↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Unsupervised video object segmentation is a challenging problem in computer vision, typically relying on heuristics or expensive manual annotations. Existing approaches often utilize instantaneous motion information (optical flow), which can be noisy and incomplete due to various factors like occlusion and limited object movement. These limitations motivate exploring alternative methods.
This work proposes a novel solution that uses long-term motion information from point trajectories in conjunction with optical flow. The core idea is that points belonging to the same object exhibit strong motion correlation over time, which can be captured using a loss function inspired by subspace clustering. The proposed loss function encourages the grouping of trajectories into low-rank matrices, reflecting the coherent motion patterns of objects. The method is demonstrated to outperform existing techniques on standard motion-based segmentation benchmarks, showcasing the power of integrating long-term motion information into unsupervised video object segmentation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to unsupervised video object segmentation that leverages both short-term (optical flow) and long-term (point trajectories) motion information. It addresses the limitations of prior methods which rely solely on instantaneous motion and introduces a new loss function enabling end-to-end training of segmentation networks. This opens up new avenues for research in unsupervised learning for video understanding and potentially other applications involving motion analysis.
Visual Insights#

This figure illustrates how the motion of points belonging to the same object can be linearly dependent and represented in a low-rank matrix. A triangle rotating over three frames is used as an example. Although the rotation speed is not constant, and therefore, individual point positions and flow vectors are complex and hard to model, each point’s motion within the triangle is still a linear combination of the three vertices’ motions. This demonstrates the principle behind the low-rank assumption made for trajectory-based loss calculation in the paper.
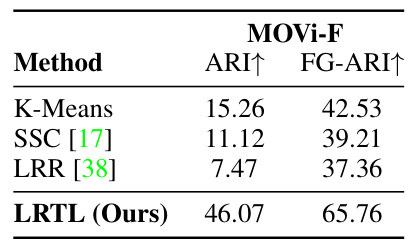
This table compares the performance of the proposed method (LRTL) against several baseline methods for unsupervised motion segmentation. The comparison uses the adjusted Rand index (ARI) and foreground adjusted Rand index (FG-ARI) metrics to evaluate the accuracy of the clustering results. The results show that the proposed LRTL method significantly outperforms existing subspace clustering approaches like K-Means, SSC, and LLR, demonstrating the effectiveness of the proposed loss function for unsupervised motion segmentation.
In-depth insights#
Long-Term Motion#
The concept of “Long-Term Motion” in the context of video object segmentation offers a compelling advantage over traditional approaches that rely solely on instantaneous motion cues like optical flow. Long-term trajectories, by tracking point movements over extended periods, capture subtle and complex motion patterns often missed by short-term analyses. This is particularly important for scenarios involving intermittent motion, occlusions, or complex object interactions where instantaneous motion may be misleading or incomplete. The key challenge, however, lies in effectively representing and leveraging these trajectories within a segmentation framework. The paper’s novel loss function addresses this by assuming that points belonging to the same object will exhibit correlated motion over time, which can be represented as a low-rank matrix. This formulation elegantly handles the variability and complexity of long-term movement and offers a robust way to supervise a segmentation network without explicit labels. The effectiveness of this strategy is demonstrated by the improved performance on standard benchmarks, showing the significant contribution of long-term motion data. While the approach requires careful consideration of sparsity and noise in trajectory data, the results highlight the potential for future research to explore richer temporal information for improved video understanding.
Subspace Clustering#
The section on ‘Subspace Clustering’ reveals a crucial insight into the paper’s methodology. It highlights the inspiration drawn from subspace clustering techniques, which posit that data points originate from distinct subspaces. This is directly relevant to the task of motion segmentation, as it assumes that the trajectories of points belonging to the same object can be represented as a linear combination of other points within that object’s subspace. The authors acknowledge that prior subspace clustering methods often suffer from limitations such as sensitivity to noise, reliance on specialized optimization procedures, and quadratic memory complexities. Their proposed approach addresses these drawbacks by directly supervising a neural network to learn low-rank representations, thus avoiding computationally expensive subspace reconstruction steps and enabling end-to-end training. This innovative approach offers a compelling alternative, paving the way for more efficient and scalable motion segmentation.
