↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Visual classification models struggle to generalize to unseen data and discover novel categories. This paper explores the relationship between logical reasoning and deep learning generalization. The core problem addressed is the difficulty of generalizing deep learning models to unseen data and categories, a significant limitation hindering their broader applicability. Existing regularization techniques like L2 regularization offer limited interpretability and often don’t sufficiently address this issue.
To tackle this, the authors propose L-Reg, a novel logical regularization term. L-Reg bridges logical analysis to image classification, reducing model complexity by balancing feature distribution and filtering redundant information. Experiments show that L-Reg consistently improves generalization across multi-domain scenarios and generalized category discovery. This demonstrates the effectiveness of logical reasoning for enhancing generalization and interpretability in visual classification, highlighting L-Reg’s practical utility and potential for future improvements.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on visual classification and generalization. It introduces a novel approach that bridges logical reasoning and deep learning, leading to improved model interpretability and generalization capabilities. This addresses a critical challenge in the field, paving the way for more robust and reliable visual AI systems. The proposed L-Reg method is easy to implement and shows strong results, making it directly applicable to many existing frameworks. Its use in real-world scenarios with complex, unlabeled data is particularly relevant, creating new avenues for practical application and further research.
Visual Insights#

The figure displays GradCAM visualizations, highlighting activated regions in a model trained for visual classification. It compares the results of a model trained with standard L2 regularization versus one with the proposed L-Reg (logical regularization). The visualizations are shown for both seen (training) and unseen (testing) domains. Focus is on the classification of the ‘person’ class, comparing how salient features (e.g., faces) are detected with and without the use of L-Reg. The implication is that L-Reg leads to more focused and interpretable attention on relevant features, improving generalization.
This table presents the results of multi-domain generalization (mDG) experiments on several benchmark datasets. It compares the performance of the proposed method (GMDG + L-Reg) against various existing mDG methods, both non-ensemble and ensemble-based. The best performing method for each dataset is shown in bold, and improvements or decreases in performance compared to the GMDG baseline are highlighted in red. The average performance across all datasets is also provided.
In-depth insights#
Logical Reg. Benefits#
The heading ‘Logical Reg. Benefits’ suggests an exploration of the advantages of using logical reasoning within a regularization framework for a machine learning model, likely in the context of image classification. Improved generalization is a key expected benefit, allowing the model to perform better on unseen data or novel categories. This likely stems from the regularization’s ability to reduce model complexity, focusing on salient features and filtering out noise. Another benefit would be enhanced interpretability, making the model’s decision-making process more transparent and understandable by highlighting the specific features driving classification. The theoretical analysis likely supports these claims by demonstrating how the logical regularization leads to a more balanced feature distribution and reduces the number of extreme weights. This approach contrasts with traditional regularization methods (e.g., L2) which may lack such benefits. Overall, the anticipated benefits suggest a superior approach to model training, offering more robust and transparent performance.
Generalization Across Tasks#
Generalization across tasks examines a model’s ability to apply knowledge learned from one task to perform well on another, related but distinct task. This is crucial for building truly intelligent systems that aren’t limited to narrow, specialized functions. Strong generalization implies the model has learned underlying principles or representations transferable to different contexts, not simply memorizing task-specific details. Factors influencing this include the similarity between tasks (e.g., shared data representations or underlying structures), the model’s architecture (capable of representing high-level abstractions), and the training methodology (e.g., multi-task learning or transfer learning techniques). Measuring generalization across tasks can involve various metrics, assessing performance on unseen tasks, evaluating the efficiency of knowledge transfer, and analyzing the model’s ability to adapt to new task distributions. Research in this area seeks to develop methods that promote better generalization, leading to more robust and flexible AI applications that can easily adapt and learn from new experiences without extensive retraining.
L-Reg Interpretability#
The concept of ‘L-Reg Interpretability’ centers on the capacity of the proposed Logical Regularization (L-Reg) method to enhance the transparency and understandability of deep learning models in visual classification tasks. L-Reg achieves this by promoting a balanced feature distribution and reducing the complexity of classifier weights. This reduction isn’t merely a decrease in the number of weights but a refinement, effectively removing redundant or less relevant features. The resulting models exhibit a focus on salient, meaningful features, making the decision-making process of the classifier more interpretable. Visualizations such as GradCAM are used to demonstrate that L-Reg guides the model toward identifying crucial, class-specific features — for example, faces when classifying humans. This interpretability is particularly valuable in generalization scenarios (e.g., multi-domain and generalized category discovery) where understanding the model’s decision-making process for unseen data is vital. The improved interpretability is not only insightful but also directly contributes to the enhanced generalization performance of L-Reg, solidifying its practical efficacy.
Future Research#
Future research directions stemming from this work on logical reasoning regularization (L-Reg) for visual classification could explore several promising avenues. Extending L-Reg’s applicability to other visual tasks beyond image classification, such as object detection or semantic segmentation, is a key area. Investigating the impact of different architectural choices on L-Reg’s effectiveness, including the depth at which it’s applied and the interaction with various backbone networks, would provide valuable insights. A deeper dive into theoretical analysis to better understand the relationship between logical reasoning and generalization could offer a stronger foundation for future improvements. Furthermore, empirical studies on larger, more diverse datasets are crucial to confirm the robustness and generalizability of L-Reg across a wide range of real-world scenarios. Finally, exploring methods to automatically learn or optimize the semantic supports used by L-Reg, rather than relying on hand-crafted features, could significantly improve its scalability and applicability.
L-Reg Limitations#
The core limitation of L-Reg stems from its reliance on the assumption that each dimension of the latent feature vector Z represents an independent semantic. This independence is not always guaranteed, particularly in shallower layers of deep neural networks. When this assumption is violated, L-Reg’s effectiveness in improving generalization can be compromised. Specifically, it might cause a slight degradation in performance on known classes while improving on unknown classes. This trade-off highlights the need for careful consideration of the layer from which the semantic features are extracted; applying L-Reg to deeper layers, where semantic independence is more likely, is crucial for maximizing the benefits. The paper acknowledges this limitation and suggests further research to explore methods for explicitly enforcing semantic independence in Z, potentially using techniques such as orthogonality regularization to enhance the performance of L-Reg across all classes.
More visual insights#
More on figures
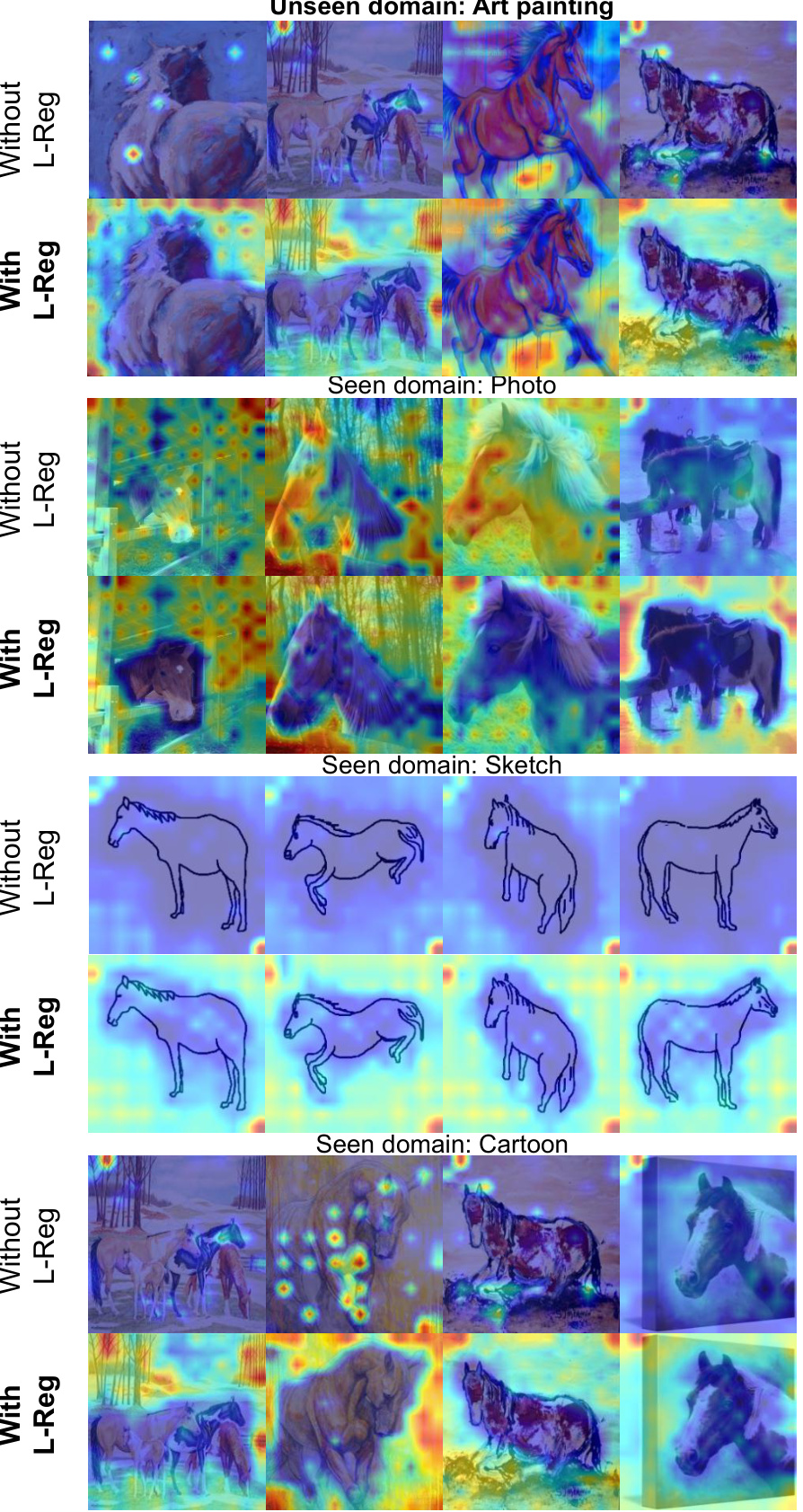
This figure shows GradCAM visualizations for the ‘person’ class using the GMDG baseline model with and without L-Reg. The visualizations highlight which parts of the image the model focuses on to identify the ‘person’ class in seen and unseen domains. The key difference shown is that with L-Reg, the model focuses more on facial features, indicating improved interpretability and generalization.
