↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current face-swapping techniques struggle with swapping individual facial parts, often producing unnatural results. Existing methods, designed for full-face swapping, lack the fine-grained control needed for customized designs and seamless blending of multiple sources. There is a need for improved fusion mechanisms to handle multiple reference images effectively.
FuseAnyPart addresses these issues with a novel diffusion-based approach. It uses a mask-based fusion module to combine features from multiple reference images and an addition-based injection module to seamlessly integrate these features into the diffusion model. This results in high-fidelity, natural-looking swapped faces, even when using source images with significant differences in appearance. The method’s effectiveness is demonstrated through extensive qualitative and quantitative experiments, showcasing its superiority over existing techniques.
Key Takeaways#
Why does it matter?#
This paper is important because it presents FuseAnyPart, a novel approach to facial parts swapping that uses a diffusion model and multiple reference images. This offers significant improvements over existing methods, which struggle with swapping individual parts and achieving seamless results. The method’s high fidelity and ability to blend from multiple sources are significant, opening avenues for research in fine-grained face manipulation and high-fidelity image generation.
Visual Insights#
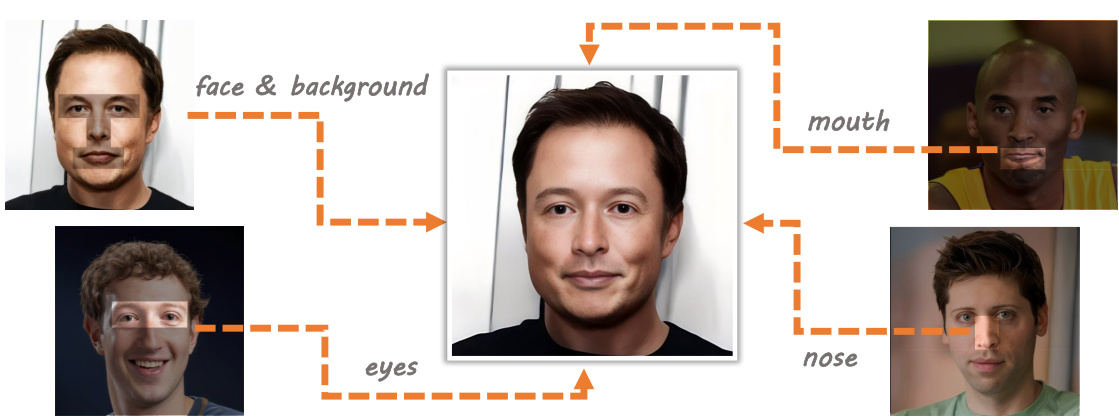
This figure shows an example of facial part swapping using the FuseAnyPart model. The central image is a generated face, created by combining parts from four different source images: the original face (top-left), a new face and background (bottom-left), eyes (top-right), and a nose (bottom-right). The result demonstrates FuseAnyPart’s ability to blend parts from diverse sources to create a realistic and seamless composite.

