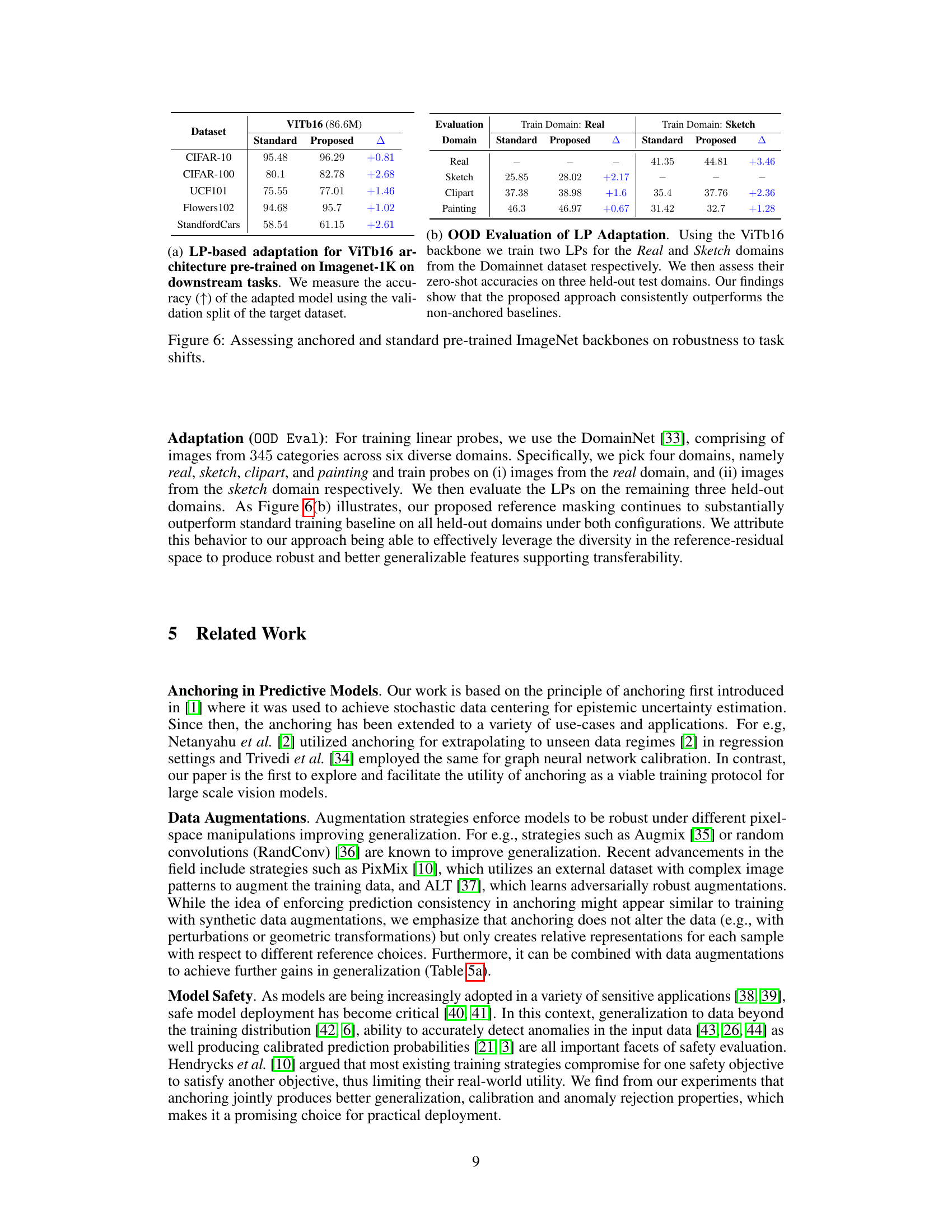
↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Anchoring, a training technique for deep neural networks, promises improved uncertainty estimation and generalization. However, the paper reveals a critical flaw: anchored training can lead to models learning undesirable shortcuts, reducing generalization capabilities. This is especially problematic when using diverse reference data during training.
To overcome this, the authors introduce a novel “reference masking” regularizer. This technique involves masking out the reference input during a portion of training, forcing the network to focus on the residual information and preventing it from relying on shortcuts. Empirical evaluations show that this method significantly enhances model performance in generalization, calibration, and robustness to unseen data, surpassing standard training approaches on various datasets and architectures.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical limitation of the anchoring technique in training vision models, improving generalization and safety. It proposes a novel regularization method and demonstrates substantial performance gains across various datasets and architectures, opening new avenues for research in robust and safe AI.