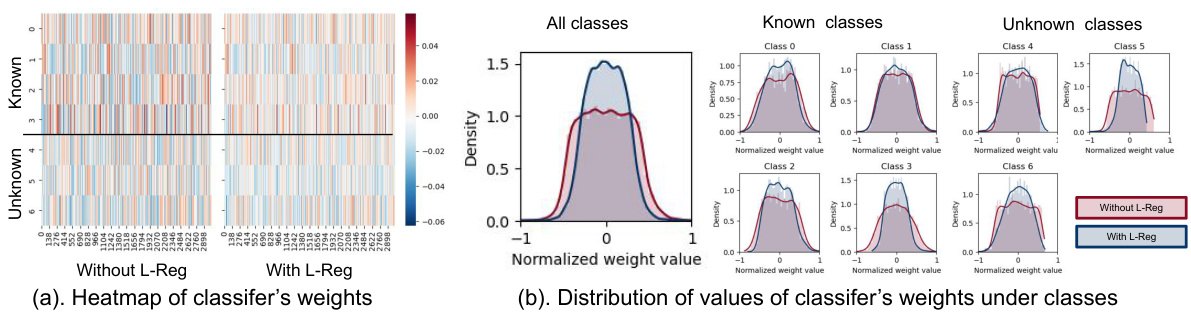
The figure visualizes the effects of L-Reg on the classifier’s weights in a multi-domain generalization plus generalized category discovery setting using the PACS dataset. Subfigure (a) shows heatmaps of the classifier weights, revealing a more balanced distribution and fewer extreme values with L-Reg. Subfigure (b) presents the distribution of classifier weight values for each class, demonstrating that L-Reg leads to simpler classifiers with reduced complexity.
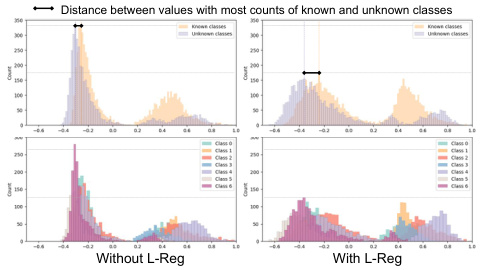
This figure visualizes the distribution of latent features from models trained with and without L-Reg on the PACS dataset under the multi-domain generalization and generalized category discovery setting. It shows that L-Reg leads to a more balanced distribution of features, reducing complexity and improving generalization.
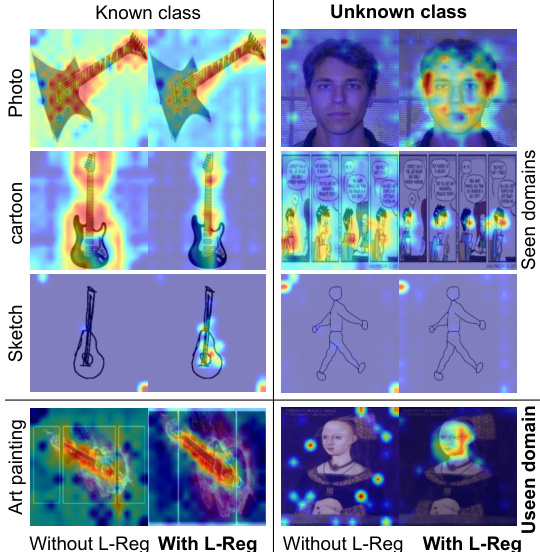
This figure shows GradCAM visualizations comparing a model trained with L2 regularization only and a model trained with both L2 and L-Reg. The visualizations highlight the model’s attention when classifying the ‘person’ category across images from both seen and unseen domains. The L-Reg model demonstrates a focus on facial features even when presented with diverse image styles.
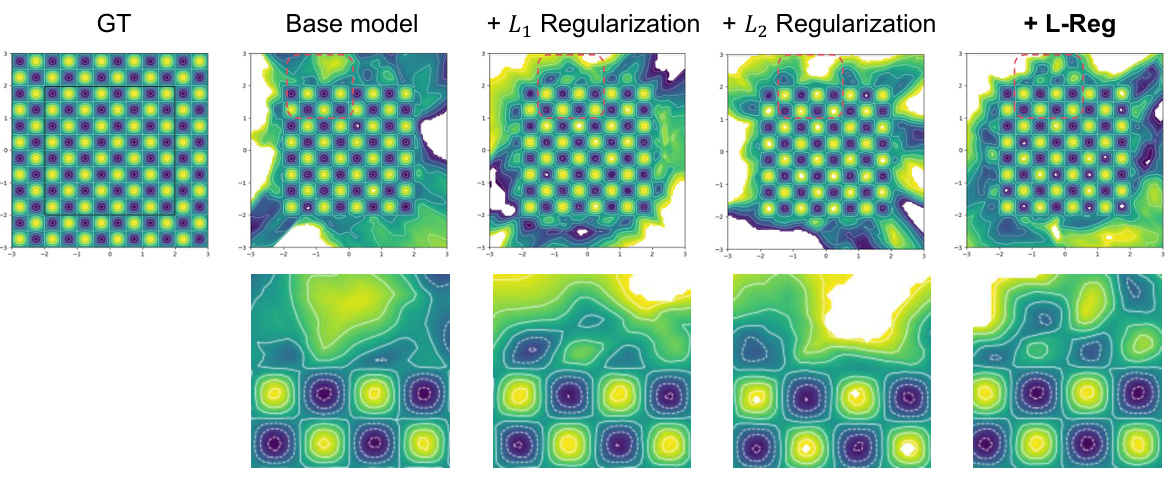
This figure compares the prediction visualizations of a Multilayer Perceptron (MLP) model trained with different regularization techniques. The ground truth (GT) is shown alongside results from a base model, models regularized with L1 and L2, and a model using the proposed L-Reg. The visualizations highlight the differences in how each regularization method affects the model’s ability to learn and generalize from the training data. The visualizations show the model’s output across the entire input space and is a contour plot showing the model’s prediction values. The differences in the contour plots suggest that L-Reg might lead to better generalization performance than the other methods.
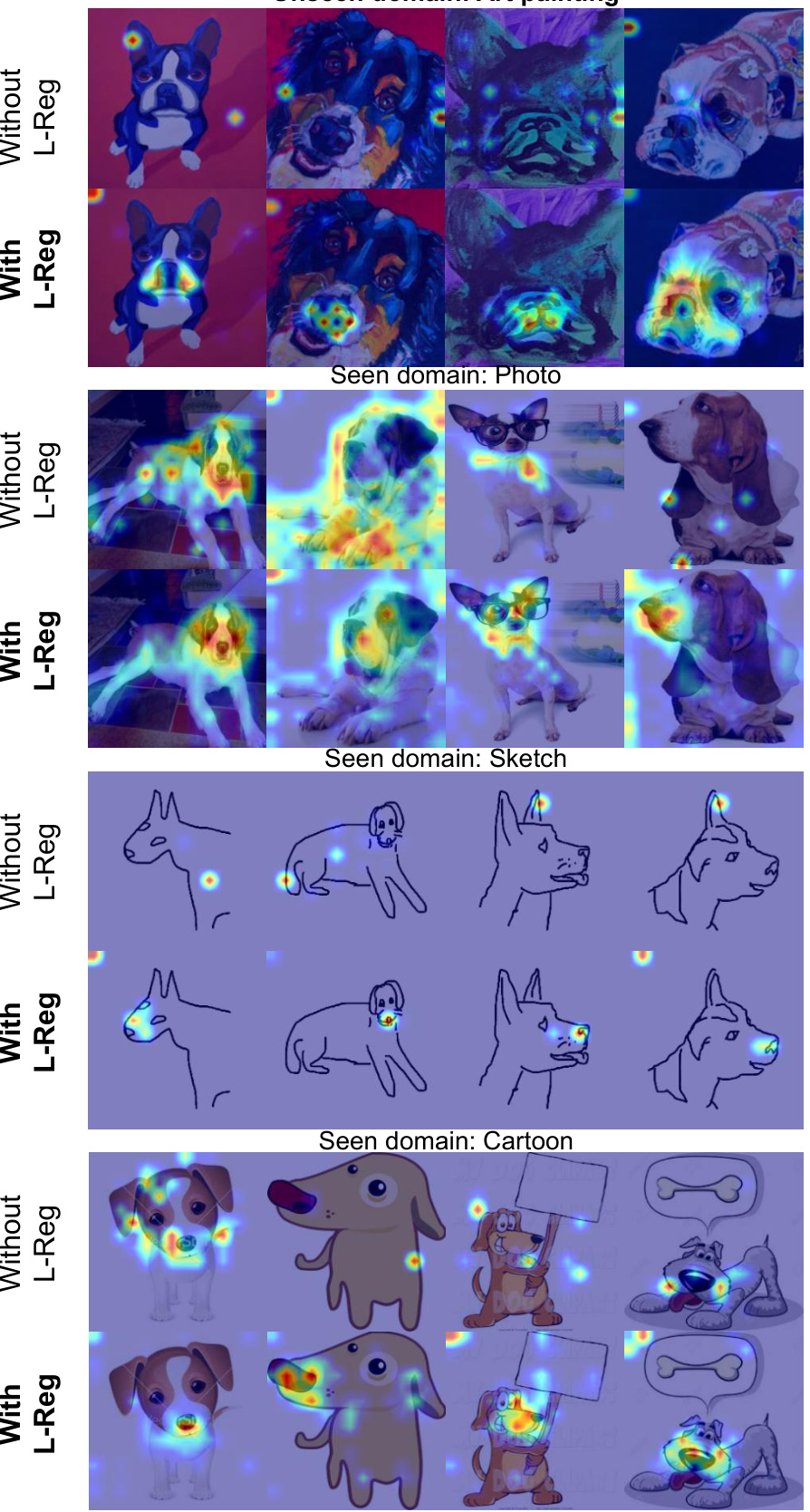
This figure shows GradCAM visualizations, highlighting the model’s attention during classification. The top row illustrates a model trained without L-Reg (logical reasoning regularization), showcasing ambiguous attention across both seen and unseen domains when classifying a person. The bottom row shows a model trained with L-Reg, demonstrating focused attention on facial features—a key characteristic for identifying a person—regardless of domain. The comparison highlights L-Reg’s ability to improve model interpretability and generalization.