Loss Function Design#
The paper’s approach to unsupervised video object segmentation hinges on a cleverly designed loss function that leverages both optical flow and point trajectories. Optical flow provides dense, instantaneous motion information, while point trajectories offer sparse but temporally extended motion data. The loss function is not a simple combination, but rather a synergistic approach. For optical flow, a linear parametric model is used to represent the flow within segmented regions, and the residual from this model forms part of the loss. This encourages the network to learn coherent motion patterns within object segments. For point trajectories, a low-rank constraint is imposed via singular value decomposition. This encourages the grouping of trajectories belonging to the same object, as their collective motion can be approximated by a low-dimensional subspace. The combination of these losses—optical flow and trajectory—is key, as it leverages both the spatial coherence and temporal consistency of object motion. By combining these losses, the network is pushed to learn meaningful segmentations based on motion, even without explicit labels.
Unsupervised VOS#
Unsupervised Video Object Segmentation (VOS) presents a significant challenge in computer vision, aiming to segment objects in videos without relying on manual annotations or pre-defined object masks. The core difficulty lies in learning discriminative features from purely visual information, without the guidance provided by supervised learning. Approaches often leverage inherent motion cues via optical flow or point trajectories, exploiting the Gestalt principle of common fate to group pixels or points exhibiting correlated motion. However, instantaneous motion cues alone can be ambiguous, as unrelated objects might coincidentally share similar short-term movements. Therefore, incorporating long-term temporal information from point trajectories becomes crucial, offering richer contextual cues to disambiguate object boundaries and handle occlusions, thus improving segmentation accuracy. A key research direction is developing robust and efficient methods to fuse long-term temporal dynamics with short-term visual patterns to effectively segment objects in a fully unsupervised manner. The exploration of various loss functions and network architectures geared towards this unsupervised learning paradigm constitutes a core focus for future advancements in the field.
Future Work#
The paper’s omission of a dedicated ‘Future Work’ section is notable. However, considering the presented research, several promising avenues are apparent. Extending the approach to handle more complex motion patterns, beyond the rigid body assumption, is crucial for broader applicability. This could involve incorporating more sophisticated motion models or exploring techniques like non-negative matrix factorization to represent diverse motion dynamics. Investigating the impact of noise and occlusion in point trajectories on segmentation accuracy is another key direction. Robustness to these challenges would significantly enhance the method’s real-world performance. Exploring different point tracking algorithms and their influence on the final results is also warranted. The current method relies on CoTracker; a comparative analysis with other state-of-the-art trackers could identify more robust and accurate ways of capturing long-term motion information. Finally, the paper uses a two-stage process combining flow and point trajectories. A fully unified approach, potentially incorporating both data sources into a single network architecture, could lead to greater efficiency and improved performance. This would require careful design of the network and the loss function to effectively leverage both instantaneous and long-term motion cues. These are crucial future directions to strengthen the research’s contribution.
More visual insights#
More on figures
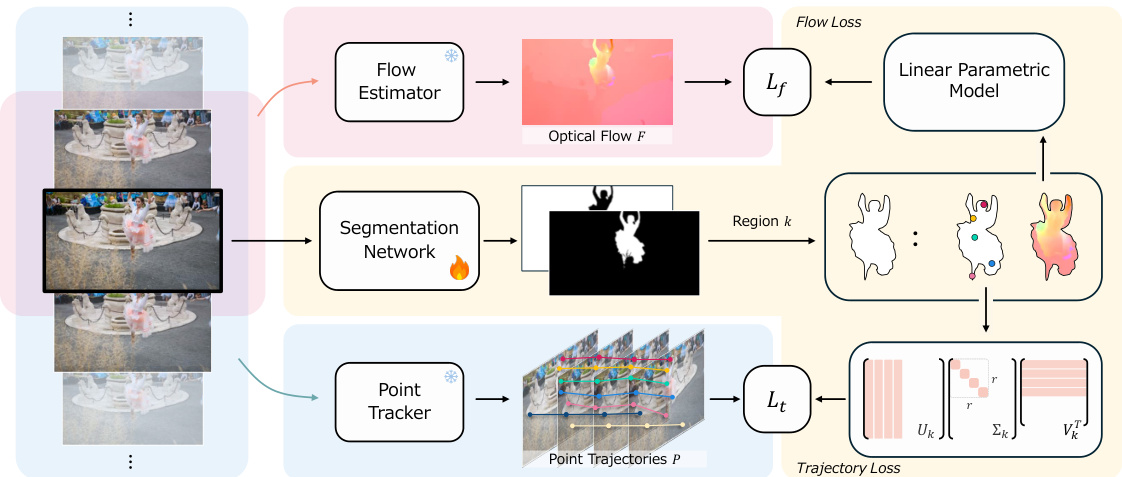
This figure illustrates the overall architecture of the proposed approach for self-supervised video object segmentation. It uses both optical flow (short-term motion) and point trajectories (long-term motion) to supervise a segmentation network. The optical flow and trajectories are processed separately, feeding into their respective loss functions (flow loss and trajectory loss). The combined loss guides the segmentation network to produce masks that align with the motion patterns of objects. The network outputs a segmentation mask, and the loss functions measure the accuracy of the segmentation against the motion information. Off-the-shelf methods are used to extract optical flow and track points.
