↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Existing neural scene representations struggle with large-scale dynamic urban areas due to limited visual quality and slow rendering speeds. Rasterization-based approaches offer speed improvements but are limited to homogeneous data, failing to handle complex variations in appearance and geometry caused by weather, lighting, and seasonal changes. They also cannot efficiently model dynamic objects like vehicles and pedestrians.
The paper introduces 4DGF, a novel hybrid neural scene representation that combines the efficiency of 3D Gaussian primitives with the flexibility of neural fields to overcome these limitations. 4DGF utilizes a graph-based scene representation to handle scene dynamics effectively and achieves state-of-the-art results in novel view synthesis across various benchmarks, exceeding existing methods in speed and visual quality by a significant margin. This efficient and scalable solution opens new possibilities for applications in AR/VR, robotics, and autonomous driving.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision, computer graphics, and robotics focusing on large-scale dynamic scene reconstruction and novel view synthesis. It provides a highly efficient and scalable method, offering significant improvements in rendering speed and visual quality, paving the way for advanced applications in AR/VR and autonomous driving. The hybrid approach of using 3D Gaussians and neural fields opens new avenues for modeling complex dynamic scenes and dealing with heterogeneous data sources. The proposed approach outperforms previous methods by an order of magnitude in both speed and accuracy, making it highly relevant to current research trends and promising for future work. Its flexible scene composition and rendering pipeline also have broad implications for various downstream applications.
Visual Insights#

This figure summarizes the paper’s main idea. It shows how diverse input sequences (images and videos of an urban scene under various conditions) are used to create a unified 3D representation. This representation, based on dynamic 3D Gaussian fields and neural fields, enables the generation of novel views of the scene from arbitrary viewpoints at high speed.