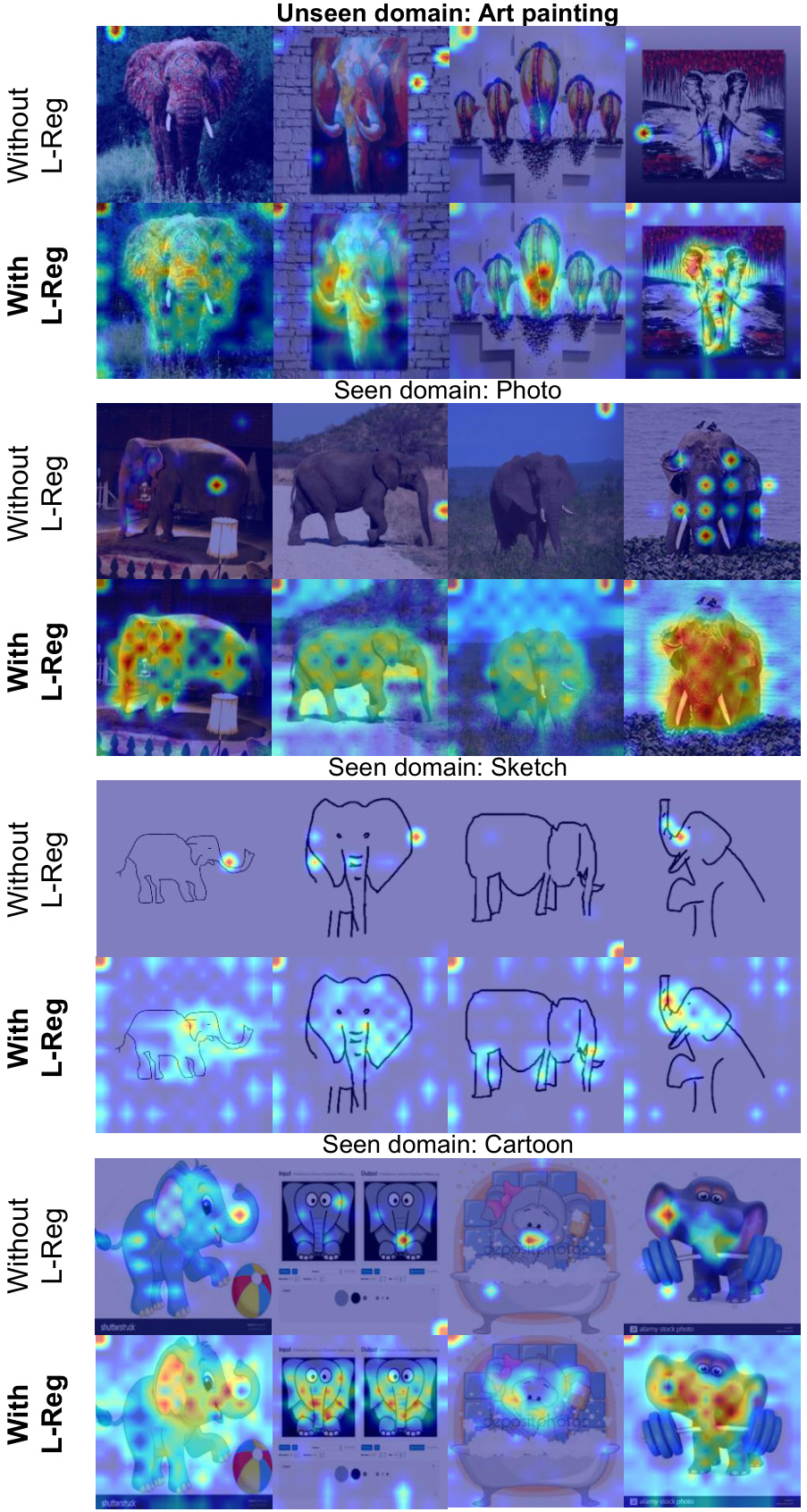
This figure shows GradCAM visualizations for the known class ’elephant’ using GMDG with and without L-Reg. The results demonstrate that L-Reg improves generalization across seen and unseen domains by focusing on salient features (long noses, teeth, and big ears). However, it also highlights a limitation where this approach may compromise performance in domains with less distinctive features (e.g., sketch).
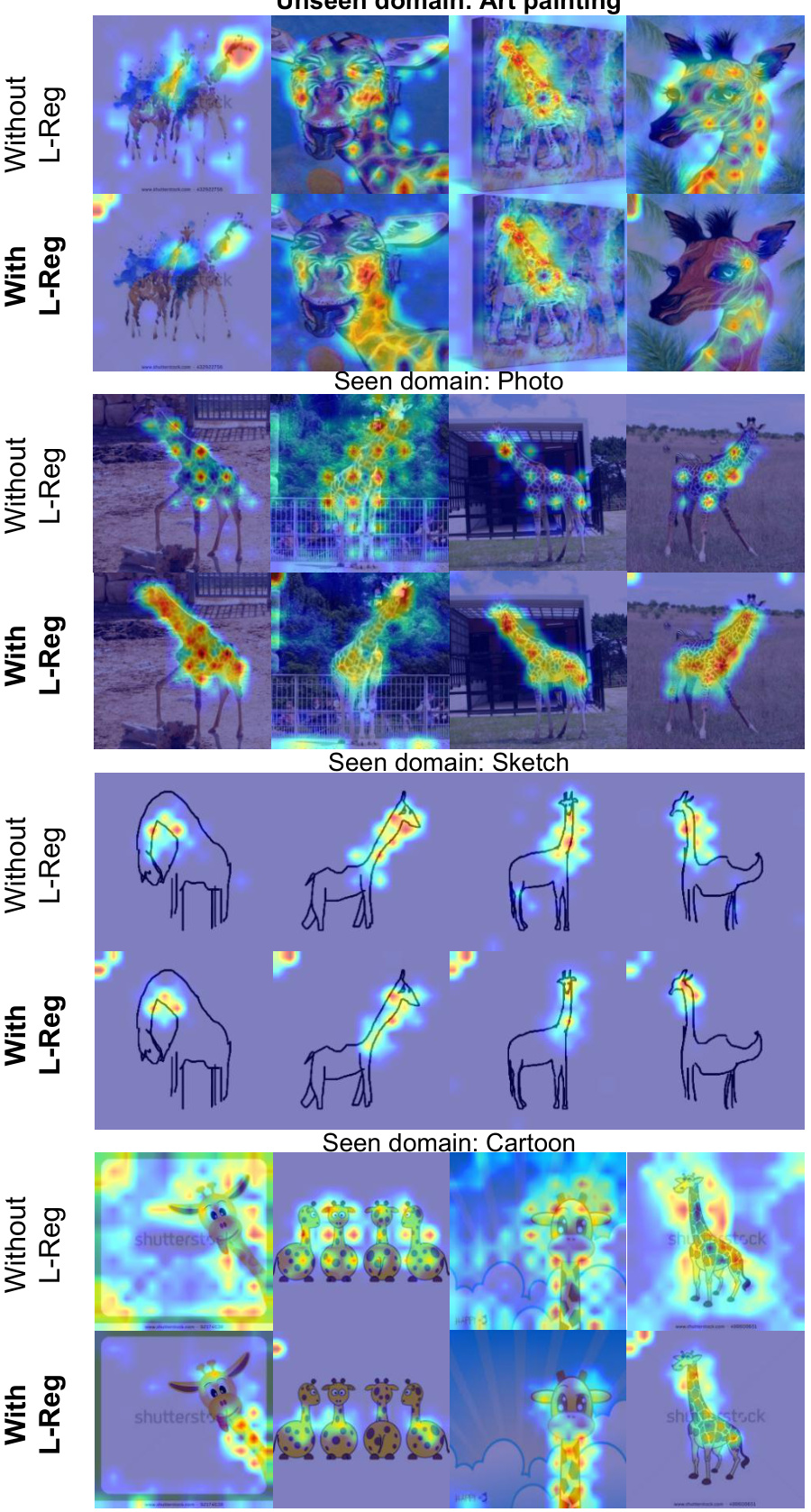
This figure shows GradCAM visualizations for the classification of giraffes in the PACS dataset. The model was trained using the GMDG method, both with and without L-Reg. The visualizations highlight the areas of the images that are most important for classification. In the model trained with L-Reg, the visualizations clearly focus on the long necks of the giraffes, regardless of whether the images are from the seen or unseen domains. This illustrates the model’s improved ability to generalize to unseen data when using L-Reg.