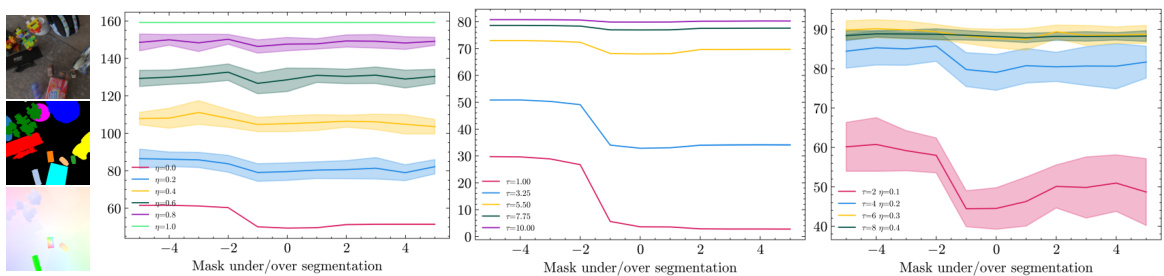
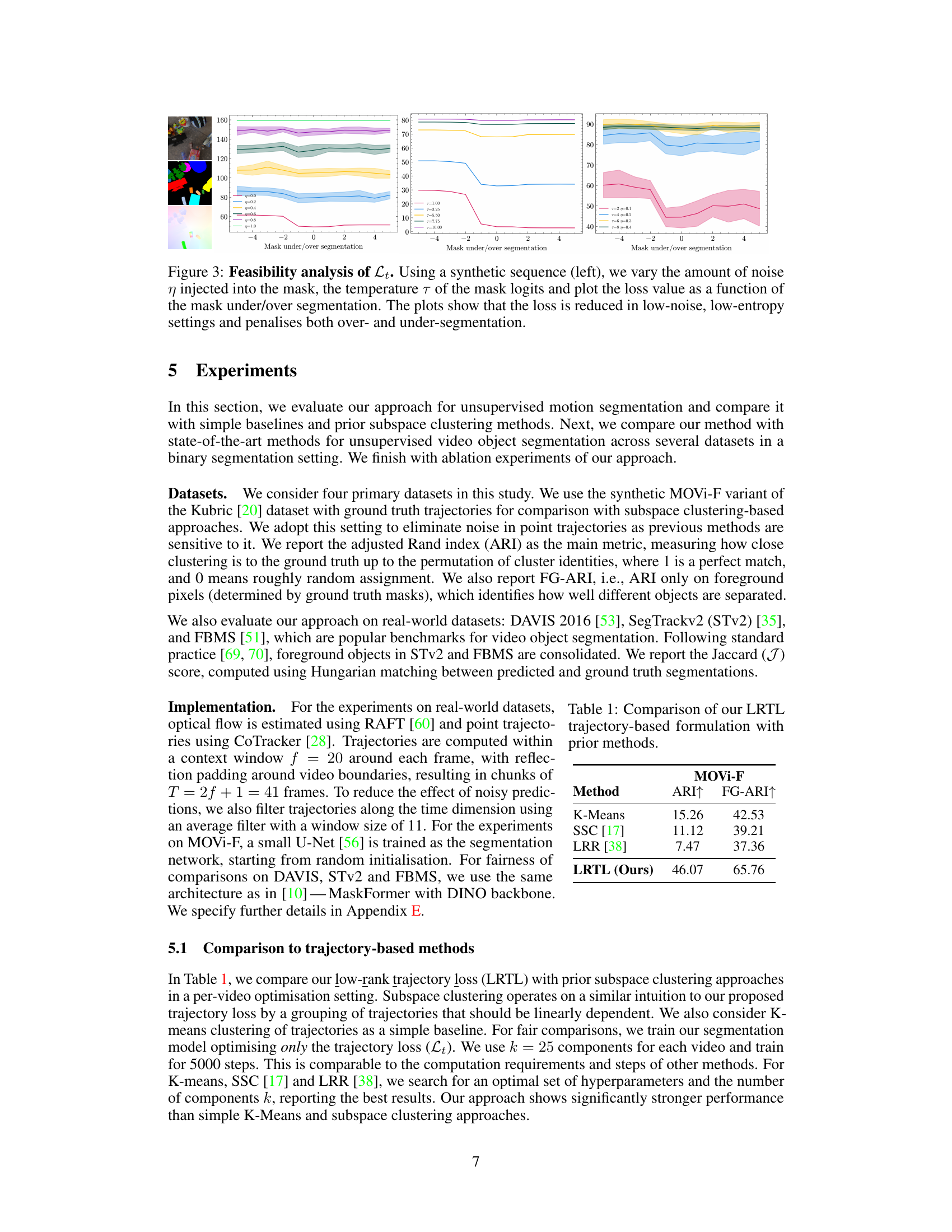
This figure shows the results of a feasibility study on the proposed trajectory loss (Lt). Using a synthetic video sequence, the authors varied three factors: noise added to the segmentation masks (η), temperature of the mask logits (τ), and the degree of under/over-segmentation (number of objects merged or split). The plots show how the trajectory loss changes with these alterations, demonstrating that the loss is minimized when masks have low noise and entropy (τ = 0, η = 0) and penalizes deviations such as merging or splitting object masks.

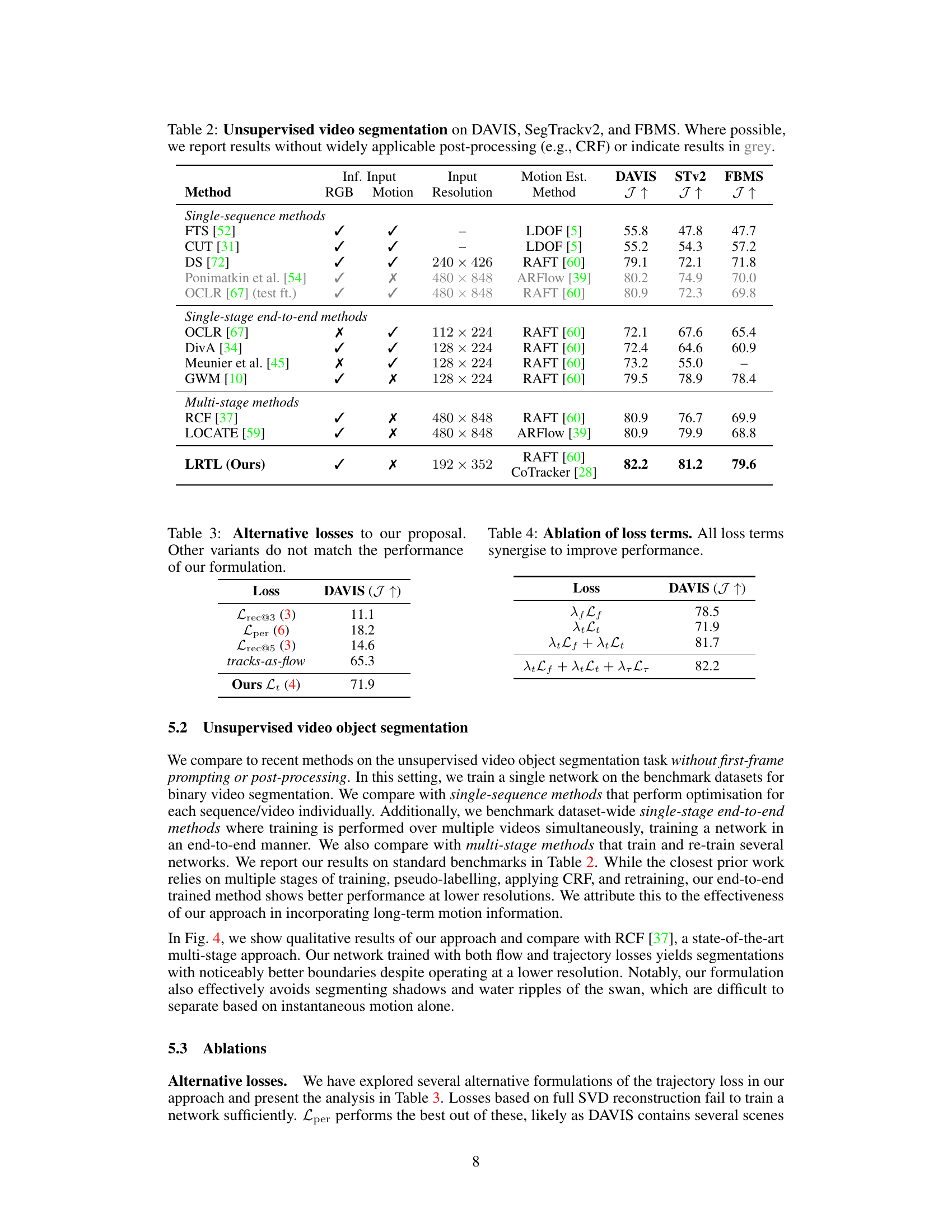
This figure compares the qualitative results of the proposed method against the state-of-the-art RCF method on the DAVIS dataset. The comparison highlights that