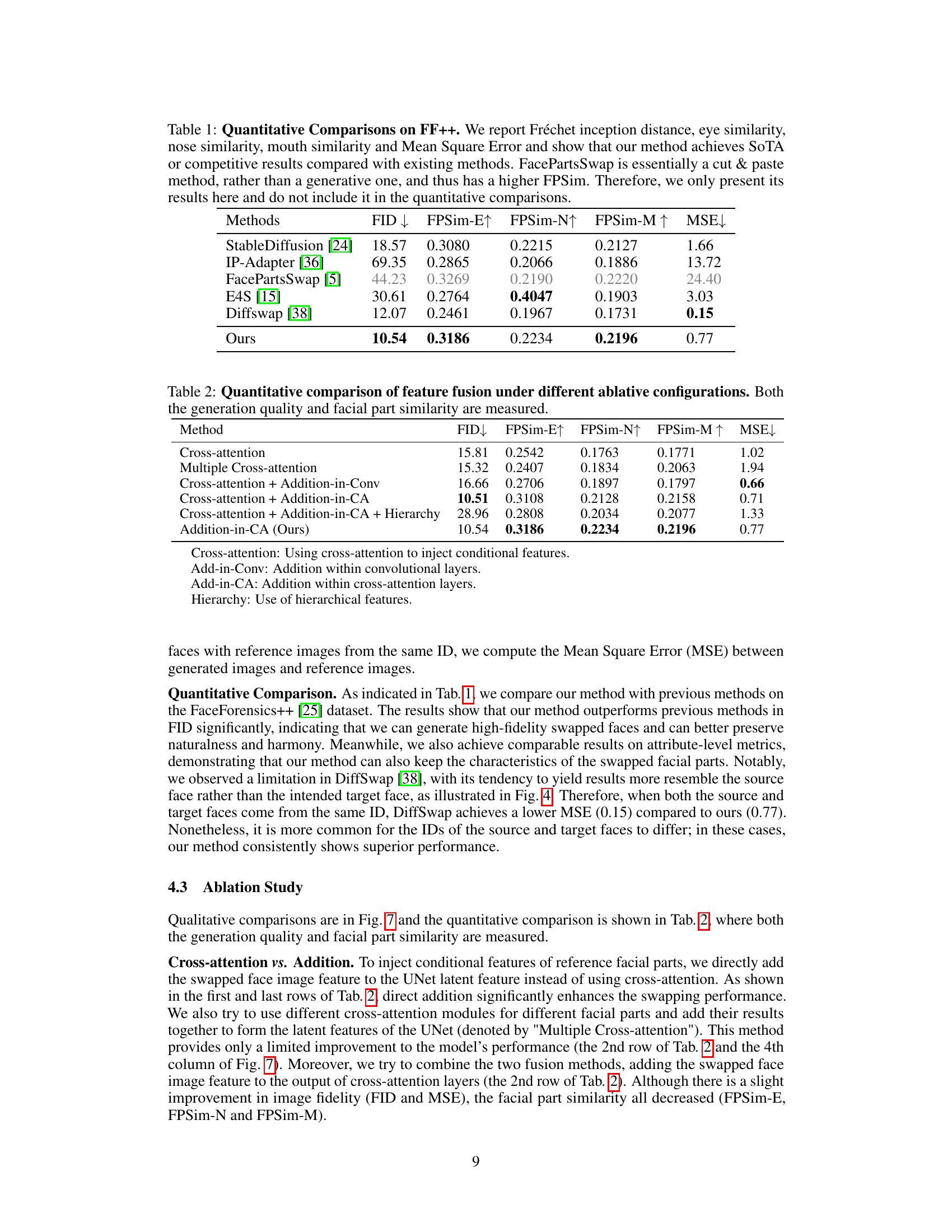
This table presents a quantitative comparison of different facial parts swapping methods on the FaceForensics++ (FF++) dataset. It evaluates the methods using Fréchet Inception Distance (FID) to assess image quality, and FPSim (Facial Part Similarity) metrics (FPSim-E, FPSim-N, FPSim-M) to measure the similarity between generated facial parts (eyes, nose, mouth) and corresponding reference images. Mean Squared Error (MSE) is also used to evaluate reconstruction accuracy. The results show that the proposed ‘Ours’ method achieves state-of-the-art or competitive performance compared to existing methods, particularly in terms of FID and MSE.
In-depth insights#
Multi-Ref Face Swap#
The concept of “Multi-Ref Face Swap” introduces a significant advancement in facial manipulation techniques. Instead of relying on a single reference image, this approach leverages multiple reference images to achieve a more comprehensive and realistic swap. This allows for finer control over the specific features being transferred, enabling seamless integration of elements from different sources. The primary challenge addressed is the accurate and efficient fusion of multiple reference features. The method likely involves a sophisticated algorithm to blend these features while preserving the integrity of the original face. Successful implementation would require robust feature extraction and alignment techniques along with a novel fusion strategy to avoid artifacts and inconsistencies. This approach represents a substantial improvement over traditional face-swapping methods, potentially leading to more natural and convincing results in applications such as character creation, entertainment, and image editing.
Diffusion Model Use#
This research leverages diffusion models as the foundation for facial part swapping. Instead of traditional GAN-based approaches, the authors opt for diffusion models due to their superior capability in generating high-resolution, photorealistic images. The diffusion process itself is not modified significantly, but rather the authors focus on how to effectively incorporate multiple reference images into the model to achieve the desired ‘fuse-any-part’ functionality. The core innovation lies in the novel fusion mechanism which cleverly integrates multiple facial features to generate a seamless composite face, avoiding the limitations of existing cross-attention methods which are deemed less efficient and effective. Ultimately, this method demonstrates the power and flexibility of diffusion models in complex image manipulation tasks. The ability to seamlessly blend multiple references and generate high-fidelity images is a key strength highlighted in the results.
Masked Feature Fusion#
Masked feature fusion, a crucial technique in many computer vision tasks, particularly facial manipulation, involves combining features from different image regions selectively. The “mask” acts as a guide, specifying which features to integrate and from which sources. This approach is advantageous because it allows for fine-grained control over the fusion process, enabling precise modifications and avoiding unwanted alterations to other regions. The process can be implemented at various levels, from pixel values to high-level feature representations, each offering trade-offs between complexity and precision. A key challenge is efficiently handling multiple masks and reference images without introducing artifacts or losing details. Methods that address this include sophisticated attention mechanisms and advanced neural network architectures. The choice of implementation depends heavily on factors such as the task’s complexity, computational resources, and desired level of control. Successful masked feature fusion techniques produce high-fidelity results that maintain image quality and structural integrity while seamlessly integrating desired attributes. Future research can explore novel fusion strategies, investigate the impact of different mask representations, and develop more robust methods capable of managing increasingly complex tasks.