This table presents a comparison of novel view synthesis results on the Argoverse 2 dataset. The metrics used are PSNR, SSIM, and LPIPS, measuring the quality of the generated images. The table compares the proposed method (4DGF) against several state-of-the-art methods. It highlights that 4DGF significantly outperforms existing methods in terms of visual quality while achieving more than a 200x speedup in rendering time.
In-depth insights#
4D Urban Scene NVS#
4D Urban Scene NVS presents a significant challenge in computer vision and graphics, demanding efficient and high-quality novel-view synthesis (NVS) solutions for dynamic, large-scale environments. Existing methods often compromise on visual fidelity or rendering speed, particularly when dealing with heterogeneous data sources (variable weather, lighting, seasons) and diverse dynamic objects. A 4D approach, incorporating time as a dimension, is crucial for realistic representation of urban scenes. Success hinges on developing scene representations capable of handling complex geometry and appearance variations while maintaining interactive rendering speeds. Techniques like 3D Gaussian fields and neural radiance fields show promise, but challenges remain in scaling these approaches to handle large datasets and effectively manage the complexities of urban dynamics. Key research questions include: the optimal balance between explicit and implicit scene representations, efficient methods for modeling scene dynamics (e.g., graph-based representations or neural scene flow fields), and the development of novel rendering algorithms to achieve real-time or near real-time performance. Furthermore, robustness to noise and heterogeneous data is crucial for deployment in real-world applications. Future advances will likely focus on addressing these challenges through a combination of innovative scene representations, efficient rendering techniques, and advanced deep learning architectures.
Gaussian Splatting++#
Gaussian Splatting++ likely builds upon the original Gaussian splatting method, addressing its limitations and enhancing its capabilities. It probably introduces improvements in areas such as rendering speed, achieving higher visual fidelity, and better handling of dynamic scenes and complex geometries. This could involve advancements in the core algorithm, such as optimizing the splatting process for speed, or utilizing more sophisticated neural networks to improve the representation accuracy of 3D objects. The enhancement might also improve the method’s scalability to accommodate larger and more complex scenes, perhaps by incorporating more efficient data structures or hierarchical scene representations. Furthermore, Gaussian Splatting++ may focus on handling the challenges of dynamic elements by either introducing new ways to model temporal changes or by more tightly integrating dynamic object representations. Improved memory efficiency and robust handling of various inputs would also be key improvements.
Neural Field App.#
The heading ‘Neural Field App.’ suggests a section detailing the application of neural fields within a larger research context. This likely involves a description of how the researchers leverage the power of neural fields to solve a specific problem, perhaps related to 3D scene representation or novel view synthesis. A key aspect will be the explanation of the neural field architecture, highlighting its design choices, such as the type of network (e.g., MLP, convolutional), the dimensionality of the input and output, and any specific techniques for efficiency or stability (e.g., hash encoding, multi-resolution representation). The implementation details will be crucial, potentially including information on training data, loss functions, optimization methods, and computational resources utilized. The section should then demonstrate the effectiveness of their neural field application, presenting quantitative results (e.g., PSNR, SSIM) and qualitative comparisons with other methods. Finally, any limitations or challenges encountered in the application of the neural fields should be addressed, including considerations for scalability, generalizability, and robustness. This comprehensive exploration of the ‘Neural Field App.’ section provides a deeper understanding of the research and its contribution to the field.