the proposed method, despite using lower resolution, achieves slightly better boundary segmentation and avoids incorrectly segmenting shadows or water ripples, demonstrating its effectiveness in unsupervised video object segmentation.

This figure compares the qualitative results of the proposed method with the state-of-the-art multi-stage method RCF on the DAVIS dataset. The comparison shows that the proposed method achieves better segmentation results, particularly in terms of boundary precision and the ability to avoid segmenting irrelevant elements such as shadows and water ripples.
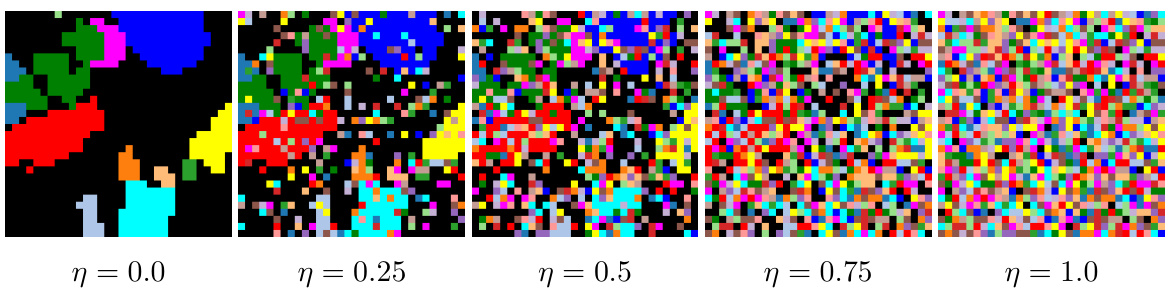
This figure shows the results of a feasibility study on the proposed trajectory loss (Lt). Using a synthetic dataset with ground truth trajectories and segmentation masks, the authors systematically