↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Sequential recommender systems (SRS) struggle with the long-tail problem: most users interact with only a few items, and most items are rarely interacted with. Existing methods often fail to adequately address this challenge, leading to suboptimal recommendations. This problem is especially crucial for user experience and seller benefits.
The proposed LLM-ESR framework enhances SRS by incorporating semantic information from large language models (LLMs). It uses a dual-view modeling approach that combines semantic insights from LLMs and collaborative signals from traditional SRS. For long-tail users, a retrieval augmented self-distillation method enhances user representation, improving overall recommendation accuracy and user experience. LLM-ESR is model-agnostic, meaning it can be adapted to various SRS models, and consistently outperforms existing baselines on real-world datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on sequential recommendation systems. It directly addresses the persistent long-tail problem, offering a novel and effective solution by leveraging the power of large language models (LLMs). The model-agnostic framework and impressive results make it highly relevant to current research trends and open exciting new avenues of investigation. Its practical relevance makes it particularly valuable for industry professionals seeking to improve real-world recommender systems.
Visual Insights#
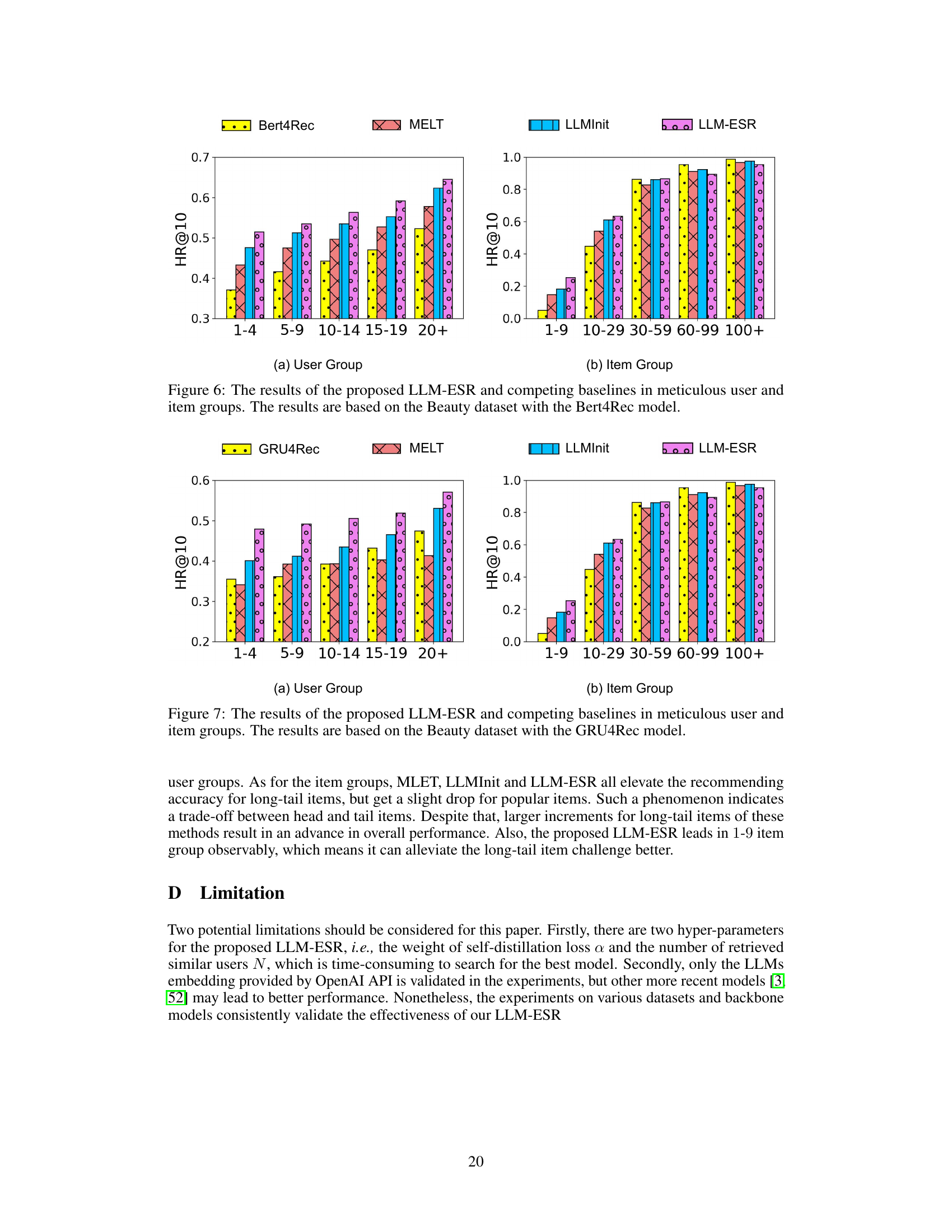
This figure shows the performance of SASRec (Self-Attentive Sequential Recommendation) on the Amazon Beauty dataset, highlighting the long-tail user and long-tail item challenges. The left subplot (a) illustrates the long-tail user challenge, showing that the majority of users interact with a small number of items, leading to subpar performance for these users. The right subplot (b) demonstrates the long-tail item challenge, where most items are seldom consumed, resulting in significantly better performance for popular items compared to less popular ones. The histograms visually represent the distribution of users and items, indicating the scarcity of interactions for long-tail users and items.