Visual Insights#
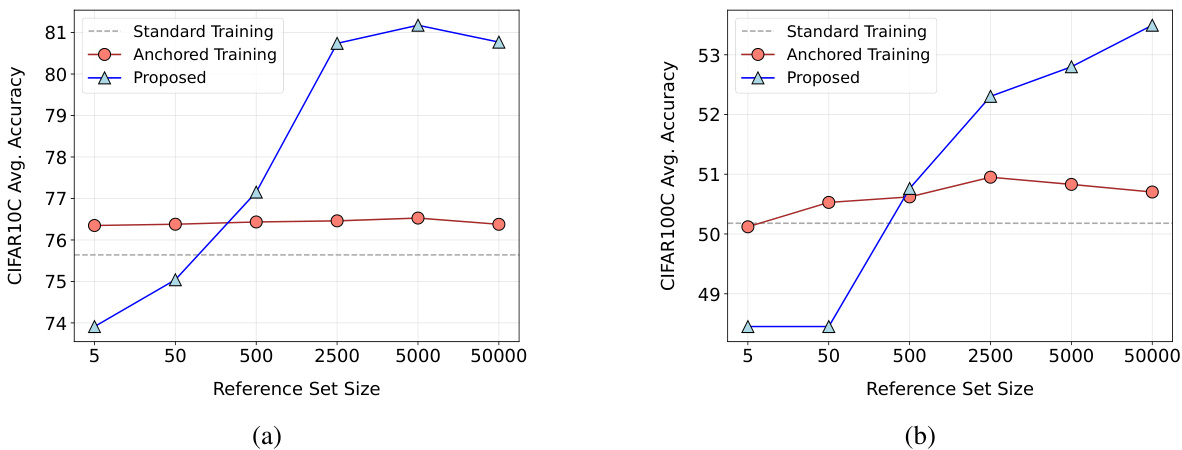
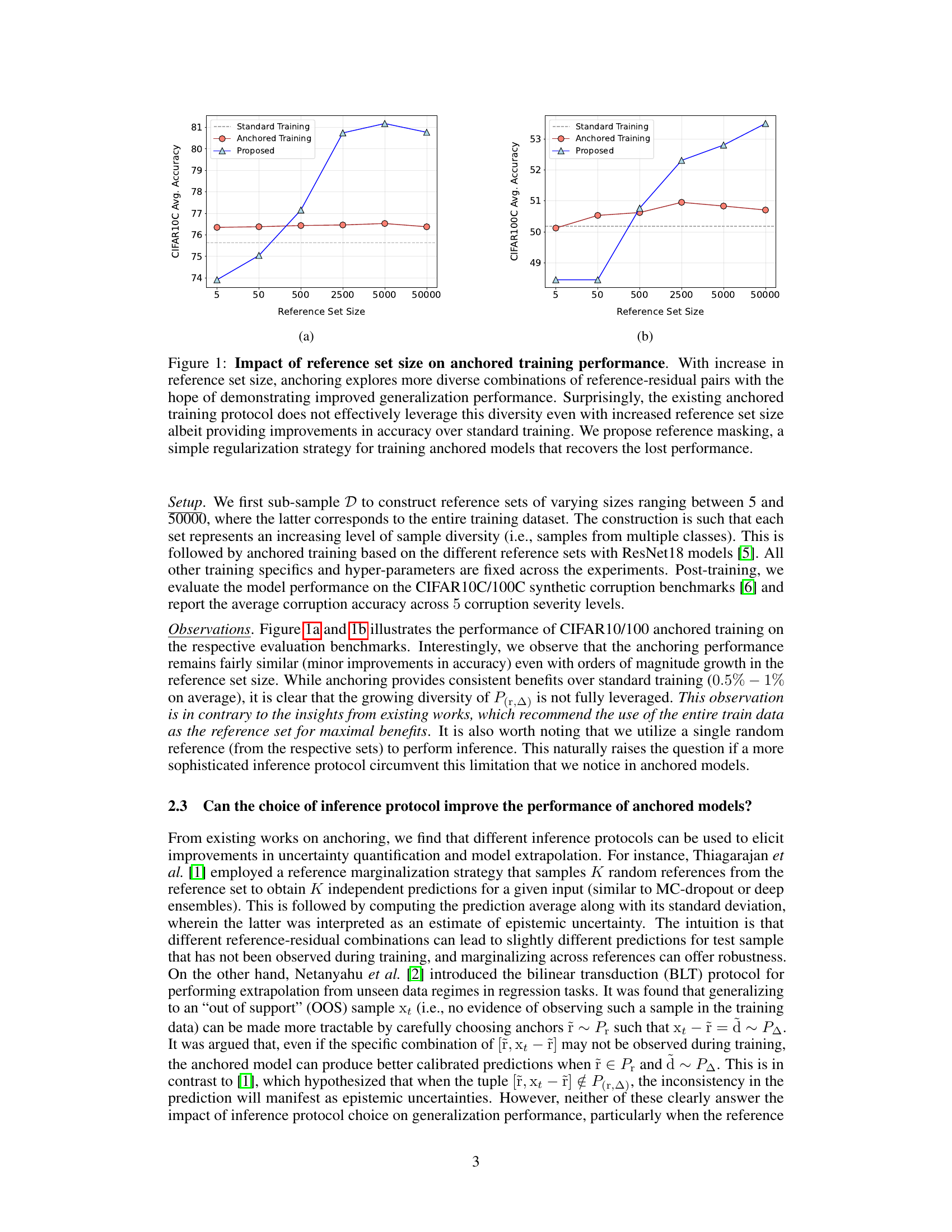
The figure shows the impact of the size of the reference set on the performance of anchored training. Two subfigures (a) and (b) present results for CIFAR10C and CIFAR100C datasets respectively. The x-axis represents the size of the reference set, while the y-axis shows the average accuracy. The plots reveal that increasing the reference set size does not improve performance as expected with the standard anchored training approach. A proposed method (reference masking) is introduced which shows significant performance improvement.
This table details the training hyperparameters used for different datasets and model architectures. It shows that standard training recipes were used, but anchoring was applied on top of them. This highlights the flexibility of anchoring, which can be combined with existing methods.
In-depth insights#
Anchoring’s Promise#
Anchoring, in the context of training vision models, holds significant promise by offering a unique reparameterization of input data. This reparameterization, separating an input into a reference sample and a residual, forces the model to learn a mapping between the joint space of references and residuals, rather than a direct input-output mapping. This approach is particularly beneficial in improving uncertainty estimation, calibration, and extrapolation capabilities. By modeling the joint distribution of references and residuals, anchoring implicitly enhances the model’s ability to generalize to unseen data and perform robustly in out-of-distribution settings. However, realizing this promise is not without challenges. A critical limitation lies in the potential for the model to exploit undesirable shortcuts. The risk of such shortcuts increases when utilizing high reference diversity. Therefore, careful consideration of training protocols and the incorporation of techniques like reference masking regularization are crucial for fully realizing anchoring’s potential for building robust and safe vision models.
Shortcut Mitigation#
