↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Current multi-modal image fusion methods struggle with complex degradations in source images and often ignore foreground object specificity. This leads to fused images with noise, color bias, and poor exposure, weakening the salience of objects of interest. The limitations of existing methods highlight the need for a more robust and user-friendly approach.
Text-DiFuse addresses these issues by introducing a novel interactive framework that uses a text-modulated diffusion model. It integrates feature-level information integration into the diffusion process, allowing for adaptive degradation removal and multi-modal fusion. The text-controlled fusion strategy lets users customize the fusion process via text input, enhancing the salience of foreground objects. This framework demonstrates state-of-the-art results across various scenarios, showcasing improvements in both visual quality and semantic segmentation, marking a significant advance in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image fusion and diffusion models. It bridges the gap between information fusion and diffusion models, opening exciting new avenues for visual restoration and multi-modal understanding in challenging scenarios. By introducing text-controlled fusion, it also advances the field of interactive image fusion, which allows more customized and tailored output, based on the need of the user. The code availability further enhances its impact, facilitating broader adoption and future development within the research community.
Visual Insights#

This figure illustrates the proposed explicit coupling paradigm of multi-modal information fusion and diffusion. It compares the existing method DDFM (ICCV 2023) with the authors’ proposed method, Text-DiFuse. The diagram shows how two source images (Source Image 1 and Source Image 2) are processed through separate diffusion processes before being explicitly fused using a diffusion fusion module. The fusion happens at the feature level within the diffusion process, allowing for the adaptive degradation removal and multi-modal information integration. The resulting fused image is generated after multiple steps of the diffusion process. The figure highlights the key difference between the existing approach and the proposed Text-DiFuse method in terms of integrating information fusion into the diffusion process.
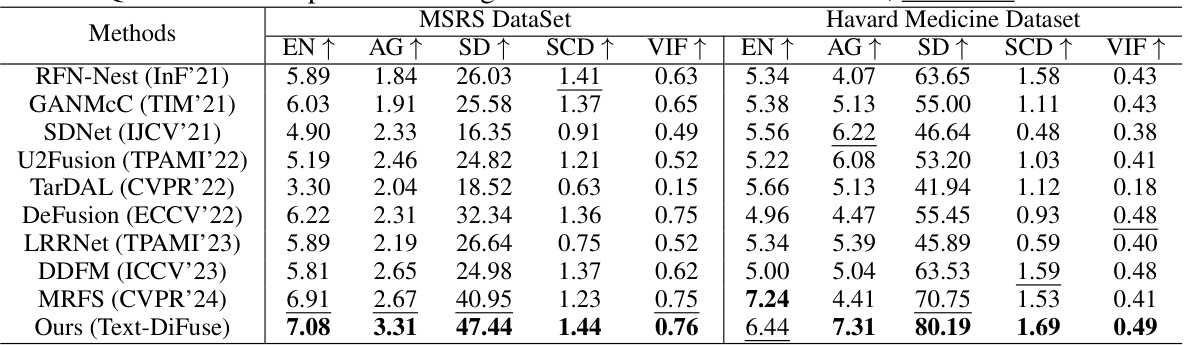
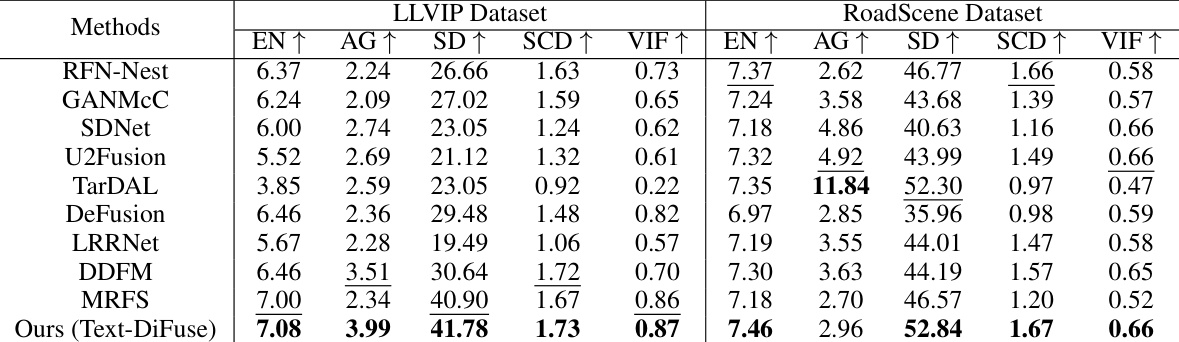
This table presents a quantitative comparison of different image fusion methods on two datasets: MSRS and Harvard Medicine. The methods are evaluated using five metrics: EN, AG, SD, SCD, and VIF. Higher scores generally indicate better performance. The table highlights the best and second-best performing methods for each metric and dataset, providing a clear overview of the relative strengths and weaknesses of each approach.