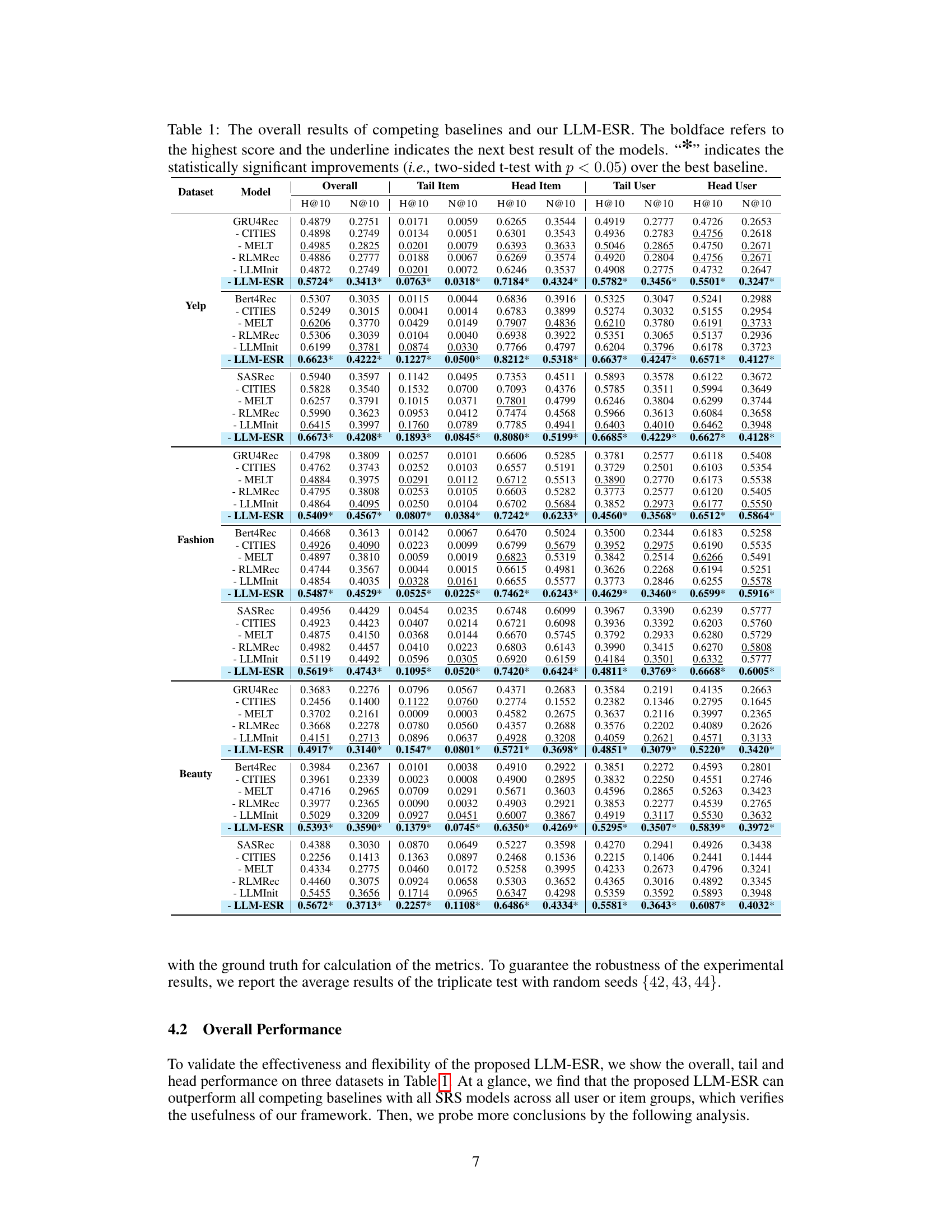
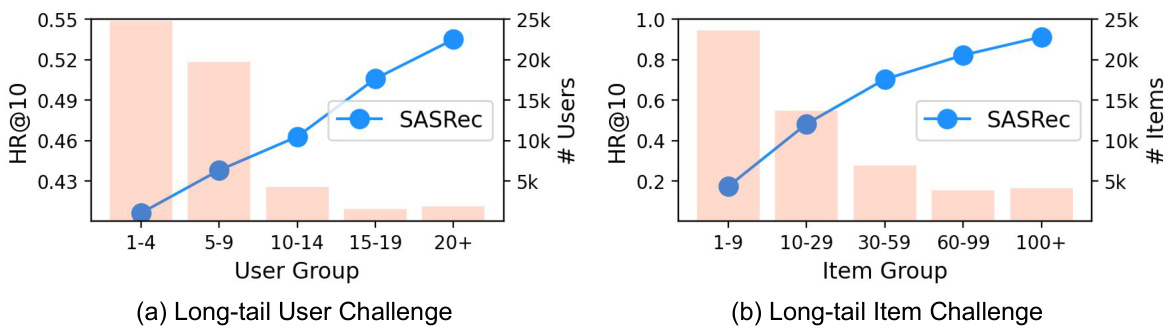
This table presents a comprehensive comparison of the proposed LLM-ESR model against various baseline models across three real-world datasets (Yelp, Fashion, Beauty). The performance is evaluated using two metrics (H@10 and N@10) and broken down by four user/item groups (overall, tail item, head item, tail user, and head user) to show the effectiveness of the LLM-ESR model specifically on long-tail items and users. Statistical significance is indicated using a two-sided t-test.