Shortcut mitigation is a crucial aspect of training robust and generalizable machine learning models, especially in the context of computer vision. The core problem is that models can learn to exploit spurious correlations or “shortcuts” in the training data rather than learning the true underlying patterns. This leads to poor generalization performance on unseen data and makes the model vulnerable to adversarial attacks. Anchoring, a recent training technique, aims to enhance model generalization by forcing the network to learn more robust representations. However, the paper identifies that traditional anchoring methods can inadvertently amplify shortcut learning, particularly when reference diversity is high. The solution proposed is a novel reference masking regularizer. This regularizer helps prevent overreliance on shortcuts by randomly masking out reference samples during training, compelling the model to rely more on the inherent structure of the data. Empirical evaluations across various datasets and architectures demonstrate the effectiveness of the proposed technique in improving generalization and robustness by mitigating the negative impacts of shortcut learning in the anchoring training paradigm. The open-source code provides reproducibility and facilitates further research in this direction.
Inference Protocols#
The concept of ‘Inference Protocols’ within the context of anchored vision models is crucial for realizing the full potential of this training approach. Different protocols significantly impact model performance, particularly concerning generalization and uncertainty quantification. A simple approach uses a single randomly selected reference sample, while more sophisticated methods employ multiple references or search for the optimal reference, incurring greater computational cost. The choice of protocol should not be regarded as a mere implementation detail but rather as a critical design decision, significantly affecting the model’s ability to leverage the diverse reference-residual pairs learned during training. The trade-off between computational expense and improved performance needs careful consideration. Future research should investigate the interplay between inference protocol design, reference set diversity, and model architecture to optimize the balance between accuracy, uncertainty estimation, and efficiency. Ultimately, the ideal inference protocol should depend on the specific application and the desired balance of these critical factors.