introduced noise and structural errors into the masks (under/over-segmentation). The plots illustrate how the trajectory loss changes with varying levels of noise (η), temperature (τ), and structural errors in the masks, demonstrating its sensitivity to these factors and preference for accurate segmentations.
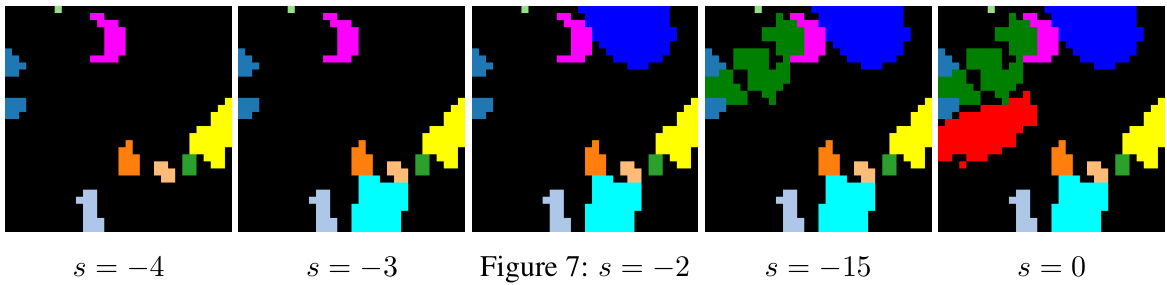
This figure shows example masks with structural alterations that simulate under-segmentation. The parameter ’s’ controls how many objects are removed from the mask and set to the background. The alteration is applied in a systematic way. ’s = -4’ represents significant under-segmentation, while ’s = 0’ shows the original mask. This visualization helps demonstrate the impact of under-segmentation on the loss function in the context of object segmentation using trajectory data.