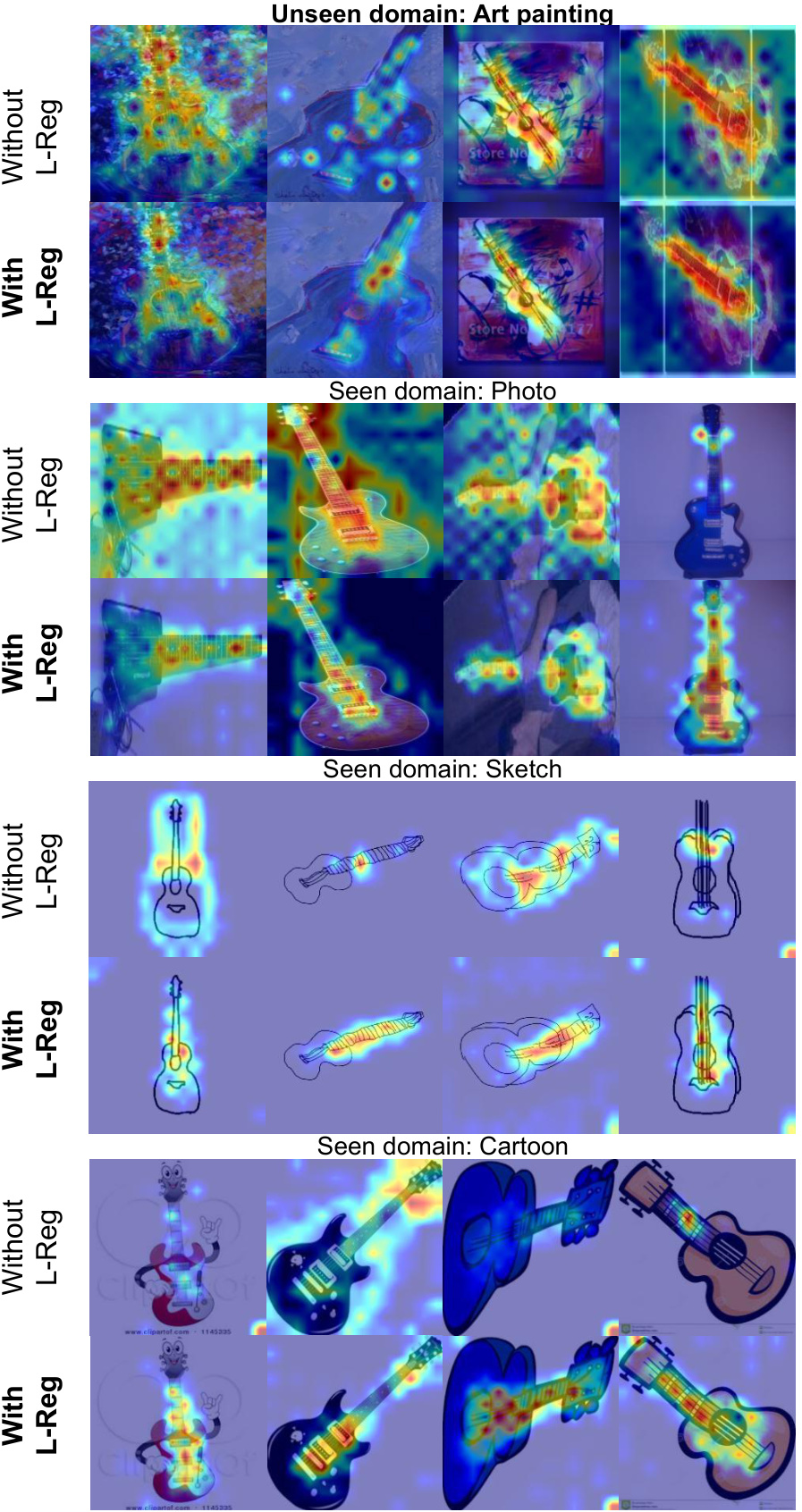
The figure shows GradCAM visualizations for the ‘person’ class in seen and unseen domains. The visualizations compare models trained with and without the proposed Logical Reasoning Regularization (L-Reg). The goal is to illustrate how L-Reg improves the model’s ability to identify salient features (such as faces) for classifying the ‘person’ class, even in unseen domains, leading to better generalization.
This figure uses GradCAM to visualize the features used by a model for classifying the ‘person’ class. It shows visualizations for images from both seen and unseen domains. The left column shows the model trained with only L2 regularization; the right column shows the model trained with both L2 and the proposed L-Reg. The visualization highlights the difference in attention: the L-Reg model focuses more on salient features like faces, showcasing improved interpretability and generalization.
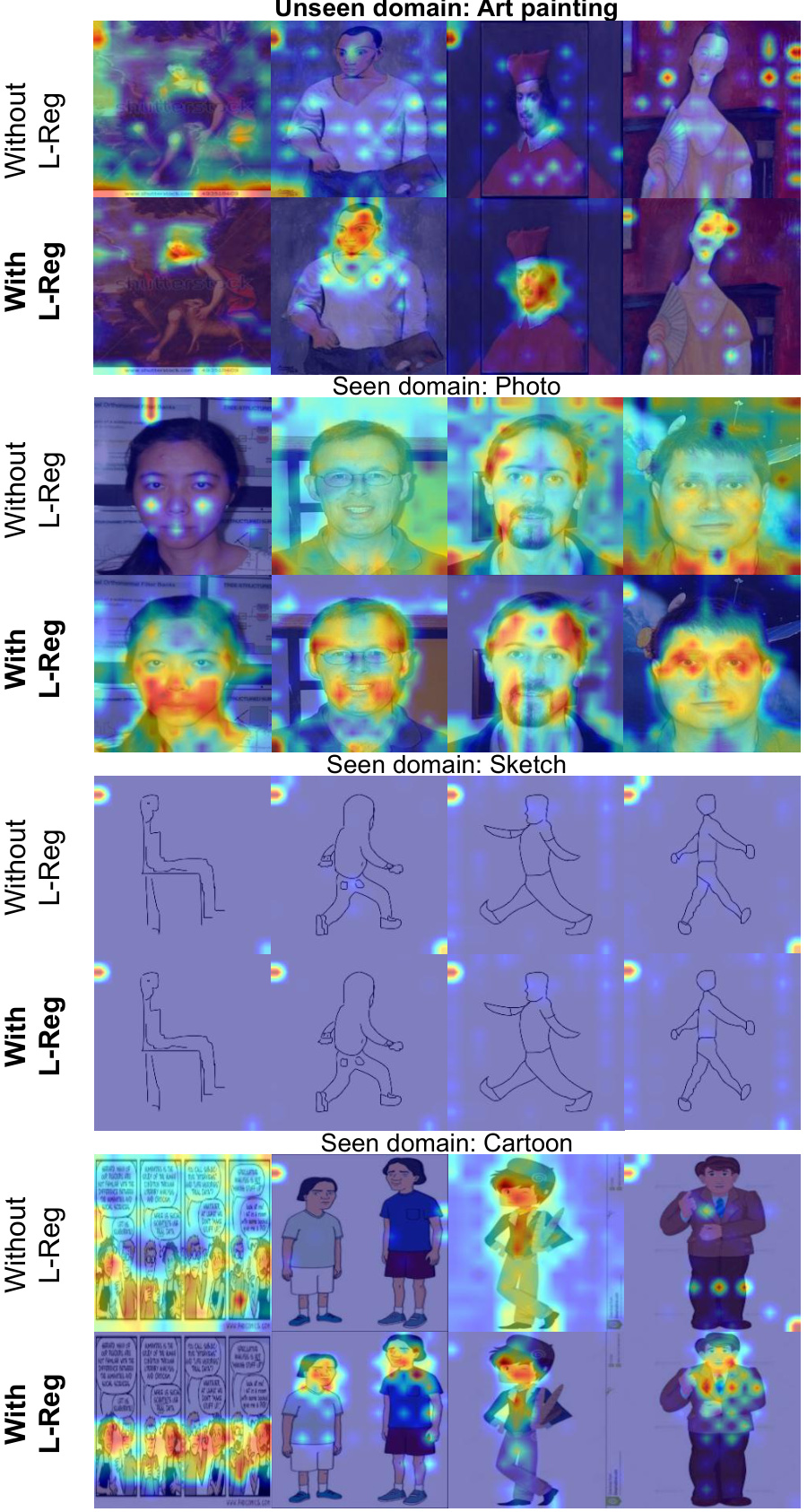
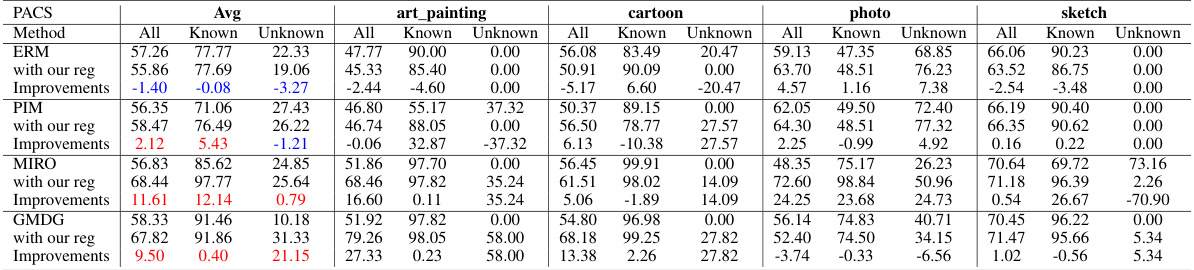
This figure shows GradCAM visualizations, highlighting the model’s attention areas when classifying images. The visualizations are separated into two groups: images trained without L-Reg and images trained with L-Reg. Each group shows a comparison across four different domains (art painting, photo, sketch, and cartoon). The visualizations reveal that images with L-Reg consistently focuses on human faces as salient features, improving the model’s interpretability and generalization to unseen data, such as images from unseen domains or novel classes.