Safety and Robustness#
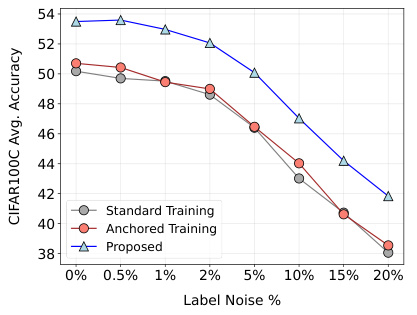
Safety and robustness are critical aspects of any machine learning model, especially in vision applications where the consequences of errors can be significant. The research paper likely explores various techniques to enhance these properties. This could involve analyzing the model’s uncertainty estimates to identify potential failures and using robust training methods to make the model less sensitive to noisy or adversarial inputs. Calibration of predicted probabilities is crucial to ensure that model confidence accurately reflects performance. The paper probably investigates the model’s performance across different datasets and conditions to evaluate its generalization and out-of-distribution robustness, including evaluating its resistance to various data corruptions. Anomaly detection is also essential for safe deployment. The paper likely assesses the model’s ability to recognize and reject samples that are outside the expected distribution. Furthermore, the analysis of the model’s behavior under various covariate shifts evaluates its adaptability to real-world scenarios. The use of metrics like AUROC and smoothed ECE is likely to provide a quantitative measure of anomaly detection and calibration accuracy. The study also considers the impact of different training strategies on safety and robustness, exploring which methods might improve the model’s reliability and resilience to unseen data.
Future Directions#
The research paper’s “Future Directions” section would ideally delve into several crucial aspects. Extending the anchoring principle to other domains beyond computer vision is a primary area; exploring its efficacy in natural language processing, time-series analysis, or reinforcement learning could reveal significant new applications. Developing a comprehensive theoretical framework to rigorously explain the observed improvements in generalization and safety would provide a strong foundation for future work and aid in refinement of the technique. The current empirical findings warrant a deeper dive into why anchoring leads to improved calibration and robustness. Further investigation into the interaction between anchoring and other training techniques (e.g., different optimizers, augmentations, model architectures) would be valuable. Finally, exploring the potential limitations of anchoring under specific data distributions or task scenarios is essential. This might entail addressing challenges posed by imbalanced datasets, high-dimensional data, or tasks requiring extremely high accuracy. Addressing these points would significantly strengthen and extend the impact of the research.
More visual insights#
More on figures

The figure shows the impact of the size of the reference set on the performance of anchored training. Two sub-figures present the results on CIFAR10C and CIFAR100C datasets. The x-axis represents the size of the reference set, and the y-axis represents the average accuracy across five corruption severity levels. The existing anchored training method shows only minor improvements in accuracy as the reference set size increases. A new method, ‘Proposed,’ which incorporates a reference masking regularizer, is shown to significantly improve generalization performance, especially with larger reference sets.

This figure displays a comparison of accuracy landscapes for three different training methods: standard training, anchored training, and the proposed method (anchored training with reference masking regularization). Each landscape is a 2D heatmap showing the accuracy (normalized to be between 0 and 1) across different points in the parameter space of the model. The wider and flatter optimum of the proposed method indicates improved generalization ability.
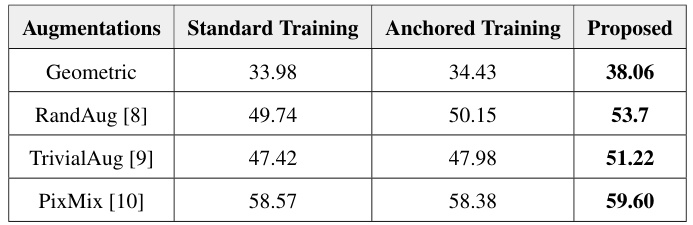
The figure shows the impact of the size of the reference set on the performance of anchored training. It demonstrates that while increasing the reference set size improves performance, it doesn’t fully leverage the increased diversity. A new proposed method, ‘reference masking,’ addresses this limitation, significantly improving generalization.