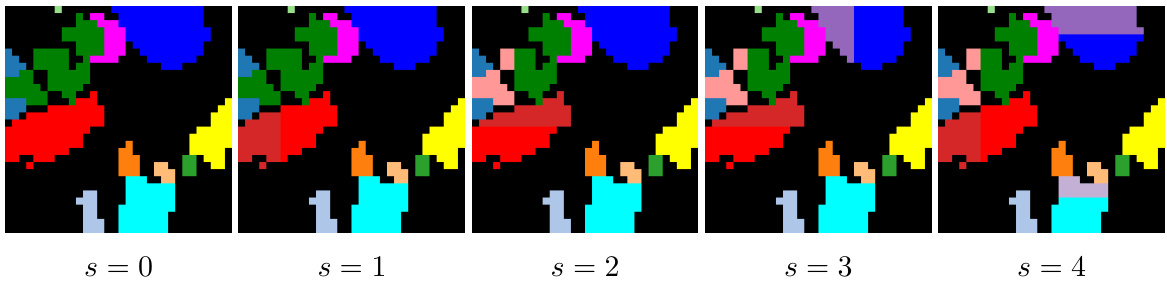
This figure shows an example of a structural mask alteration used to simulate over-segmentation. The alteration splits existing object masks into two parts along either the x or y-axis at random. The parameter ’s’ controls the number of such splits, with s=0 representing no alteration and increasing values of ’s’ resulting in increasingly fragmented masks.
More on tables
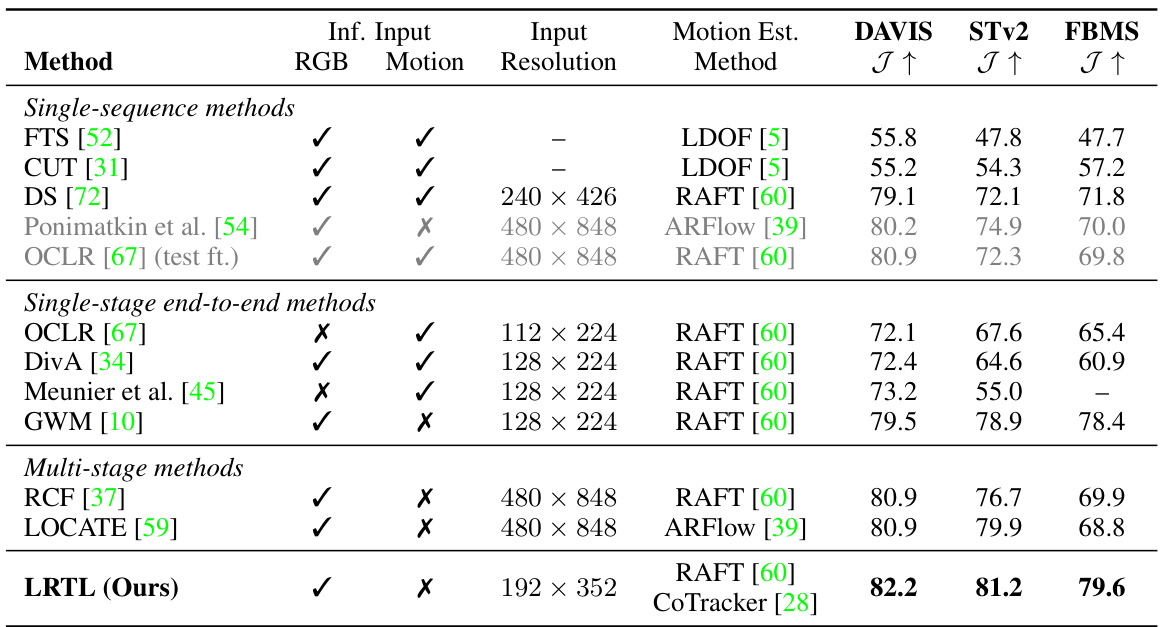
This table compares the proposed method (LRTL) with various unsupervised video object segmentation methods across three benchmark datasets (DAVIS, SegTrackv2, and FBMS). The comparison includes single-sequence, single-stage end-to-end, and multi-stage methods. The table shows the input modality (RGB, Motion), input resolution, motion estimation method used, and the resulting Jaccard index (J↑) scores for each dataset.