Dynamic Scene Graph#
A dynamic scene graph offers a powerful paradigm for representing and reasoning about dynamic scenes. It leverages graph structures to model the relationships between scene elements, such as objects and their interactions, enabling efficient representation of complex dynamic systems. The nodes in the graph could represent individual objects, while the edges encode their spatial relations or interactions. The temporal aspect is handled by either including time as a node attribute or by evolving the graph’s structure over time. The advantage of using a dynamic scene graph lies in its ability to capture complex relationships and changes in the scene’s structure over time. This representation is particularly useful for tasks like novel view synthesis, robotic simulation, and activity recognition, where an understanding of the interplay between objects and their interactions is crucial. Challenges include efficient graph construction and maintenance, which may necessitate sophisticated algorithms for tracking objects, predicting their movement, and recognizing new or disappearing objects. Another key challenge is scalability, especially with very large-scale scenes. Effective algorithms are needed to handle the computational complexities of dynamically updating the graph’s structure.
Future of 4DGF#
The future of 4DGF (4D Gaussian Fields) looks promising, building upon its current strengths in handling large-scale dynamic urban scenes. Further advancements in neural field architectures could lead to even more compact and efficient representations, potentially enabling real-time rendering on less powerful hardware. Integrating more sophisticated physics-based models for phenomena like lighting, shadows, and material interactions would elevate the realism of synthesized scenes, while incorporating sensor noise and imperfections could make the system more robust to real-world data. Expanding the scene graph’s capabilities to model more complex object interactions and relationships may improve the fidelity of simulations. Combining 4DGF with other modalities such as LiDAR and semantic segmentation could further enhance scene understanding and improve the accuracy of reconstructions, offering broader application in fields like autonomous driving, virtual reality, and urban planning. Addressing the limitations regarding non-rigid object modeling and the scalability of the ADC (Adaptive Density Control) mechanism remain key research areas. However, with continued development, 4DGF has the potential to become a powerful and versatile tool for creating realistic and interactive digital twins of dynamic urban environments.
More visual insights#
More on figures
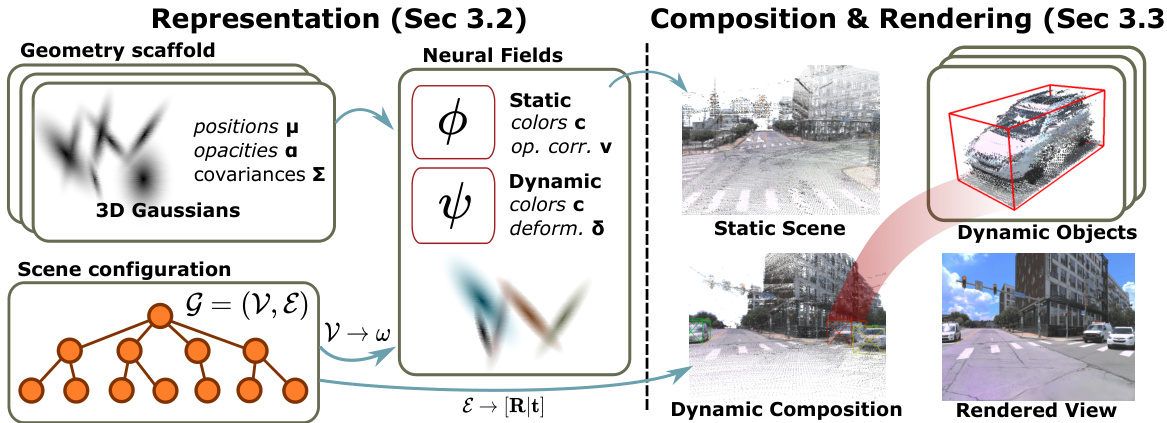
This figure illustrates the overall process of rendering an image using the proposed 4DGF method. It starts with a scene graph representing the scene’s configuration, including latent codes and transformations for dynamic objects. This graph determines which 3D Gaussians are active and feed into neural fields that predict color, opacity corrections for static elements, and deformations for dynamic objects. The results are combined to generate the final rendered image.
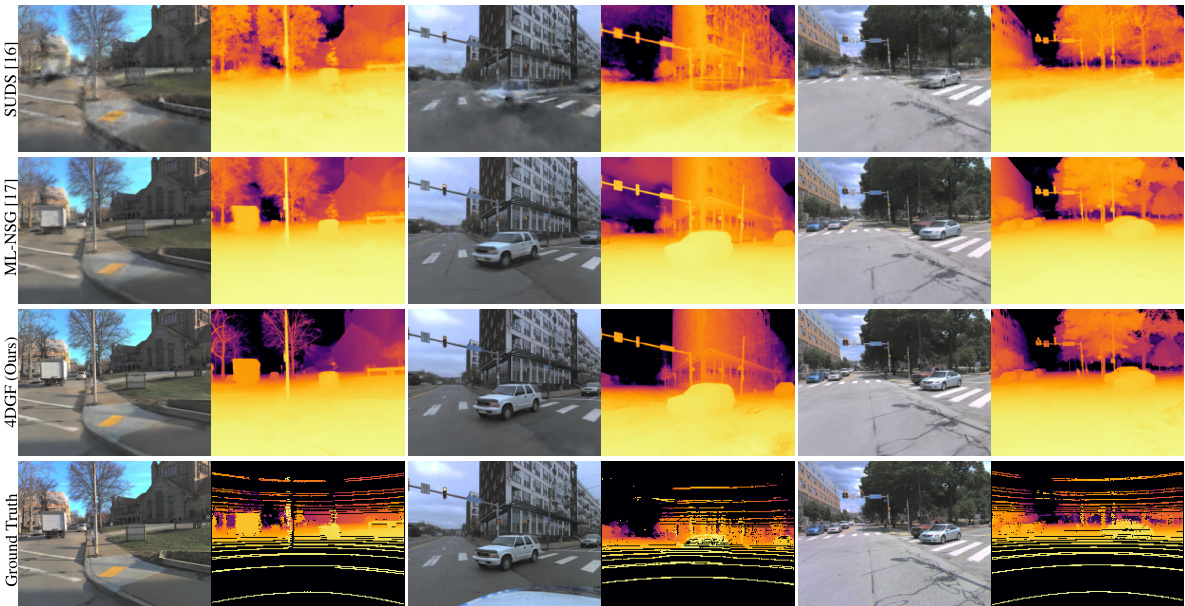
This figure provides a qualitative comparison of the proposed 4DGF method against two state-of-the-art methods, SUDS and ML-NSG, on the Argoverse 2 dataset. The comparison showcases RGB images and depth maps, highlighting the superior visual quality and detail preservation of 4DGF, especially in challenging areas such as the residential and downtown areas within the dataset.