More on tables
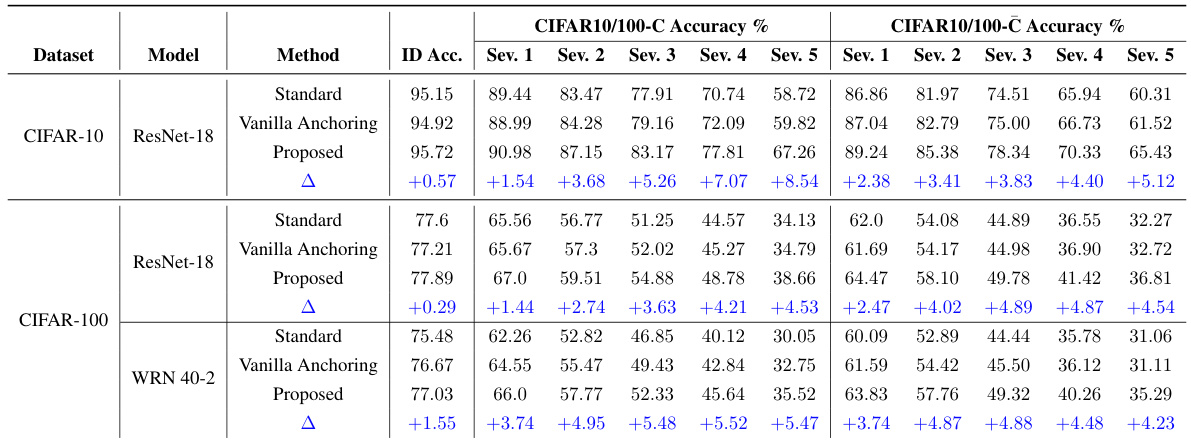
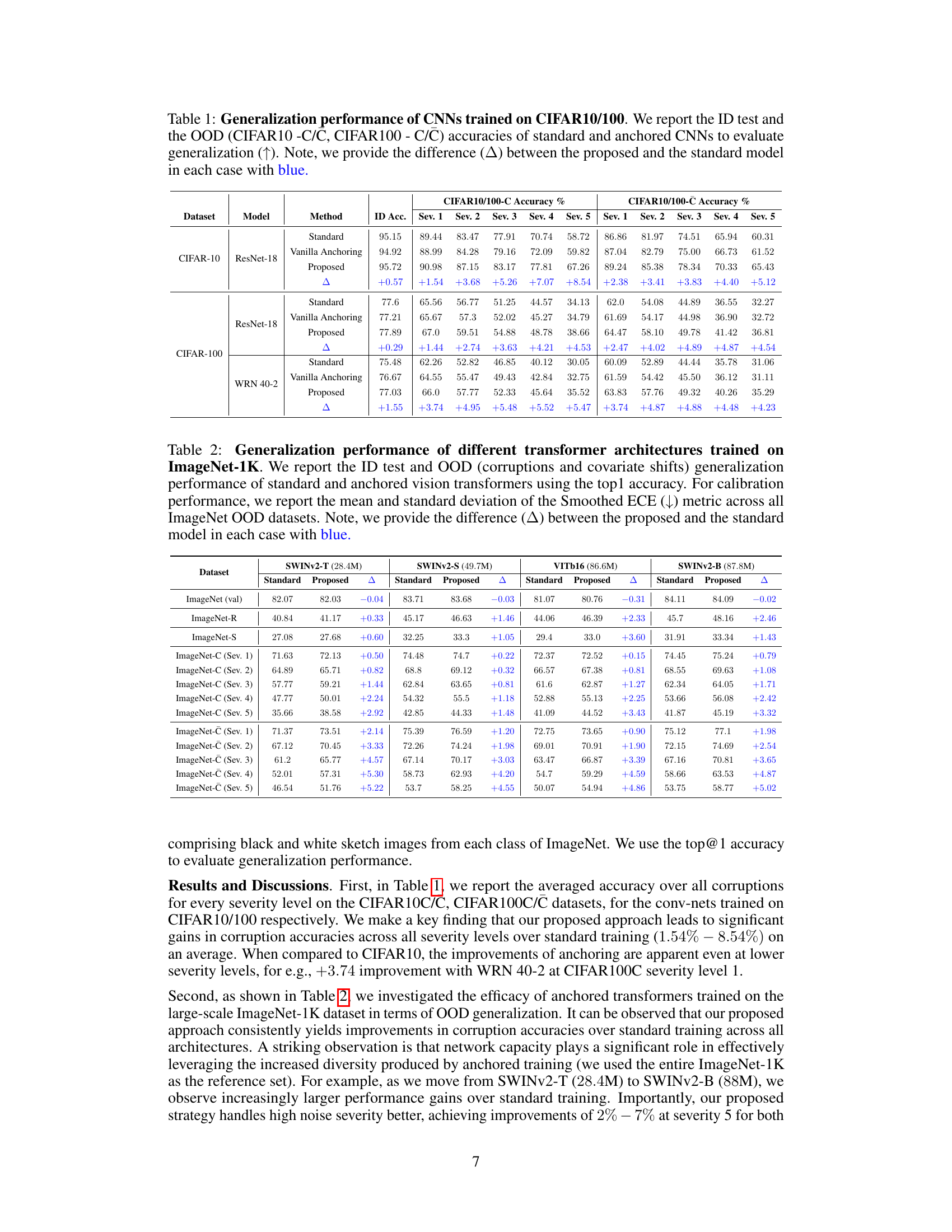
This table presents a comparison of the generalization performance of Convolutional Neural Networks (CNNs) trained on CIFAR10 and CIFAR100 datasets using standard training, vanilla anchoring, and the proposed anchored training method. The evaluation includes in-distribution (ID) accuracy and out-of-distribution (OOD) accuracy on CIFAR10-C, CIFAR100-C, CIFAR10-C, and CIFAR100-C datasets. The table highlights the improvement achieved by the proposed method compared to standard training and vanilla anchoring across different corruption severities.