In-depth insights#
LLM-ESR Framework#
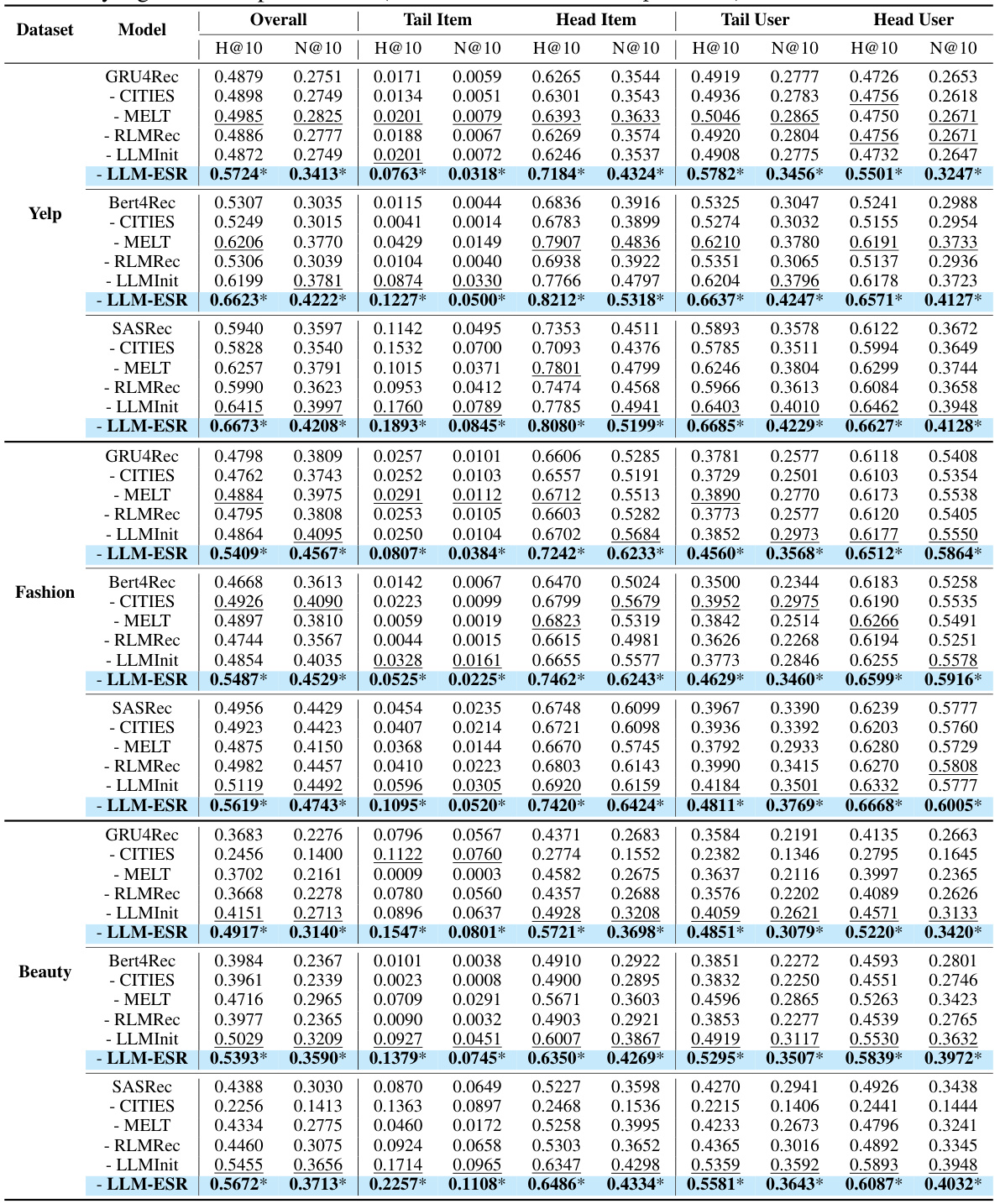
The LLM-ESR framework presents a novel approach to enhancing sequential recommender systems (SRS) by leveraging the power of large language models (LLMs). It tackles the persistent challenges of long-tail users and items in SRS, a critical limitation of traditional methods. The core innovation lies in its model-agnostic design, meaning it can be integrated with various existing SRS architectures without requiring significant modifications. Instead of directly incorporating LLMs into the inference pipeline, which would be computationally expensive, LLM-ESR pre-computes semantic embeddings for items and users using LLMs and then uses these embeddings to enrich the collaborative signals within the SRS. This dual-view approach allows the model to capture both semantic and collaborative information effectively. To address the long-tail user problem, a retrieval-augmented self-distillation mechanism uses LLMs to identify similar users, transferring knowledge from those with richer interaction histories to improve the representation of long-tail users. This framework promises a significant advancement by addressing the long-tail limitations while preserving computational efficiency, a crucial factor for practical deployment in real-world applications.
Dual-View Modeling#
The proposed dual-view modeling framework represents a novel approach to sequential recommendation by integrating both semantic and collaborative information. The semantic view leverages pre-trained language model embeddings to capture the rich semantic meaning of items, effectively addressing the long-tail item challenge. Crucially, the embeddings are frozen to avoid loss of semantic information, and an adapter layer is used for dimension transformation. Conversely, the collaborative view utilizes traditional sequential recommendation techniques to encode user-item interactions, capturing collaborative signals. This dual approach is particularly beneficial for handling long-tail items, as semantic information compensates for the scarcity of interactions often associated with these items. A two-level fusion mechanism (sequence-level cross-attention and logit-level concatenation) combines the outputs of both views, creating a more robust and comprehensive representation of user preferences that improves the overall recommendation quality, especially for less frequently interacted items.
Long-Tail Challenges#
Long-tail challenges in sequential recommendation (SR) stem from the imbalance between popular and unpopular items (long-tail items) and users who interact with few items (long-tail users). Traditional SR models struggle with these scenarios because they often rely heavily on collaborative filtering, which performs poorly when data sparsity is high. The lack of interactions for long-tail items leads to inadequate representation and prediction, while limited data for long-tail users hinders accurate preference modeling. Addressing these challenges is crucial for improving user experience and overall system performance, as ignoring them means a significant portion of items and users receive suboptimal or no recommendations. Successful approaches often involve strategies like incorporating additional information (such as item attributes and descriptions) or using advanced techniques like knowledge distillation or self-distillation to augment learning from scarce data and improve the representation of long-tail items and users. Semantic understanding leveraging large language models emerges as a promising new direction for tackling this challenge.