This figure shows a sequence of images generated by the model, demonstrating its ability to accurately represent the articulated motion of a person getting out of a car and walking away. The red box highlights the person for better tracking of their movements.

This figure compares the qualitative results of novel view synthesis on the Argoverse 2 dataset. It showcases the superior sharpness and reduced artifacts produced by the proposed 4DGF method compared to existing methods (SUDS [16] and ML-NSG [17]). The comparison highlights the improved rendering of both dynamic (moving objects) and static (stationary objects) elements in the scene, particularly in areas with transient geometry (elements that change over time, such as tree branches).

This figure shows a comparison of the results obtained using the full model and a model without transient geometry. The full model correctly renders transient objects such as a banner and trees. The model without transient geometry has missing objects and artifacts. The comparison is done for both RGB and depth images.
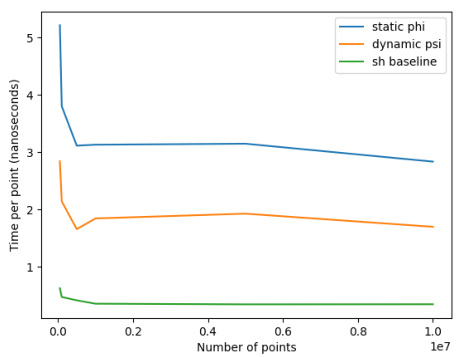
This figure compares the efficiency of using neural fields versus spherical harmonics for rendering. It shows that while spherical harmonics are faster for individual queries, the overall runtime difference is not significant due to other computational factors in the rendering pipeline. The neural field approach offers greater flexibility in representing complex scenes and appearance variations, making it more suitable for large-scale, dynamic urban scene rendering.
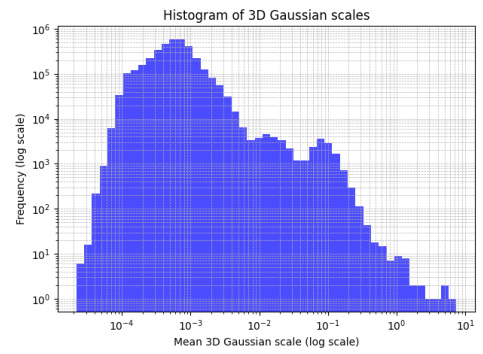
This figure shows a histogram of the mean 3D Gaussian scales used in the model trained on the Argoverse 2 dataset. The x-axis represents the mean scale (in logarithmic scale), and the y-axis represents the frequency (also in logarithmic scale). The histogram shows that most of the 3D Gaussians have small scales, with only a few outliers having very large scales. The scene is approximately bounded within [-1, 1].

This figure compares the qualitative novel view synthesis results of three different methods (SUDS [16], ML-NSG [17], and 4DGF (Ours)) against the ground truth on the Argoverse 2 dataset. The top two rows show examples from a residential area, while the bottom two rows showcase examples from a downtown area. The comparison highlights the differences in visual quality, specifically in terms of sharpness, artifact reduction, and overall fidelity to the ground truth. 4DGF demonstrates superior performance in generating sharper, more realistic images compared to the other two methods.

This figure shows qualitative results of the proposed method on the Waymo Open dataset. The figure shows a sequence of images rendering a street scene with pedestrians. The results demonstrate the model’s ability to accurately model articulated motion (pedestrians walking and carrying objects) and non-rigid deformations. It highlights that the model can faithfully generate novel views of dynamic scenes.
More on tables
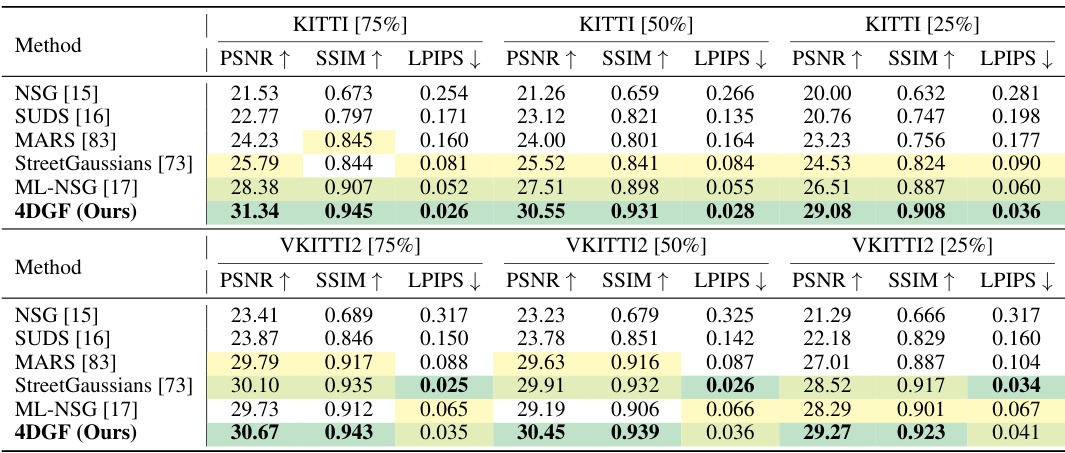
This table presents the results of novel view synthesis experiments conducted on the KITTI and VKITTI2 datasets. The results compare the performance of the proposed 4DGF method against several state-of-the-art techniques, using PSNR, SSIM, and LPIPS metrics. The comparison is performed at three different training view fractions (75%, 50%, and 25%) to demonstrate the robustness and scalability of 4DGF across varying data conditions.
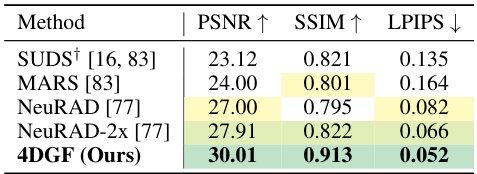
This table compares the performance of different novel view synthesis methods on the KITTI dataset. The methods are evaluated using the PSNR, SSIM, and LPIPS metrics, which measure the visual quality of the generated images. The table specifically uses a data split from a different paper ([77]) and includes a baseline ([83]). The results show that the proposed method, 4DGF, outperforms existing methods on this benchmark.
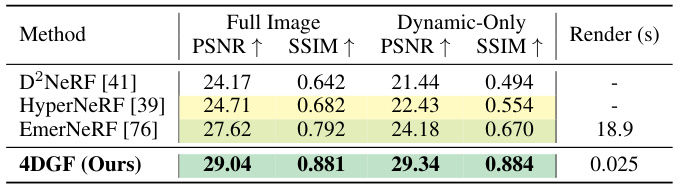
This table shows the results of novel view synthesis on the Waymo Open dataset using the Dynamic-32 split. The table compares the performance of the proposed 4DGF method against other state-of-the-art methods, focusing on PSNR, SSIM, and rendering speed. It highlights the superior performance of 4DGF, particularly in maintaining high visual quality in dynamic areas, which is a common problem for other methods. The rendering speed of 4DGF is significantly faster than the other methods presented.