This table presents a comparison of the generalization performance between standard and anchored transformer models on the ImageNet-1K dataset. It includes in-distribution (ID) and out-of-distribution (OOD) accuracy results across various datasets, measuring robustness to different types of image corruptions and covariate shifts. The table also shows calibration performance using the Smoothed ECE metric.
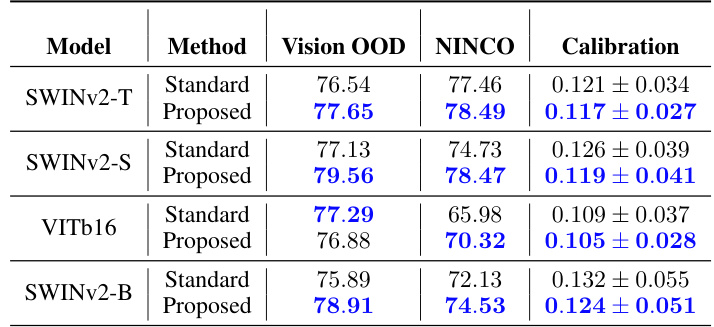
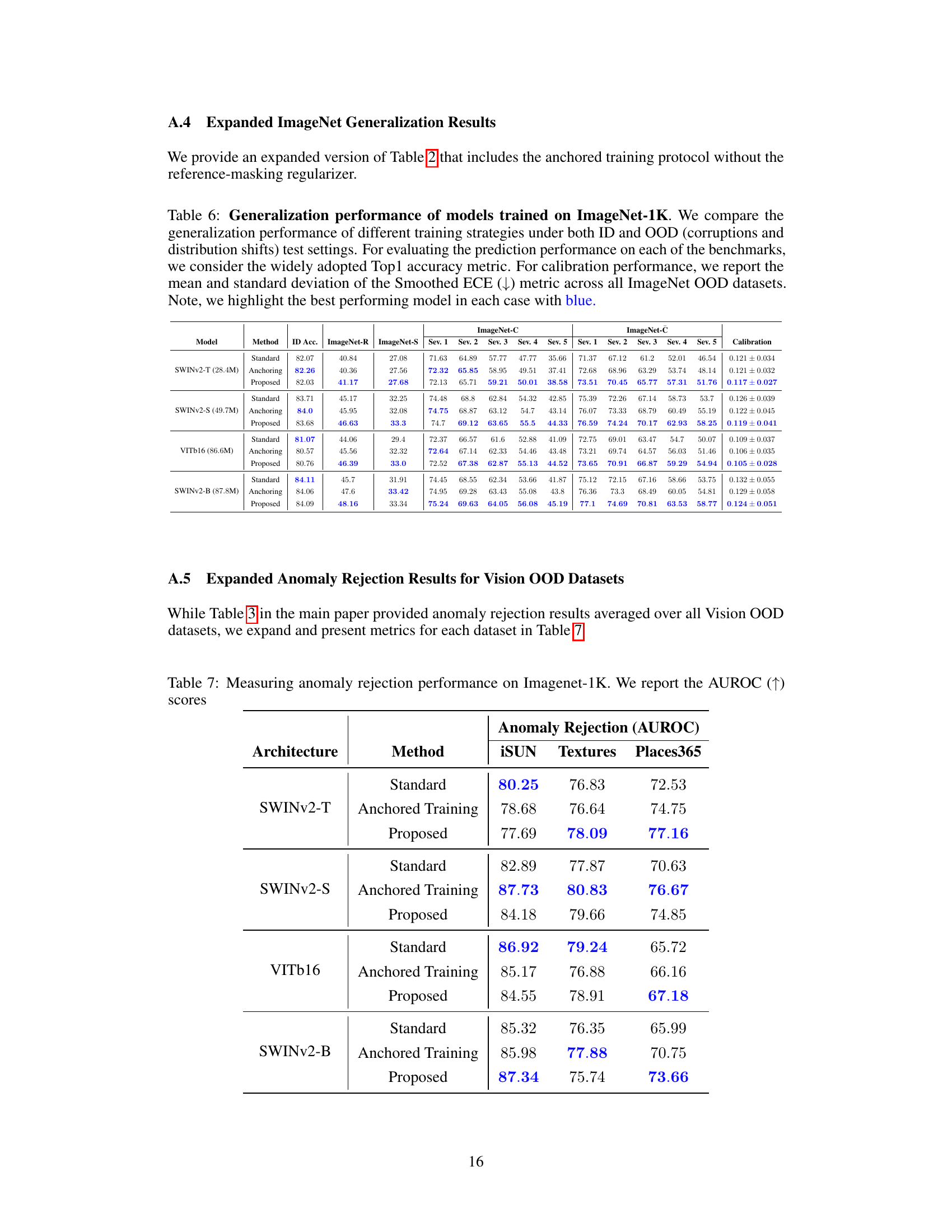