More on tables
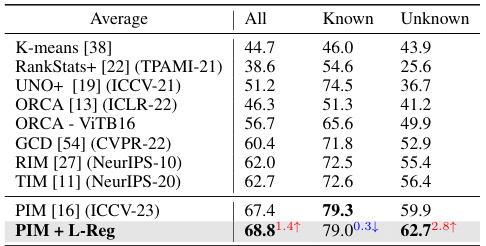
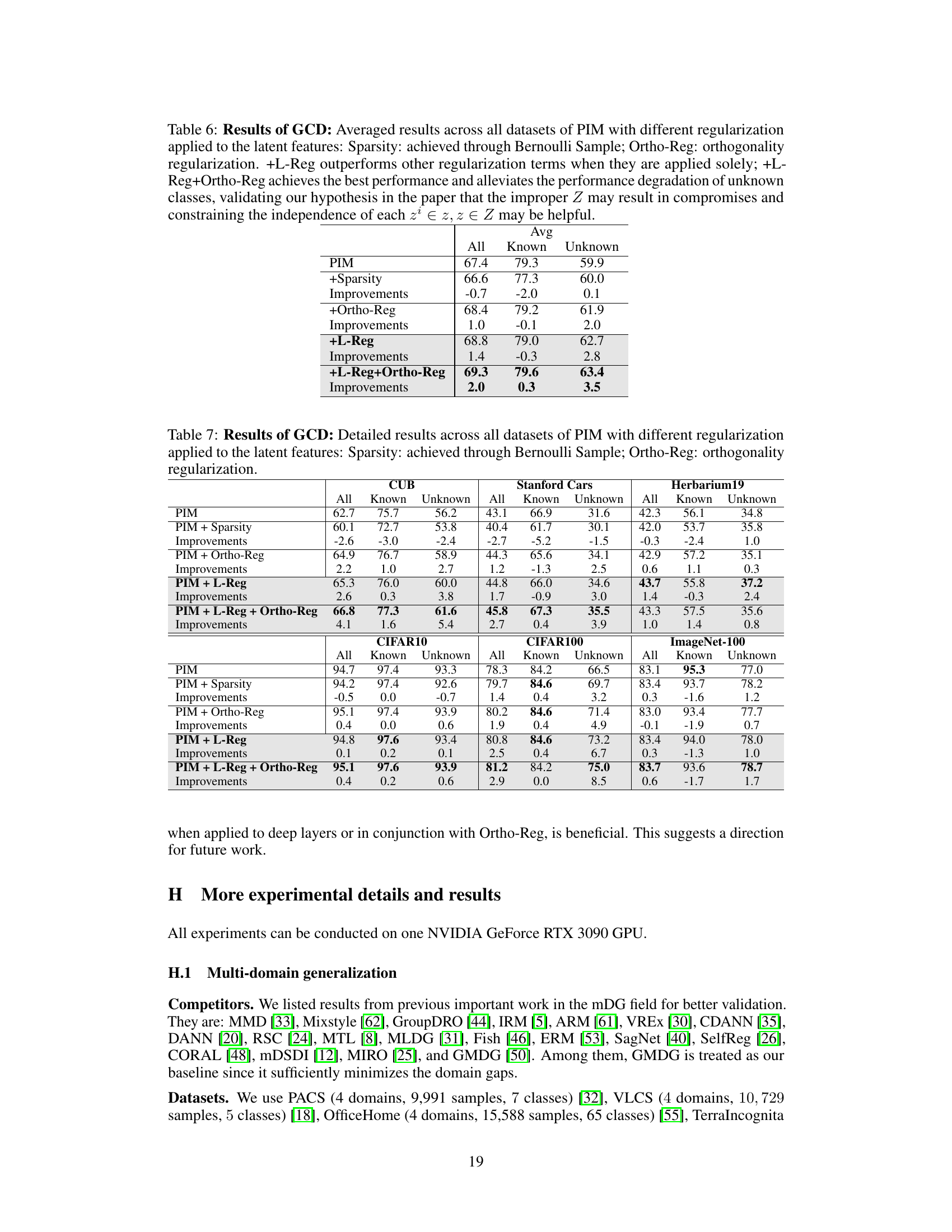
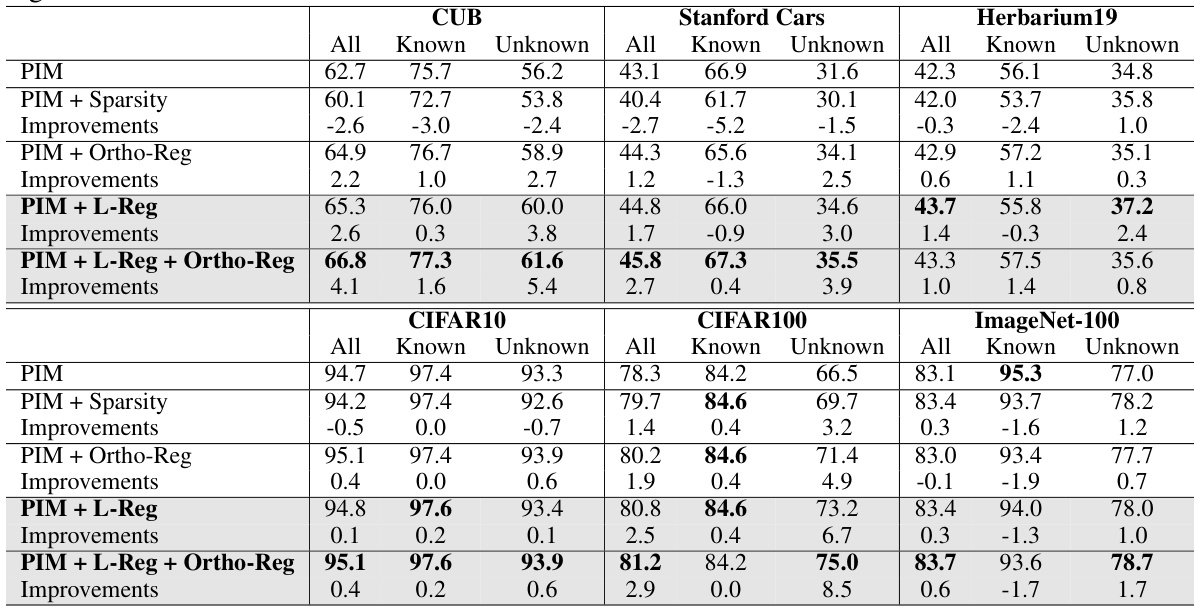
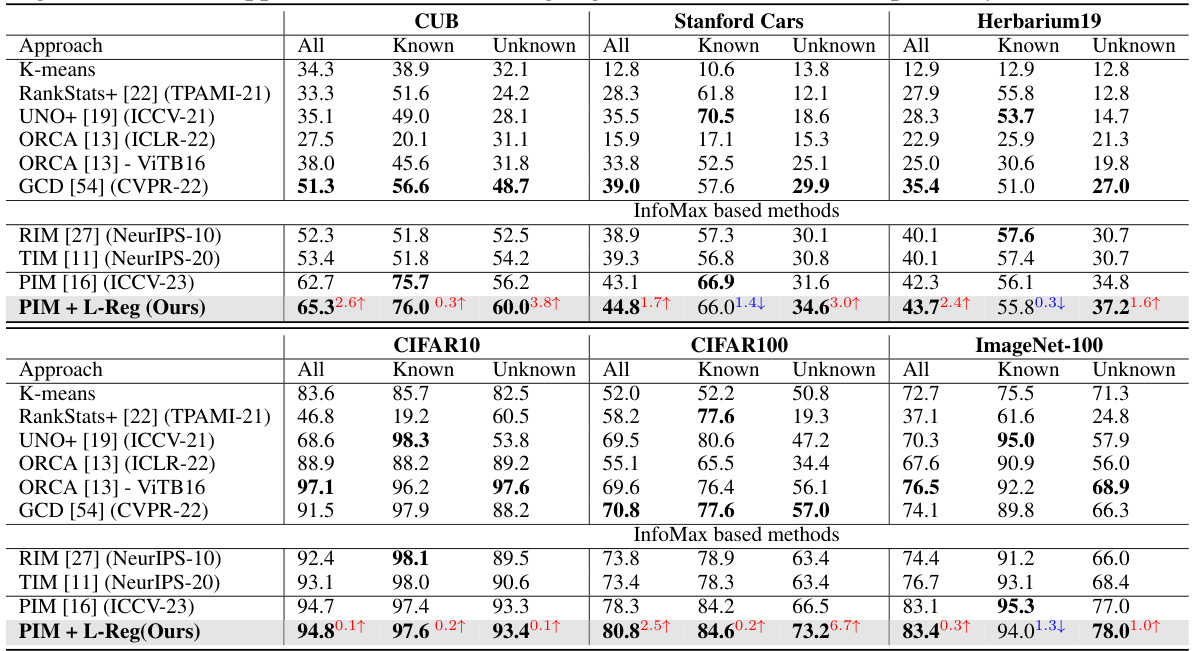
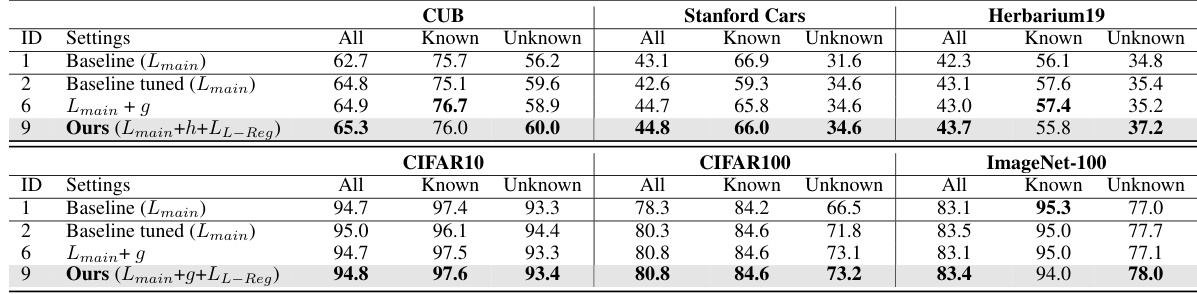
This table shows the average accuracy results across six image datasets (CIFAR10, CIFAR100, ImageNet-100, CUB, Stanford Cars, and Herbarium19) for the Generalized Category Discovery (GCD) task. The results are broken down by the model’s performance on all classes, known classes, and unknown classes. The table compares the performance of the PIM model (a baseline method for GCD) with and without the addition of the L-Reg (Logical Reasoning Regularization). Improvements from the PIM model are highlighted in red, and degradations are shown in blue. The results demonstrate that L-Reg improves overall performance, particularly for unknown classes, despite slightly impacting the accuracy of known classes in some cases.