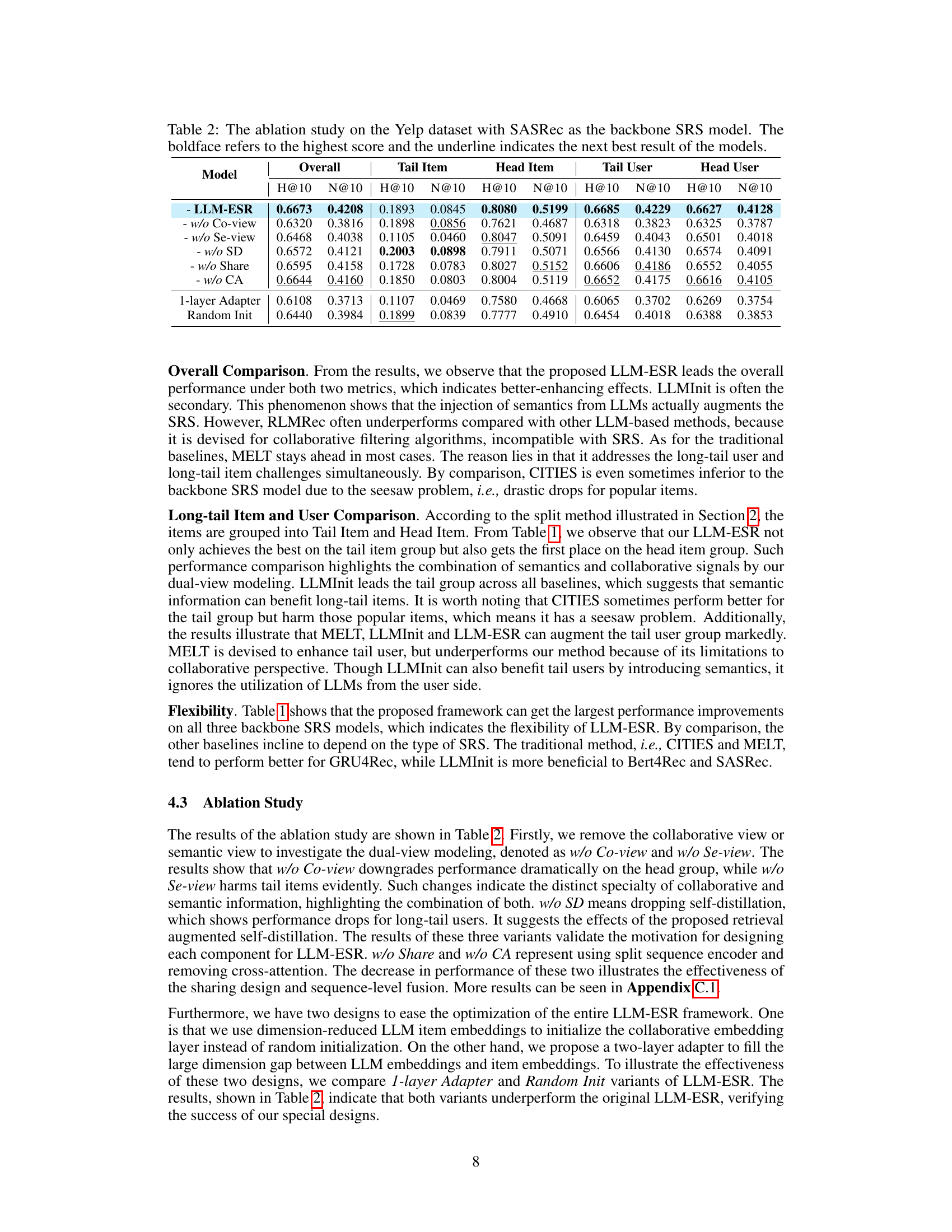
Ablation Study#
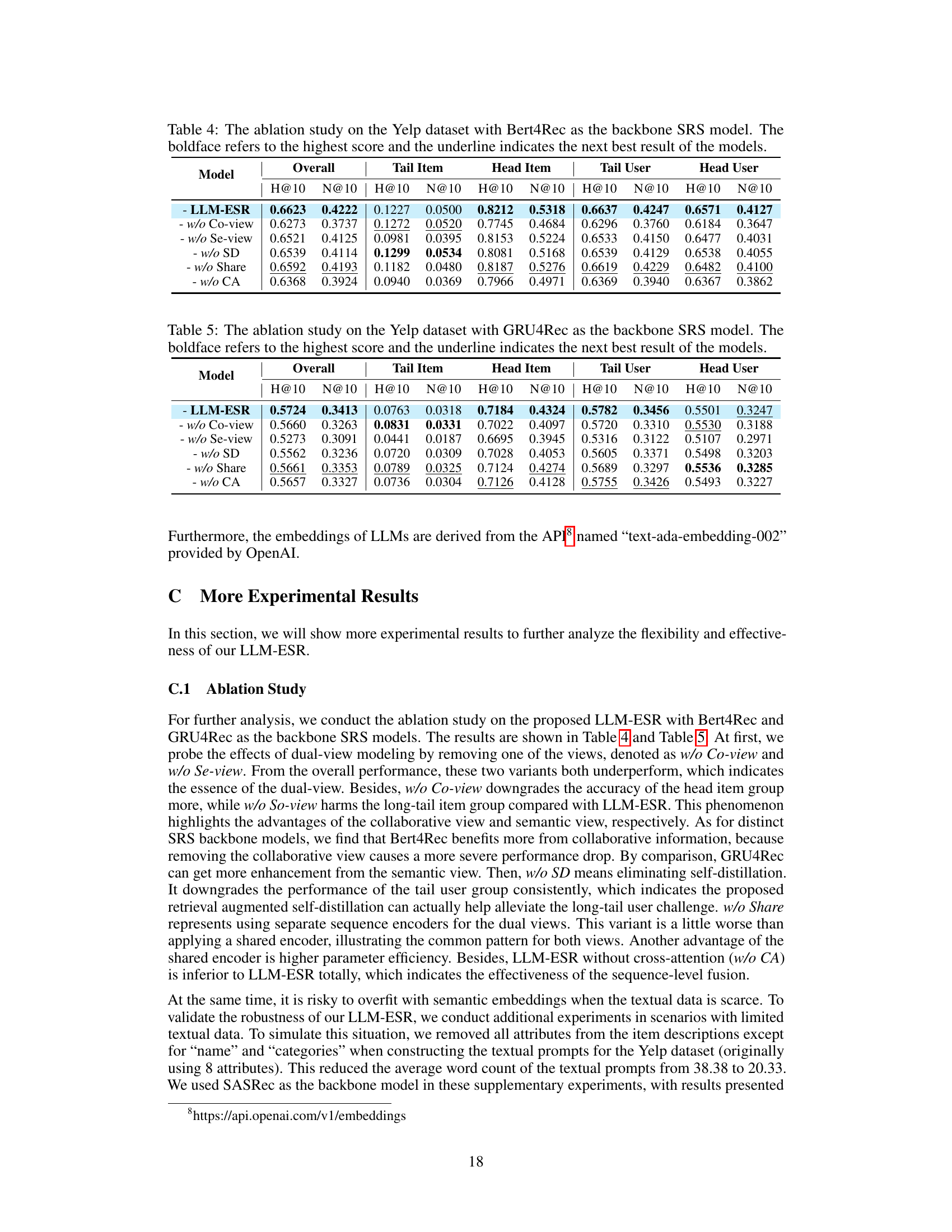
An ablation study systematically evaluates the contribution of each component within a proposed model. In the context of a sequential recommendation system, this involves removing individual modules (e.g., semantic embedding, collaborative filtering, self-distillation) to assess their impact on overall performance. Key insights gained from such a study reveal the relative importance of each component and can expose unexpected interactions between them. For instance, removing the semantic embedding might significantly reduce accuracy on long-tail items, demonstrating its crucial role in handling data sparsity. Similarly, ablation of the self-distillation module might show a performance drop for users with limited interaction history, highlighting its efficacy for addressing the long-tail user challenge. The results of the ablation study often inform design choices, highlighting strengths and weaknesses of the model’s architecture. A well-conducted ablation study provides strong evidence supporting the design choices made and the overall effectiveness of the model, leading to a more robust and well-justified system.
Future Directions#