This table presents a comparison of novel view synthesis results on the Argoverse 2 dataset. It compares the proposed 4DGF method against several state-of-the-art techniques, evaluating performance using PSNR, SSIM, and LPIPS metrics. A key finding is that 4DGF significantly outperforms existing methods in terms of both visual quality (PSNR, SSIM, LPIPS) and rendering speed.

This table presents a comparison of novel view synthesis results on the Argoverse 2 dataset. It compares the proposed 4DGF method against several state-of-the-art techniques using metrics such as PSNR, SSIM, and LPIPS. The table highlights 4DGF’s significant improvements in visual quality and rendering speed. The results demonstrate that 4DGF achieves a substantial improvement over existing methods, exceeding them by over 3 dB in PSNR while achieving more than a 200x speed increase. This showcases the efficiency and effectiveness of the proposed 4DGF approach for novel view synthesis in large-scale, dynamic urban environments.

This table presents a comparison of novel view synthesis results on the Argoverse 2 dataset. It compares the proposed 4DGF method against several state-of-the-art techniques, evaluating performance based on PSNR, SSIM, LPIPS, and rendering speed. The results show that 4DGF significantly outperforms existing methods in terms of visual quality (PSNR, SSIM, LPIPS) and achieves a more than 200x speedup in rendering.
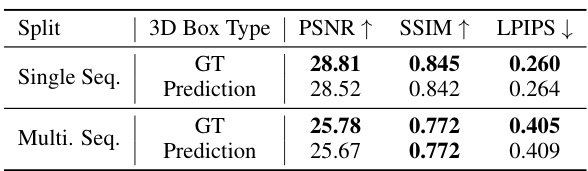
This table presents ablation studies on two aspects of the model: (a) the impact of using 3D bounding box annotations from a pre-trained 3D tracker and (b) the effect of including the deformation head for non-rigid object motion modeling. The results show that the model performs well even with noisy inputs from the 3D tracker and that including the deformation head improves performance.
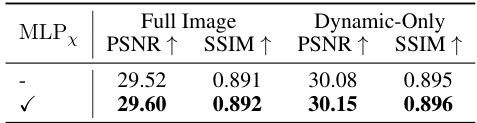
This table presents the results of ablation studies conducted to evaluate the impact of different design choices on the overall performance of the proposed 4DGF model. Specifically, it investigates the effects of using 3D bounding boxes for dynamic object representation and the inclusion of a deformation head for modeling non-rigid object motion. Part (a) compares the results on a single residential sequence and the full dataset, while part (b) focuses on a subset of the data with a higher concentration of non-rigid objects.

This table presents the ablation study comparing the performance of vanilla Adaptive Density Control (ADC) against the modified ADC proposed in the paper. The comparison is done on a single sequence setting using PSNR, SSIM, LPIPS, and the total number of 3D Gaussians and object 3D Gaussians. The results show that the modified ADC outperforms the vanilla version in terms of image quality metrics and results in a higher number of 3D Gaussians, especially for object 3D Gaussians.
Full paper#



