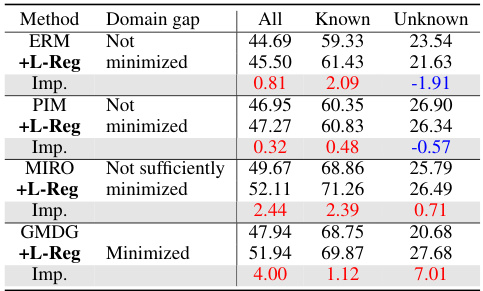
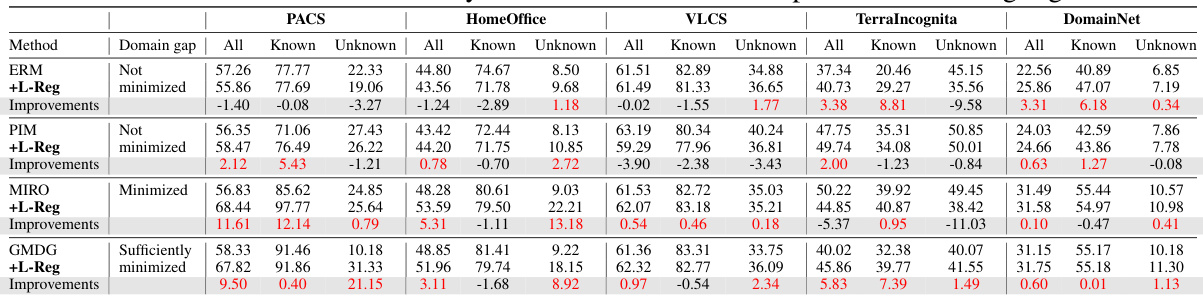
This table presents the average accuracy results across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet) for the multi-domain generalization plus generalized category discovery (mDG+GCD) task. It compares the performance of several methods (ERM, PIM, MIRO, GMDG) with and without the proposed L-Reg. The accuracy is broken down into three categories: all classes, known classes, and unknown classes. The ‘Domain gap’ column indicates whether the domain gap was minimized or not sufficiently minimized during training. The improvements or degradations brought by L-Reg compared to each baseline model are highlighted in red and blue, respectively. The table shows that in the minimized domain gap settings, the addition of L-Reg consistently improved performance on all three metrics.
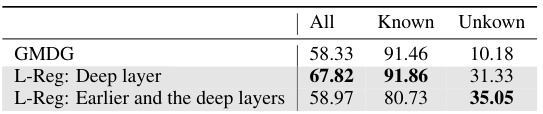
This table presents the average results of applying the L-Reg (Logic Regularization) technique to different layers of a deep learning model for the task of domain generalization on the PACS dataset. It shows the impact of applying L-Reg to only the deep layers versus applying it to both earlier and deeper layers of the model. The results are compared against a baseline GMDG (Generalized Multi-Domain Generalization) model without L-Reg. The metrics reported are overall accuracy, accuracy on known classes, and accuracy on unknown classes.

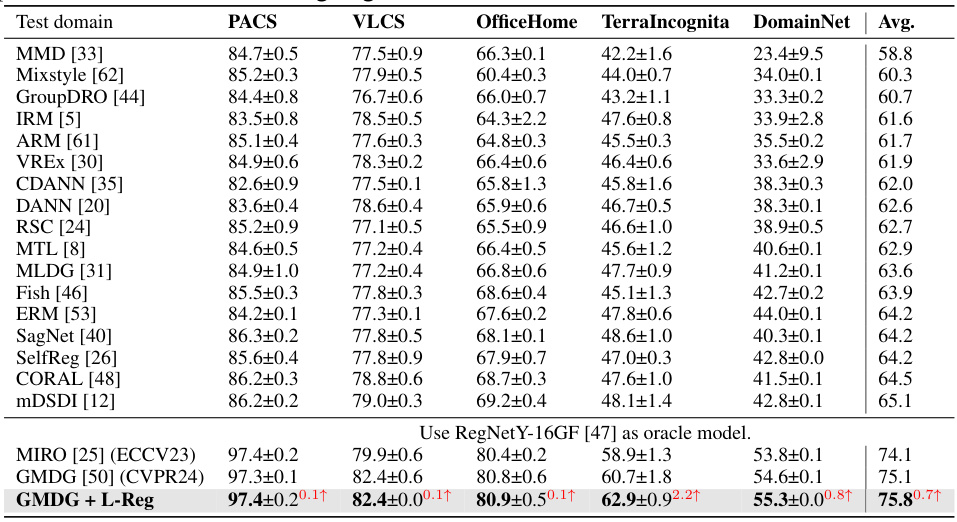
This table compares the proposed method’s multi-domain generalization performance against several existing methods across five datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table shows the average accuracy for each method on each dataset. The best performing method in each dataset group (non-ensemble and ensemble) is highlighted in bold. The table also highlights in red whether the proposed method improves or degrades the performance compared to the GMDG baseline.
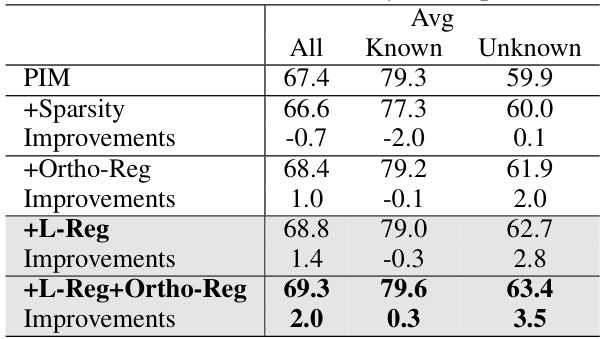
This table presents the average accuracy results across various datasets for the Generalized Category Discovery (GCD) task using the PIM model with and without L-Reg. The accuracy is broken down into three categories: overall, known classes, and unknown classes. Positive improvements from using L-Reg are highlighted in red, while negative impacts are shown in blue. This gives a concise overview of the performance gains or losses from applying L-Reg to the PIM model in different datasets and classes.
This table compares the performance of the proposed L-Reg method with various existing multi-domain generalization (mDG) methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The best-performing method in each dataset and each group (ensemble vs. non-ensemble) is highlighted in bold. The table shows the average accuracy across different test domains for each method, and importantly, highlights in red where the proposed method improves or degrades upon the existing state-of-the-art method GMDG.