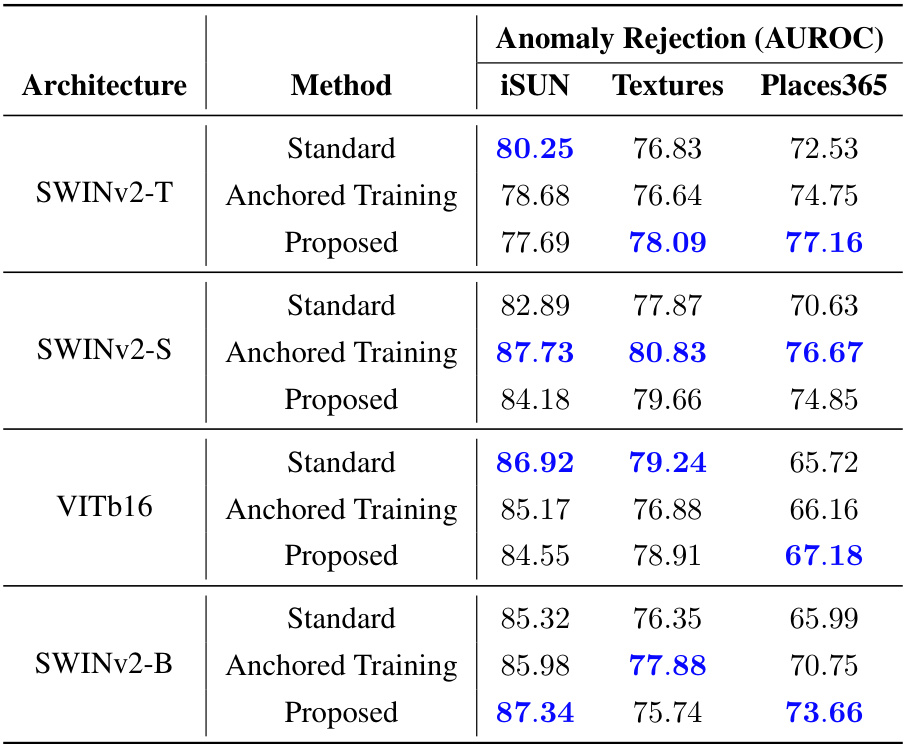
This table presents the results of anomaly rejection and calibration performance evaluation on various vision models trained on ImageNet-1K. It compares the performance of standard training against a proposed method, using metrics such as AUROC for anomaly detection and Smoothed ECE for calibration. The models are tested on several benchmark datasets, including common Vision OOD benchmarks and the NINCO dataset. The best-performing model for each metric is highlighted.
