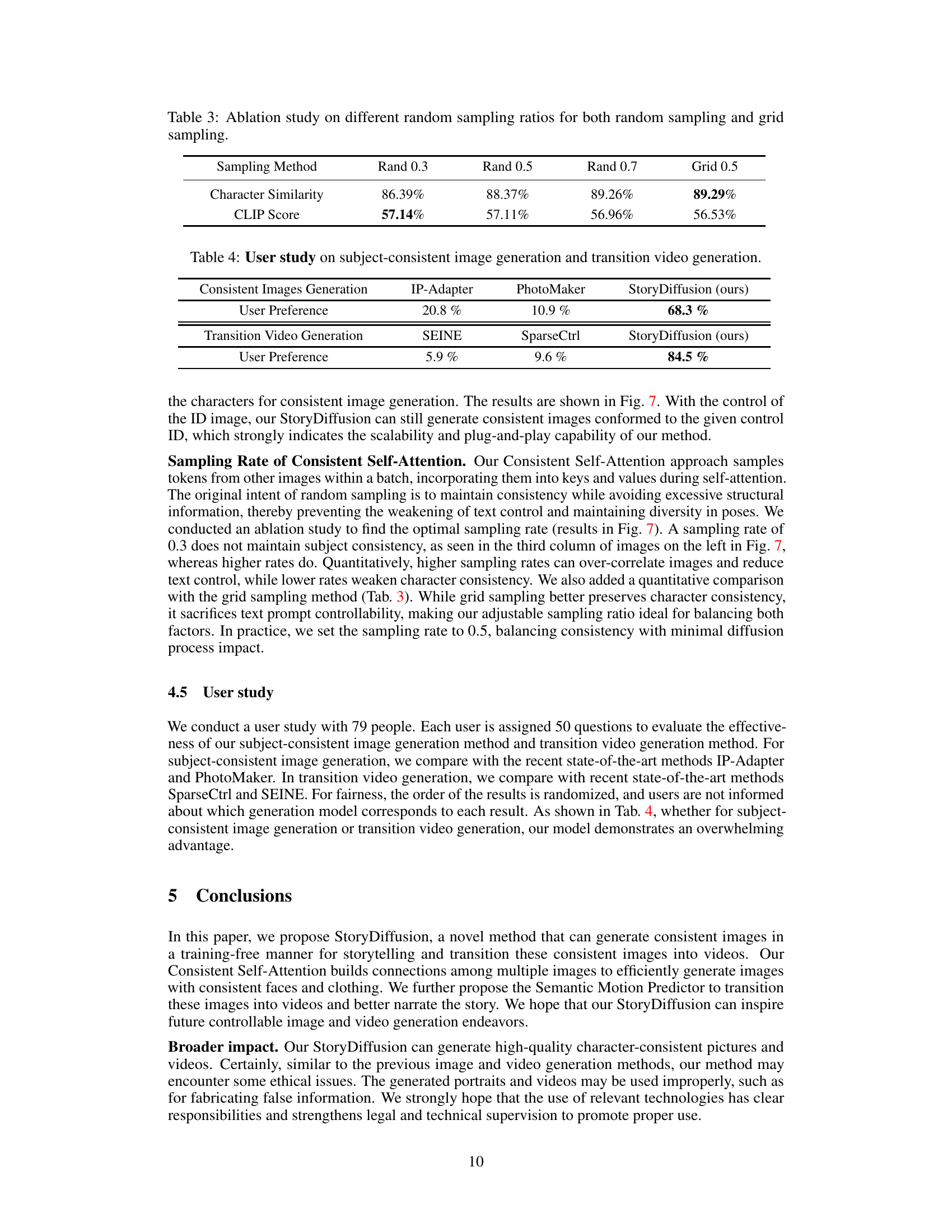
This table presents the results of an ablation study conducted to determine the optimal random sampling rate for the Consistent Self-Attention module. Two sampling methods were compared: random sampling and grid sampling, each tested at different rates (0.3, 0.5, 0.7 for random; 0.5 for grid). The table shows the impact of different sampling rates on character similarity and CLIP score, which are used to evaluate image consistency and quality. The results indicate an optimal sampling rate that balances character consistency and CLIP score, suggesting a trade-off between these two measures.

This table presents the results of a user study comparing the performance of StoryDiffusion against other methods in generating subject-consistent images and transition videos. The user preference scores show a strong preference for StoryDiffusion over the other methods for both tasks, highlighting its effectiveness in preserving consistency across images and videos.
Full paper#