This table compares the performance of different loss functions for training the video object segmentation model using point trajectories. The loss functions are variations of the proposed loss, each designed to capture different aspects of trajectory motion. The results demonstrate that the proposed loss function outperforms the alternative formulations, indicating its effectiveness for unsupervised video object segmentation.
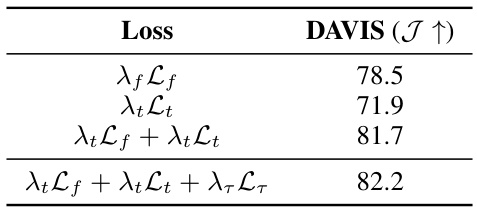
This table presents an ablation study on the proposed loss function. It shows the performance of the model on the DAVIS dataset using different combinations of the optical flow loss (Lf), trajectory loss (Lt), and temporal smoothing loss (Lr). The results demonstrate that all three loss terms contribute positively to the overall performance, with the combination of all three losses achieving the highest Jaccard score (J).
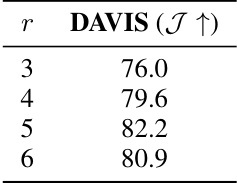
This table shows the result of the experiment to find the optimal rank (r) of the trajectory matrix used in the loss function. The rank controls the degrees of freedom in the system and implicitly controls the assumptions about the types of motion and cameras used to capture sequences. The table shows that a rank of 5 provides the best performance (82.2 on DAVIS J↑) indicating that it is sufficient to group and explain simple motions.
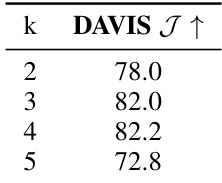
This table presents the results of an ablation study on the influence of the number of predicted components (k) before merging on the DAVIS J↑ metric. The experiment varied k (number of components before merging) and measured the resulting performance on the DAVIS dataset. The results show that k=4 yields the best performance.
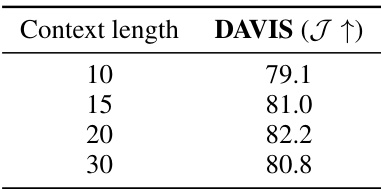
This table shows the impact of varying the context length (temporal window) used for analyzing point trajectories on the performance of the video object segmentation task, measured by the Jaccard index (J) on the DAVIS dataset. A longer context allows for the consideration of more temporal motion information, but excessively long contexts might introduce noise or irrelevant information. The results show an optimal context length around 20 frames, suggesting a balance between capturing sufficient temporal information and avoiding excessive noise.
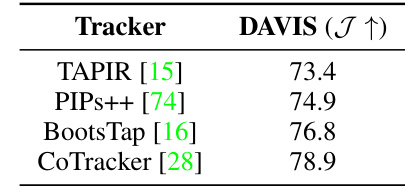
This table shows the performance of the proposed method using different point trackers on the DAVIS dataset. The Jaccard index (J) is used as the evaluation metric. The results indicate that the CoTracker outperforms other trackers, achieving the highest Jaccard index.

This table presents the performance of different segmentation network architectures on the DAVIS dataset. The results show that using a stronger backbone network, such as MaskFormer with DINO, leads to better performance compared to using a simpler architecture such as UNet.
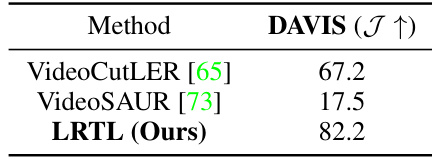
This table compares the proposed LRTL method with several state-of-the-art unsupervised video object segmentation methods on three benchmark datasets: DAVIS 2016, SegTrackv2, and FBMS. The comparison includes single-sequence, single-stage end-to-end, and multi-stage methods. The table shows the Jaccard index (J) for each method on each dataset, highlighting the superior performance of LRTL, particularly in the absence of extensive post-processing.
Full paper#