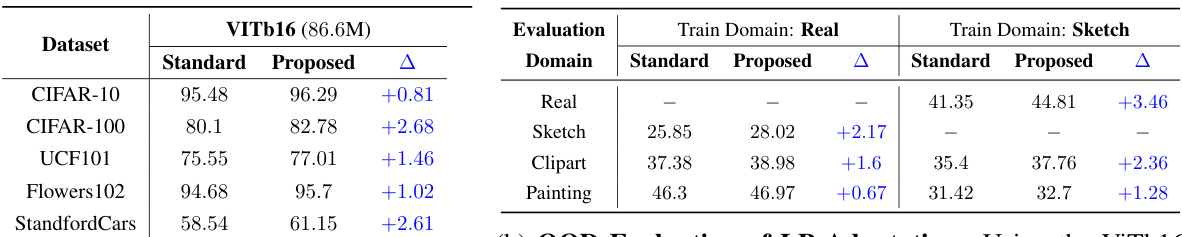
This table presents a comparison of the generalization performance between standard and anchored transformer models on ImageNet-1K. It includes in-distribution (ID) and out-of-distribution (OOD) accuracy using top-1 accuracy, and calibration performance using Smoothed ECE. The models used are different transformer architectures (SWINv2-T, SWINv2-S, ViT-B16, SWINv2-B). The differences between proposed (anchored with reference masking) and standard models are highlighted.
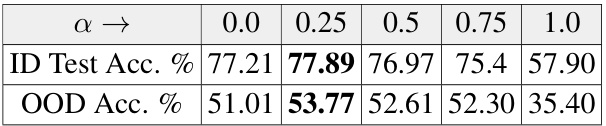
This table shows the impact of the hyperparameter α (which controls the frequency of the regularization applied to anchored training) on the model’s performance. As α increases, there’s a greater risk of over-regularization, leading to underfitting. The table displays the in-distribution (ID) test accuracy and out-of-distribution (OOD) accuracy for different values of α, demonstrating the optimal range for α to balance regularization and performance. The reference set R is set to the entire training dataset (D) for this experiment.

This table summarizes the training protocols used for different models and datasets in the paper. It shows that while standard training recipes were used, anchoring was applied on top of them. The table includes the model, dataset, training recipes, and the number of epochs for both non-anchored and anchored training, as well as the optimizer used.
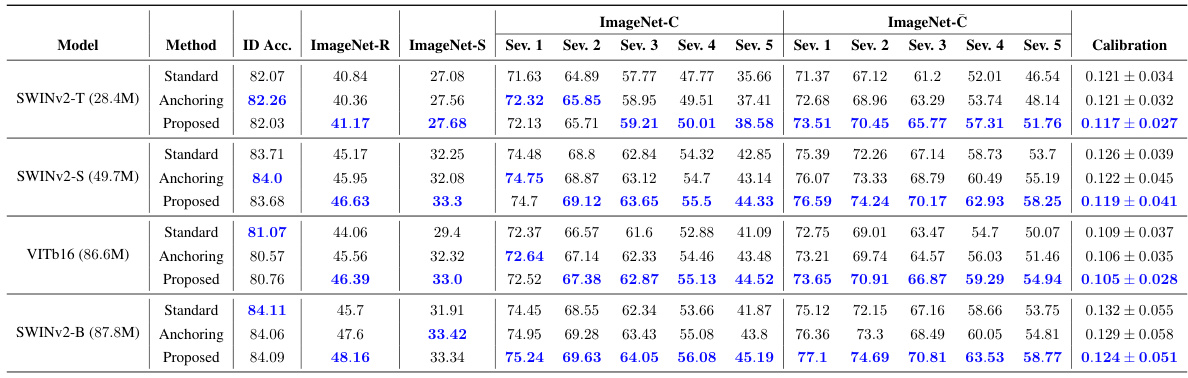
This table presents a comparison of the generalization performance between standard and anchored training methods for various transformer architectures on the ImageNet-1K dataset. It includes in-distribution (ID) accuracy, out-of-distribution (OOD) accuracy across different corruption benchmarks, and calibration metrics (Smoothed ECE). The difference in performance between the proposed and standard models is highlighted.
This table presents a comparison of the generalization performance of Convolutional Neural Networks (CNNs) trained using standard methods and the proposed anchored training method. The performance is evaluated on both in-distribution (ID) and out-of-distribution (OOD) datasets, using CIFAR-10 and CIFAR-100, and their corrupted versions. The table shows ID accuracy and OOD accuracy across different corruption severities, highlighting the improvement achieved by the proposed method. The ‘Δ’ column indicates the difference in performance between the proposed method and the standard method.
Full paper#