Addition-Based Inject#
The proposed ‘Addition-Based Injection’ method offers a novel approach to integrating image features into a diffusion model’s UNet. Instead of relying on computationally expensive and potentially imprecise cross-attention mechanisms, it directly adds the fine-grained image features to the latent features within the UNet. This direct addition is strategically performed at specific layers within the UNet, ensuring that the injected image information aligns spatially with the existing latent features. This method’s simplicity and efficiency are key advantages over existing methods, as it avoids the complexities of cross-attention while maintaining precise positional information crucial for high-fidelity results. The method’s effectiveness is further highlighted by its ability to handle multiple source images seamlessly, a significant improvement over techniques limited to single-source integration. Preserving positional information through this straightforward addition process is critical for achieving natural-looking results, especially in the context of facial part swapping where subtle details are paramount. The ablation study’s results strongly support the efficacy of this approach over alternatives, emphasizing its role in producing superior image quality and detail.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a facial parts swapping model, this might involve removing or disabling certain modules, such as the attention mechanism or specific fusion techniques. The goal is to understand precisely how each component impacts the overall performance, measured by metrics like FID score, MSE, and part-specific similarity. By analyzing the performance changes after removing each component, researchers can determine its importance and identify potential areas for improvement or simplification. A well-designed ablation study provides strong evidence supporting the model’s architecture and design choices by demonstrating that each component plays a crucial and demonstrably beneficial role. It also helps identify potential weaknesses: if removing a component results in only a minor performance decrease, it suggests the component may be redundant or less critical than initially thought, presenting an opportunity for optimization. Furthermore, ablation studies help generalize the findings, showing that the effectiveness of the model is not dependent on specific interactions between components, but rather on the individual contributions of each element.
More visual insights#
More on figures
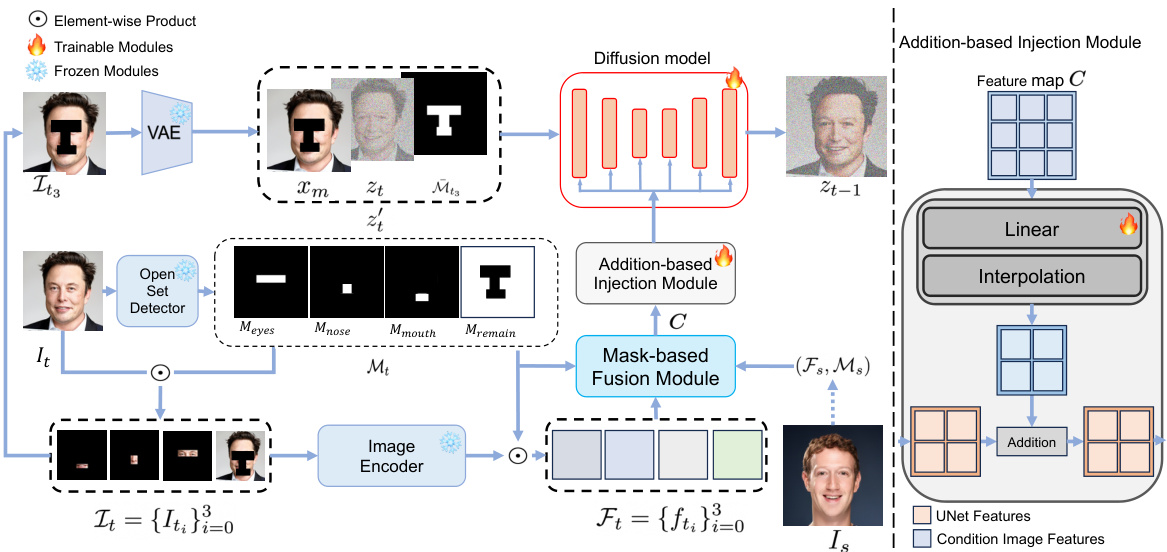
This figure illustrates the architecture of FuseAnyPart, a diffusion-driven facial parts swapping model. The process starts with an open-set detector identifying facial parts in the input image. An image encoder then extracts features for each part, guided by the masks generated by the detector. These features are fused in the Mask-based Fusion Module to create a complete latent representation of the face. Finally, this representation is passed to an Addition-based Injection Module to refine the feature map, and finally the UNet diffusion model to generate the final facial image.