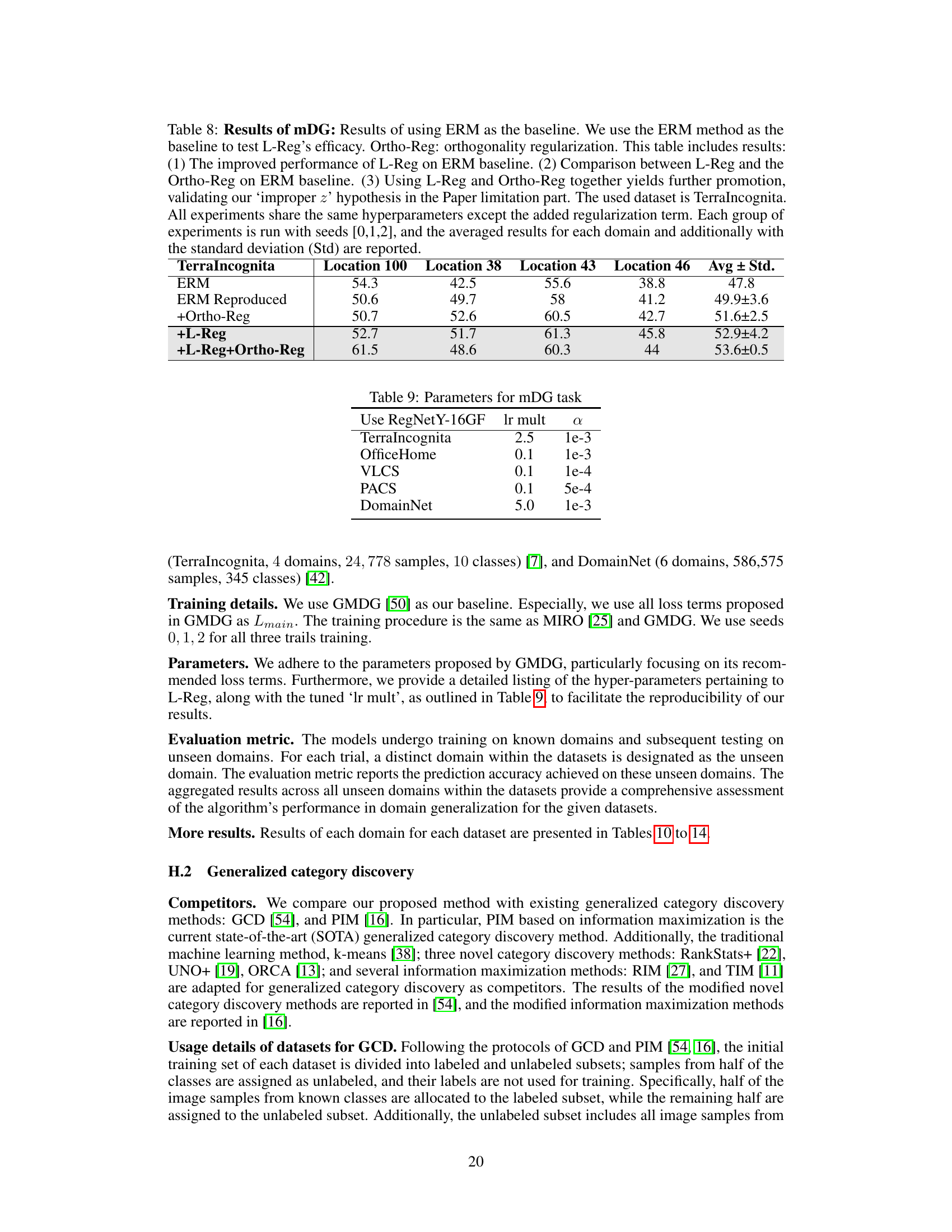
This table presents the results of multi-domain generalization experiments using the ERM (Empirical Risk Minimization) baseline on the TerraIncognita dataset. It compares the performance of ERM alone against ERM with L-Reg (Logical Regularization), ERM with Ortho-Reg (Orthogonality Regularization), and ERM with both L-Reg and Ortho-Reg. The goal is to demonstrate the effectiveness of L-Reg in improving generalization performance, even when compared to other regularization techniques.
This table presents a comparison of the proposed method’s performance against existing state-of-the-art multi-domain generalization (mDG) methods. The comparison includes both non-ensemble and ensemble methods. The best performing method in each category is highlighted in bold, and improvements or degradations relative to the GMDG baseline are indicated in red.
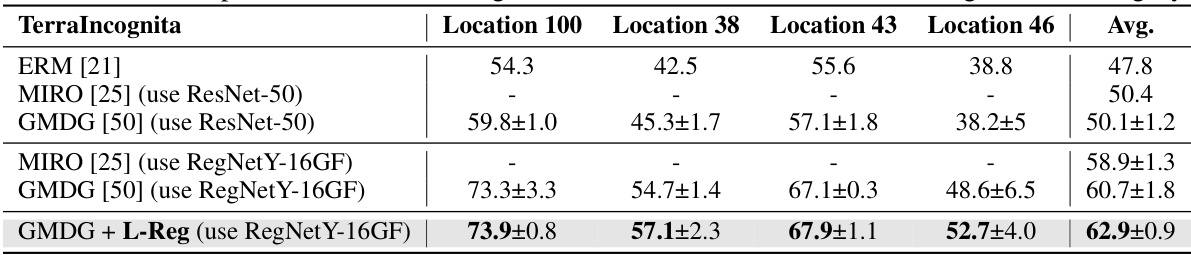
This table compares the proposed method’s performance on multi-domain generalization (mDG) tasks against several state-of-the-art baselines across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table shows the average accuracy for each method on each dataset, highlighting the best-performing method in each group. Improvements or reductions compared to the GMDG baseline are indicated in red. This provides a quantitative evaluation of the proposed method’s ability to generalize across different domains.
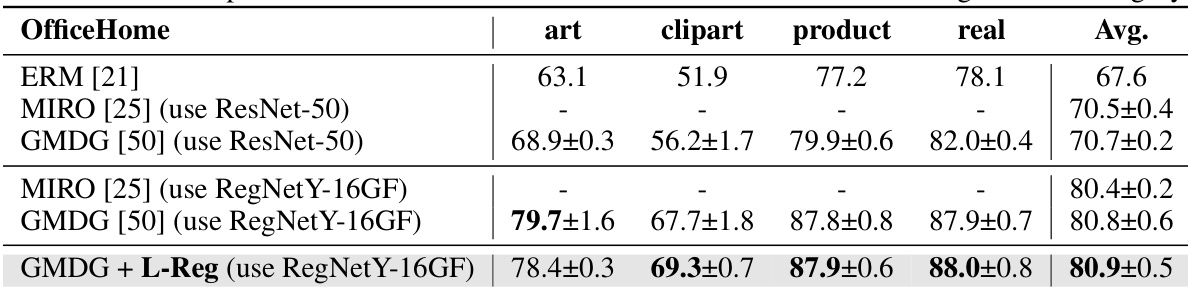
This table presents the results of multi-domain generalization (mDG) experiments on five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). It compares the performance of the proposed method (GMDG + L-Reg) against several state-of-the-art mDG methods, both ensemble and non-ensemble. The table shows the average accuracy across different test domains for each method, highlighting the best performance in each group and indicating improvements or degradations compared to the GMDG baseline.
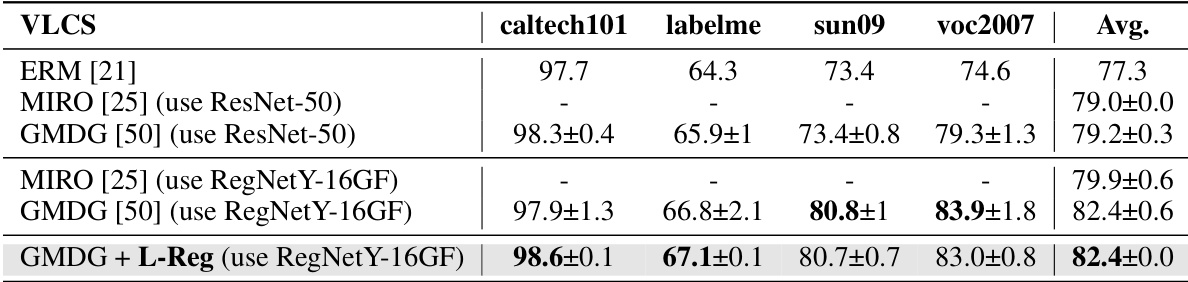
This table presents a comparison of the proposed method’s performance on multi-domain generalization (mDG) tasks against various existing non-ensemble and ensemble methods. The results are shown for five real-world benchmark datasets: PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet. The best performing method for each dataset and method category (non-ensemble, ensemble) is highlighted in bold. The table also highlights (in red) whether the proposed method shows improvement or degradation in comparison to the GMDG (generalized multi-domain generalization) baseline. This allows for easy assessment of the relative performance gains or losses achieved by the proposed approach across different datasets and in comparison to state-of-the-art techniques.
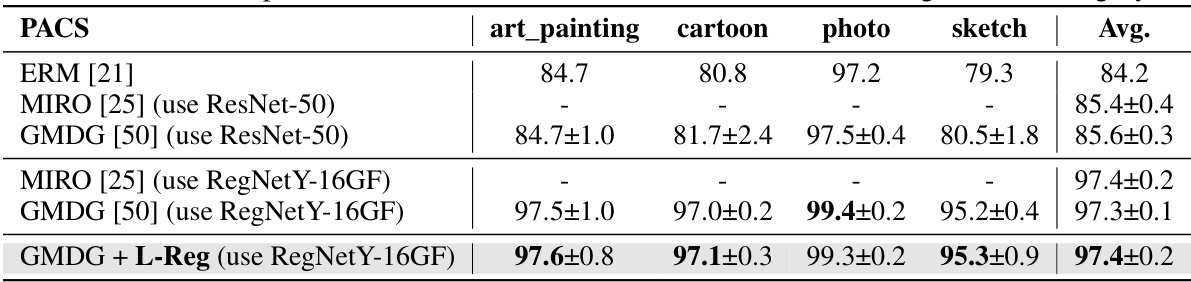
This table compares the proposed method’s multi-domain generalization (mDG) performance against various existing mDG methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The results are presented as average accuracy with standard deviation across three trials. The table highlights the best-performing method in each dataset and shows the improvement or degradation relative to the GMDG baseline when L-Reg is added. This provides a quantitative assessment of L-Reg’s impact on mDG performance.

This table compares the performance of the proposed method (GMDG + L-Reg) against several existing multi-domain generalization (mDG) methods on five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table shows the average accuracy across different test domains for each method, highlighting the best-performing method in each group. Improvements or degradations relative to the GMDG baseline are indicated. The results demonstrate the effectiveness of the proposed L-Reg in enhancing the generalization performance of GMDG, especially in scenarios where the GMDG baseline achieves relatively low accuracy.