Future research could explore more sophisticated methods for integrating LLMs and traditional SRS. Improving the efficiency of semantic embedding generation is crucial for real-world applications. Investigating different LLM architectures and prompt engineering techniques could significantly enhance performance. Further research into handling various data sparsity levels beyond long-tail scenarios is needed. A key challenge is to address the inherent biases present in LLMs and training data, ensuring fairness and inclusivity in recommendations. Finally, extensive testing and validation on a broader range of datasets and SRS models would strengthen the generalizability and robustness of LLM-enhanced systems. The exploration of novel fusion strategies, that go beyond the current dual-view approach, is also warranted to find optimal synergies between semantic and collaborative information.
More visual insights#
More on figures
This figure illustrates the architecture of the LLM-ESR framework, which is designed to enhance sequential recommendation models by incorporating semantic information from large language models (LLMs). It shows two main modules: Dual-view Modeling and Retrieval Augmented Self-Distillation. The Dual-view Modeling module combines semantic embeddings from LLMs with collaborative signals from traditional SRS to address the long-tail item challenge. The Retrieval Augmented Self-Distillation module leverages semantic user representations from LLMs to retrieve similar users and improve user preference representation for long-tail users. The framework is model-agnostic, meaning it can be adapted to various sequential recommendation models.
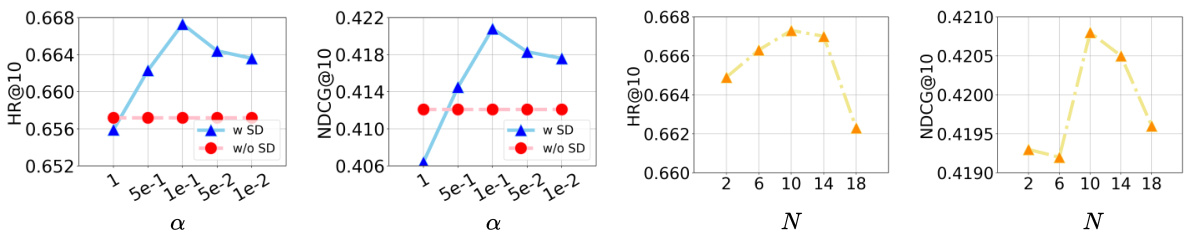
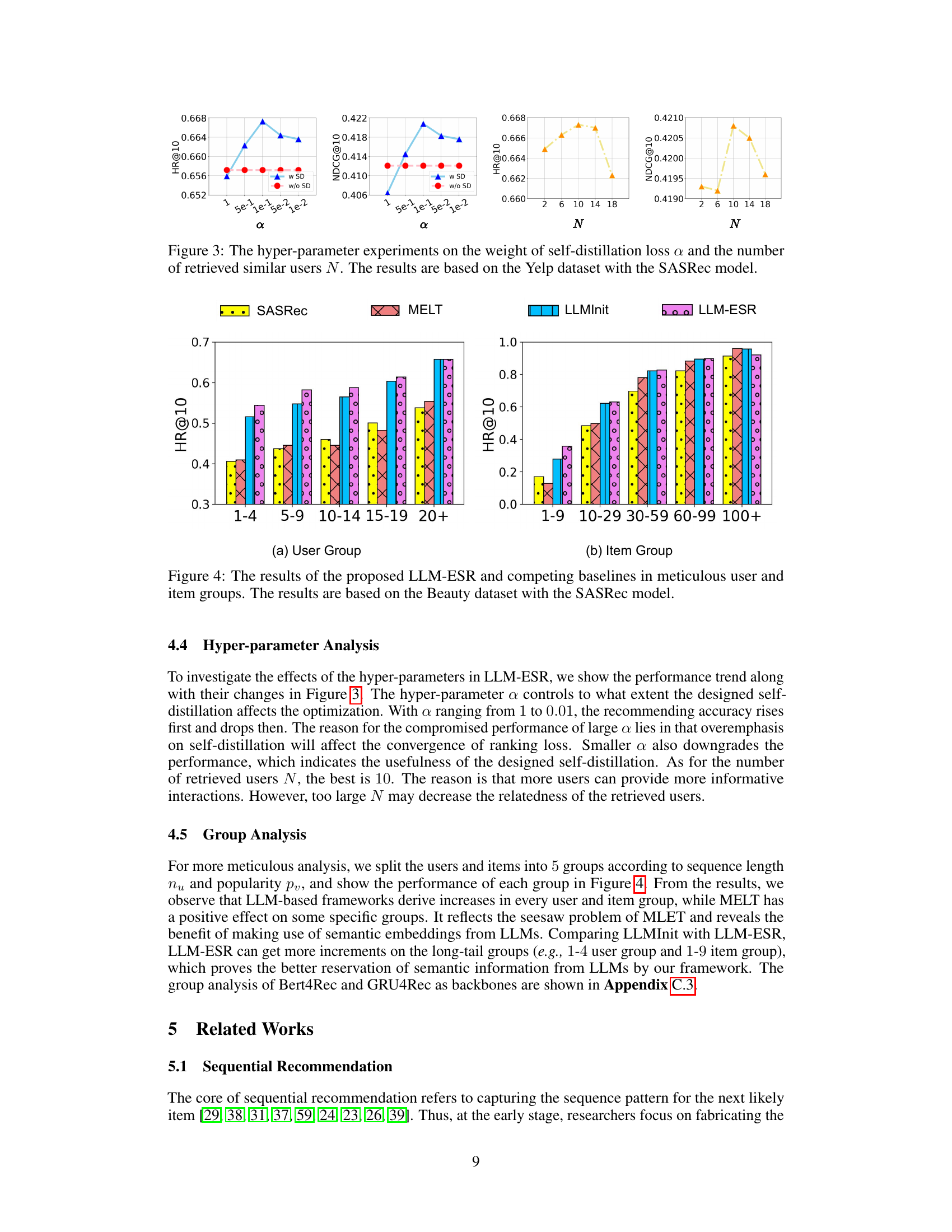
This figure shows the results of hyperparameter tuning for the LLM-ESR model using the Yelp dataset and SASRec as the base model. The left two subfigures illustrate how the performance (HR@10 and NDCG@10) changes with different values of α (weight of self-distillation loss). The right two subfigures show how performance changes with different numbers of retrieved similar users (N). The results help determine optimal values for α and N to maximize the model’s performance.
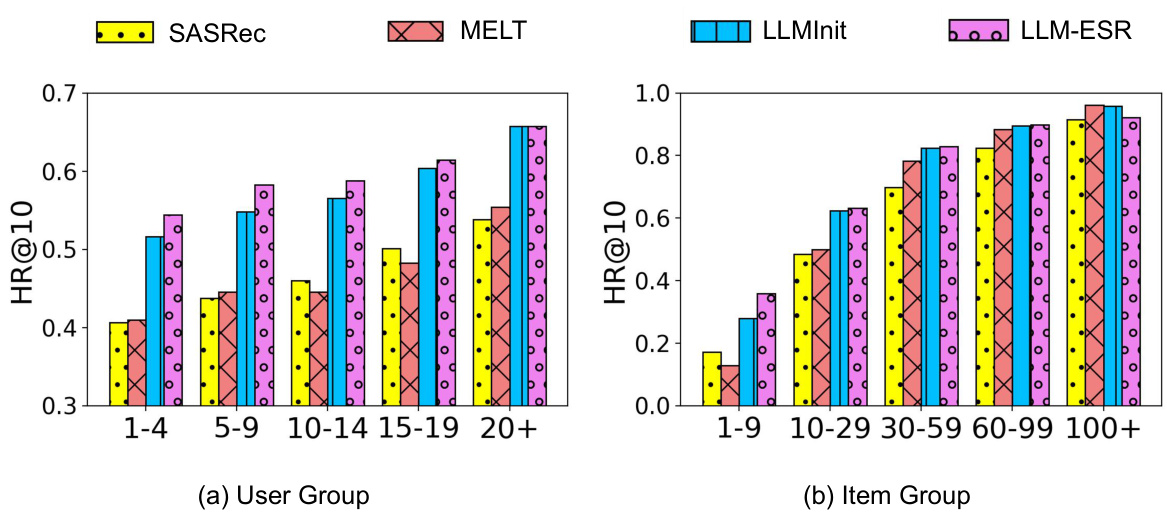
This figure shows the performance of LLM-ESR and other baseline models on the Beauty dataset using the SASRec model. It is broken down into two sub-figures. Subfigure (a) shows the performance across different user groups, categorized by the number of items each user interacted with (long-tail users having interacted with fewer items). Subfigure (b) shows performance across different item groups, categorized by the number of times each item was interacted with (long-tail items having been interacted with fewer times). The results illustrate LLM-ESR’s superior performance, especially for the long-tail users and items, compared to baselines like SASRec, MELT, and LLMInit.