This figure presents a qualitative comparison of eye swapping results from different methods: Stable Diffusion, IP-Adapter, FacePartsSwap, E4S, DiffSwap, and the proposed FuseAnyPart. The comparison highlights that FuseAnyPart produces results with high fidelity and natural appearance, maintaining consistency in facial features better than other methods. The other methods show artifacts, inconsistencies, or unnatural appearance in the swapped eyes.

This figure shows the results of facial parts swapping using the proposed method FuseAnyPart. The central image is the result of swapping parts from three different faces onto the original face (top left). This demonstrates the algorithm’s ability to seamlessly integrate facial parts with significant appearance differences to create a natural-looking result.

This figure compares the results of eye swapping using several different methods: Stable Diffusion, IP-Adapter, FacePartsSwap, E4S, DiffSwap, and the authors’ proposed method, FuseAnyPart. Each row shows a different source image for the eyes being swapped onto the same target face. The goal is to see which method produces the most realistic and seamless results, preserving the consistency of facial features and a natural appearance. The authors’ method aims to show superior results.

This figure shows example results of facial parts swapping using the FuseAnyPart model. The input consists of a target face and three reference images, each providing a different facial part (eyes, nose, mouth). FuseAnyPart blends these parts seamlessly onto the target face, resulting in a natural and high-fidelity image. The figure highlights the ability of the model to handle significant differences in appearance between the reference images.

This figure compares the results of several ablation studies on the FuseAnyPart model. Specifically, it shows the effect of different methods for integrating image features into the UNet of the diffusion model, including using cross-attention, multiple cross-attention, and a proposed addition-based injection method. The results demonstrate the superiority of the addition-based injection approach in terms of image quality and facial feature preservation.

This figure compares the performance of various face swapping methods, specifically focusing on eye replacement. It shows the original face and the results of StableDiffusion, IP-Adapter, FacePartsSwap, E4S, DiffSwap, and the proposed FuseAnyPart method. The comparison highlights FuseAnyPart’s ability to produce high-fidelity results that preserve facial features and create a natural look.

This figure compares the results of facial part swapping using the proposed method, FuseAnyPart, against DiffFace. The comparison highlights the superior quality of FuseAnyPart, showing that FuseAnyPart produces more natural-looking results with fewer distortions, particularly around the eyes and mouth, making the swapped parts blend more seamlessly with the original image.

This figure shows the results of facial part swapping where the source and target images have significant differences in age and race. It demonstrates the ability of the FuseAnyPart method to handle such diverse inputs, showcasing its robustness and generalization capabilities. The results highlight the method’s capacity to seamlessly blend facial parts from various individuals, regardless of variations in age and ethnicity.

This figure shows examples of facial part swapping where the source and target images have significant differences in age and race. The results demonstrate the ability of the FuseAnyPart model to handle such variations. The top row shows a young Asian’s facial features swapped onto an older Black person’s face, and the bottom row presents the opposite scenario.

This figure shows the results of facial part swapping using the FuseAnyPart method. The central image is the result of combining the original face (top-left) with three different reference images for the eyes, nose, and mouth. It highlights FuseAnyPart’s ability to seamlessly blend parts from various sources, even with significant differences in appearance, generating realistic and high-quality results.

This figure shows the results of swapping different facial parts (eyes, nose, and mouth) from various source images onto the same target face. The results demonstrate the model’s ability to seamlessly blend features from multiple sources while maintaining a cohesive and natural-looking result. Each row represents a different target face and different source images used to swap the facial parts.
Full paper#