This table compares the proposed method’s performance on multi-domain generalization (mDG) tasks against various other existing methods. The results are presented across five different benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table highlights the best performing methods for each dataset and indicates improvements or reductions in performance when using the proposed approach compared to a state-of-the-art GMDG baseline. The best results for each dataset are indicated in bold, and improvements or degradations from the GMDG baseline are highlighted in red.

This table presents a comparison of the proposed method’s performance on multi-domain generalization (mDG) tasks against several existing non-ensemble and ensemble methods. The results are shown across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The best performing method in each dataset group is highlighted in bold, and improvements or degradations relative to the GMDG baseline (a state-of-the-art method) are indicated in red.
This table compares the performance of the proposed L-Reg method with other state-of-the-art multi-domain generalization (mDG) methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table shows the average accuracy for each method on each dataset, highlighting the best-performing method in bold and indicating improvements or degradations compared to the GMDG baseline (with L-Reg). This provides a quantitative comparison to demonstrate the effectiveness of L-Reg in improving generalization performance in mDG tasks.
This table compares the proposed method’s performance on multi-domain generalization (mDG) tasks against various existing non-ensemble and ensemble methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The best performing method in each dataset group is highlighted in bold, illustrating the relative improvement or decline introduced by the proposed method compared to a strong baseline (GMDG). Red highlighting indicates performance changes relative to the GMDG baseline.
This table compares the performance of the proposed method (GMDG + L-Reg) with several other multi-domain generalization (mDG) methods on five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The results show the average accuracy across all test domains for each method and highlight the best performance within each group of methods. The table also indicates improvements or degradations compared to the GMDG baseline.
This table presents a comparison of the proposed method’s performance on multi-domain generalization (MDG) tasks against several existing MDG methods. The comparison is made across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). For each dataset and method, the average accuracy across different domains is reported. The best-performing method in each group (non-ensemble, ensemble) is highlighted in bold, and improvements or degradations relative to the GMDG baseline (a state-of-the-art method) are highlighted in red. This allows for a direct assessment of the effectiveness of the proposed method in comparison to existing approaches.
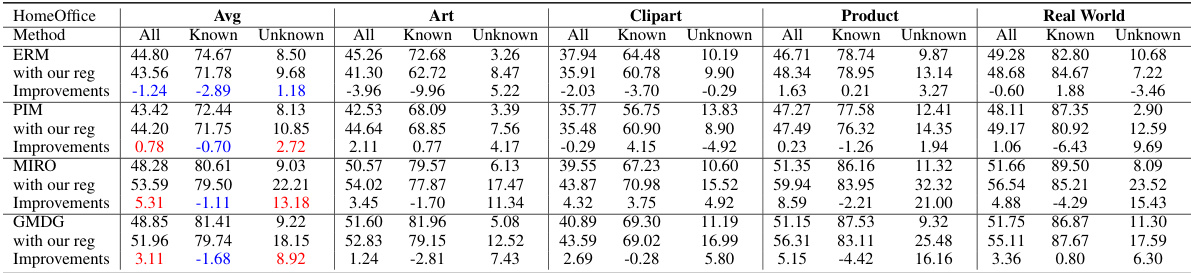
This table compares the performance of the proposed method (GMDG + L-Reg) against various existing multi-domain generalization (mDG) methods on five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table shows the average accuracy across different test domains for each method. Improvements and degradations relative to the GMDG baseline are highlighted to show the effectiveness of the proposed method.
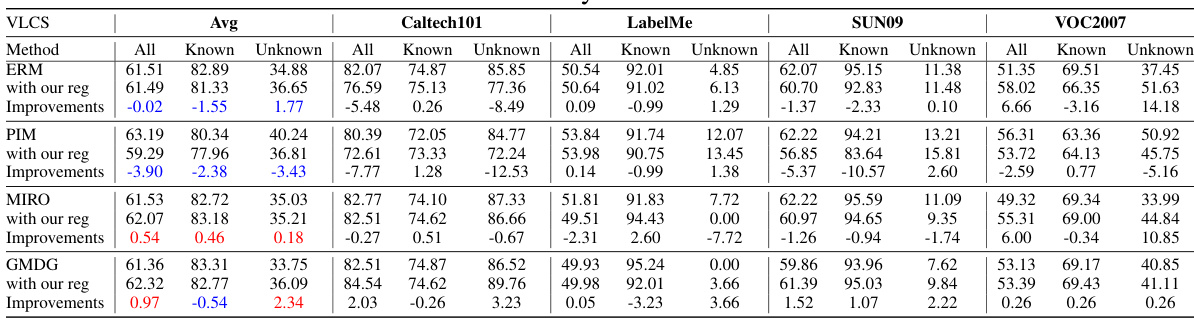
This table compares the performance of the proposed method (GMDG + L-Reg) with several other state-of-the-art multi-domain generalization (mDG) methods on five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The results are presented as the average accuracy across different test domains, with the best results for each group of methods highlighted in bold. Improvements or degradations compared to the GMDG baseline are indicated in red.
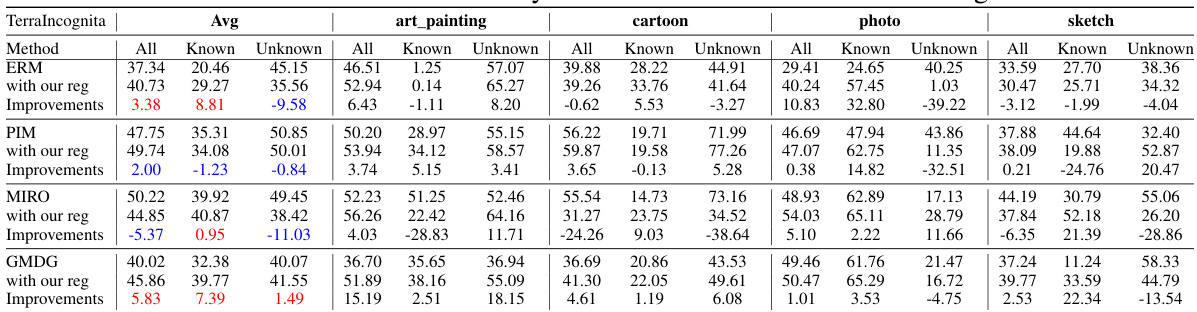
This table compares the performance of the proposed method (GMDG + L-Reg) with several existing multi-domain generalization (mDG) methods on five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The table shows the average accuracy across different test domains for each method and highlights the best performing method in each category. Improvements or degradations compared to the GMDG baseline are indicated in red.
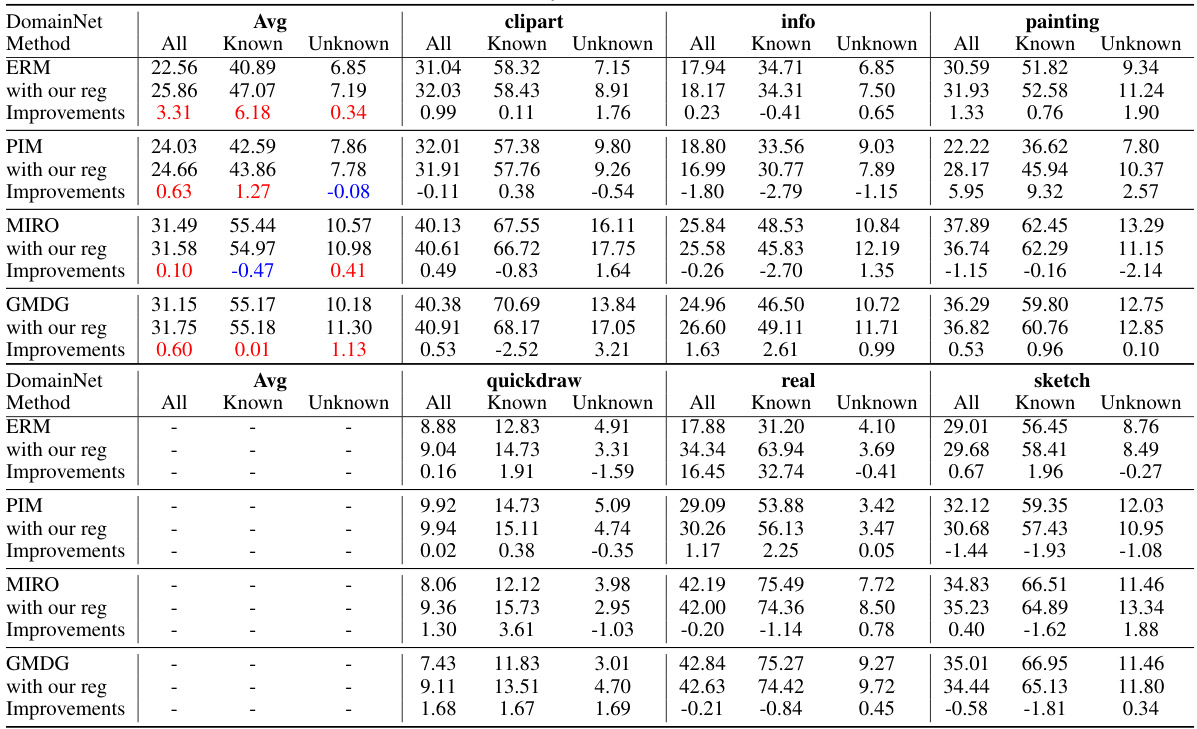
This table presents a comparison of the proposed method’s performance on multi-domain generalization (mDG) tasks against several existing non-ensemble and ensemble methods across five benchmark datasets (PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet). The best performing method for each dataset is highlighted in bold, and improvements or degradations compared to the GMDG baseline (a state-of-the-art method) are indicated in red. The average accuracy across all datasets is also provided for each method.
Full paper#