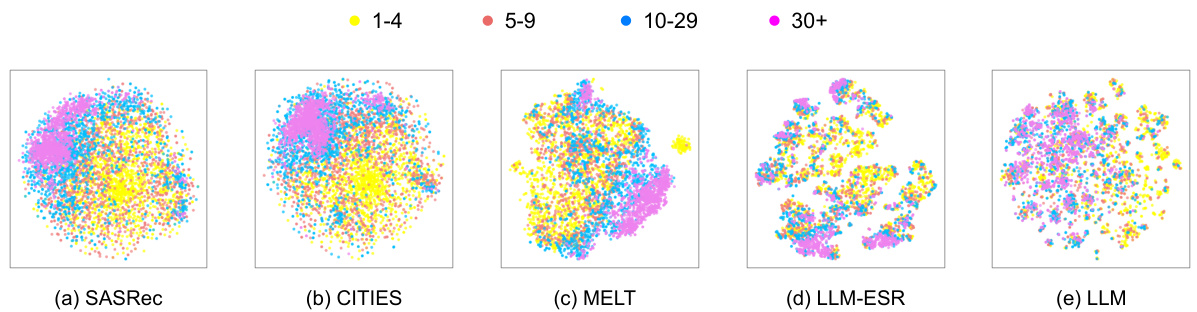
This figure visualizes item embeddings using t-SNE, comparing SASRec, CITIES, MELT, LLM-ESR, and LLM embeddings. It shows how different models represent item semantics, particularly focusing on the impact of LLMs and the proposed LLM-ESR framework. The visualization helps to understand how well different methods separate items based on popularity.
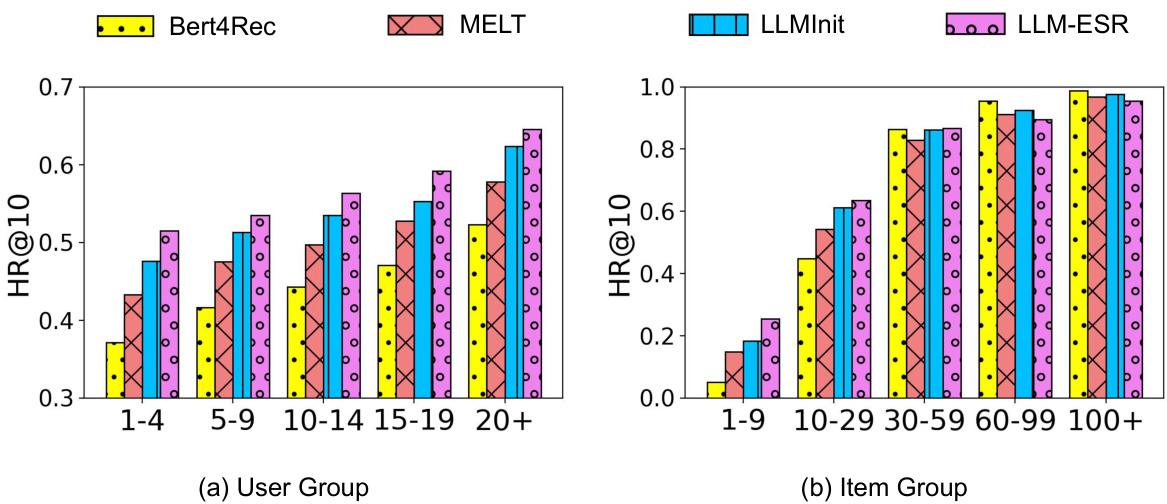
This figure shows a detailed comparison of the performance of LLM-ESR against other baselines (SASRec, MELT, LLMInit) on the Beauty dataset. The results are broken down by user group (based on interaction history length) and item group (based on item popularity). The graphs display HR@10 (Hit Rate at 10) for each group, allowing for a precise understanding of how well each model performs for both long-tail users/items and head users/items. LLM-ESR consistently shows improved performance across all user and item groups.
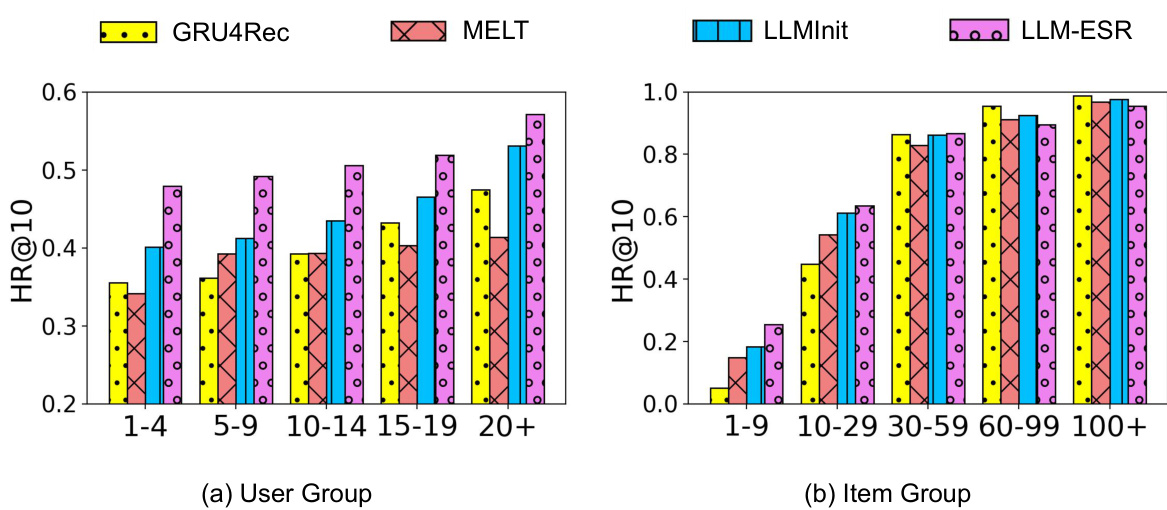
This figure shows a detailed performance comparison between the proposed LLM-ESR method and several baseline methods across different user and item groups. The performance is measured by Hit Rate@10 (HR@10), and broken down by user group (categorized by number of interactions) and item group (categorized by popularity). The results demonstrate the effectiveness of LLM-ESR, particularly for long-tail users and items, highlighting its ability to improve recommendation accuracy in scenarios with limited user-item interaction data. The dataset used is Amazon Beauty, and the underlying recommendation model is SASRec.
More on tables
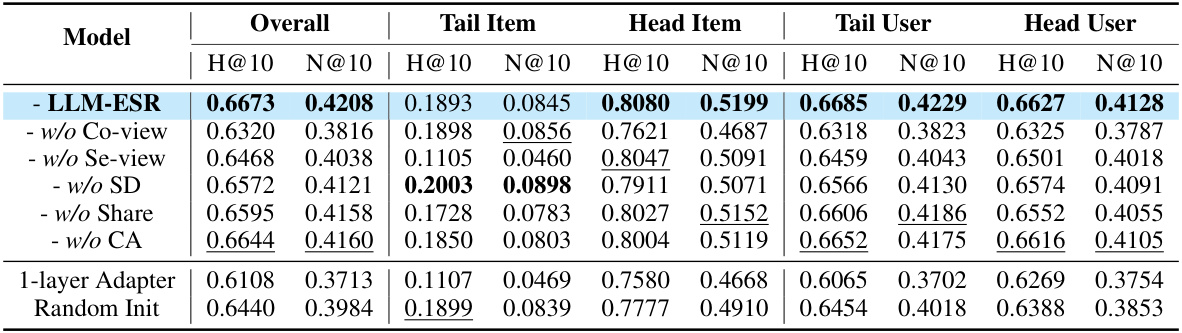
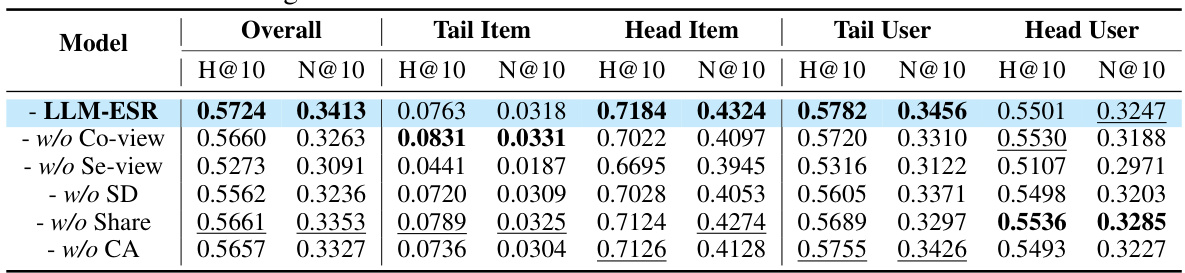
This ablation study analyzes the impact of different components of the LLM-ESR model on its performance using the Yelp dataset and SASRec as the base model. It shows the results with all components, and then systematically removes components (collaborative view, semantic view, self-distillation, shared encoder, cross-attention) to understand their individual contributions. It also shows the impact of using a one-layer adapter versus random initialization.
This table presents the overall performance comparison between LLM-ESR and various baselines across three datasets (Yelp, Fashion, Beauty) using three different sequential recommendation models (GRU4Rec, Bert4Rec, SASRec). It shows the H@10 and NDCG@10 metrics for overall performance, long-tail items, long-tail users, head items, and head users. The ‘*’ indicates statistical significance.
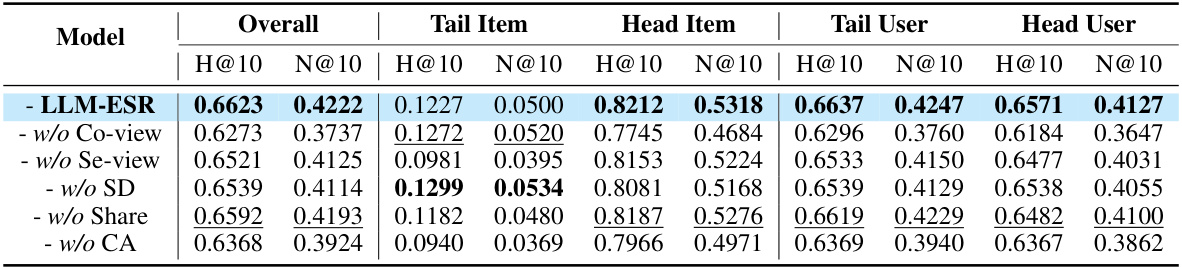
This table presents the overall performance comparison between LLM-ESR and several baselines on three datasets (Yelp, Fashion, Beauty). The results are broken down by model (GRU4Rec, Bert4Rec, SASRec), and further categorized by overall performance, performance on long-tail items, performance on head items, performance on long-tail users, and performance on head users. The H@10 and N@10 metrics are used to evaluate performance. Asterisks (*) indicate statistically significant improvements compared to the best-performing baseline.
This table presents a comparison of the proposed LLM-ESR model against several baseline models for sequential recommendation. It shows the performance (H@10 and N@10) across three datasets (Yelp, Fashion, Beauty) and broken down by user and item categories (overall, head/tail items and users). Statistical significance is indicated using a *.

This table presents an ablation study on the Yelp dataset using the LLM-ESR model. It compares the performance of the model under different conditions: using full item prompts vs. cropped prompts, and with vs. without freezing the semantic embedding layer. The results show the impact of these factors on the overall performance and on performance for different user and item groups.
Full paper#