In-depth insights#
Multimodal Fusion#
Multimodal fusion, as discussed in the provided research paper, is a critical technique for integrating information from diverse sources, such as infrared and visible images, to create a more comprehensive representation of the scene. The core challenge lies in effectively combining these disparate data modalities while overcoming degradations like noise and color inconsistencies. The paper emphasizes the importance of explicitly coupling the fusion process with the diffusion model, enabling adaptive degradation removal and information fusion within a unified framework. This approach contrasts with existing methods that often treat fusion and restoration as separate stages, potentially leading to suboptimal results. Furthermore, incorporating text-based control allows for user-guided manipulation, highlighting objects of interest and enhancing overall semantic understanding. The framework presented showcases the benefits of this unified paradigm by achieving state-of-the-art results on various datasets. However, the computational cost remains a limitation, prompting future research towards improved efficiency without compromising performance. The success of this model highlights the potential of text-modulated diffusion models for multimodal image fusion tasks, particularly in scenarios with compound degradations.
Diffusion Models#
Diffusion models have emerged as powerful generative models, excelling in various image synthesis tasks. Their core mechanism involves a gradual process of adding noise to an image until it becomes pure noise, followed by a reverse process of progressively denoising to reconstruct the original image or generate a new one. This forward diffusion process is deterministic, while the reverse process is learned, typically via a neural network that predicts the noise added at each step. Key advantages include their ability to generate high-quality, diverse images and their capacity to handle complex degradation removal, making them attractive for image fusion applications. However, significant challenges remain: the computational cost of the iterative denoising process can be high; training these models can be data-intensive and requires substantial resources. Furthermore, the inherent stochastic nature of the reverse process poses challenges for controlling the generated outputs precisely. Therefore, future research directions should prioritize optimizing efficiency and controllability while maintaining high generative capabilities.
Text Control#
The concept of ‘Text Control’ in the context of a multi-modal image fusion framework offers a powerful mechanism for user interaction and customization. It allows users to guide the fusion process by providing textual descriptions of desired outcomes, such as highlighting specific objects or emphasizing certain features. This capability moves beyond traditional automated approaches, enabling fine-grained control over the final fused image. By incorporating a text-based interface, the system becomes more intuitive and accessible to a wider range of users, eliminating the need for expert-level knowledge of image processing techniques. The underlying technology likely involves a combination of natural language processing to interpret the text commands and a sophisticated image fusion model that can intelligently respond to these instructions. This approach is particularly useful in scenarios with complex or ambiguous source images, where subtle adjustments can significantly improve the visual quality and semantic understanding of the fused result. The effectiveness of text control will depend on the robustness of the natural language processing component and the sophistication of the fusion algorithm’s ability to map textual input to visual manipulation. The integration of zero-shot learning techniques might further enhance the model’s ability to generalize to new object categories not explicitly encountered during training, expanding the potential utility of text control. The combination of text-based control and advanced image fusion methods represents a significant advancement in the field, offering a more user-centric and versatile approach to multi-modal image fusion.
Degradation Removal#
The concept of degradation removal is central to the paper’s approach to multi-modal image fusion. The authors recognize that source images often suffer from compound degradations, including noise, color bias, and exposure issues. Their proposed framework directly addresses these problems by embedding the degradation removal process within the diffusion model itself. This is a significant departure from existing methods, which typically treat degradation removal and information fusion as separate steps. By integrating these processes, the authors achieve improved results as the fusion process inherently benefits from cleaner, more consistent input. The explicit coupling of degradation removal and information fusion within the diffusion process, therefore, is a key innovation that enables the framework to handle complex degradation scenarios effectively. The framework’s ability to handle these degradations is validated through extensive experimental results, demonstrating state-of-the-art performance across multiple datasets.
Future Scope#
The future scope of text-modulated diffusion models in multi-modal image fusion is incredibly promising. Improved efficiency is a crucial area; current methods are computationally expensive, limiting real-time applications. Exploration of more efficient diffusion model architectures and sampling techniques is vital. Furthermore, enhancing the robustness to diverse degradation types beyond the current scope is key. The model’s performance in challenging scenarios, such as extreme low-light or heavy noise conditions, could be significantly improved. Research into incorporating more sophisticated zero-shot location models will refine object saliency control. Exploring alternative text modalities, including audio descriptions or even visual cues, could broaden the scope of interaction and enhance the fusion process. Finally, developing comprehensive benchmarks for evaluating the performance of interactive, text-controlled fusion across varied datasets and degradation levels is necessary to propel the field forward.
More visual insights#
More on figures
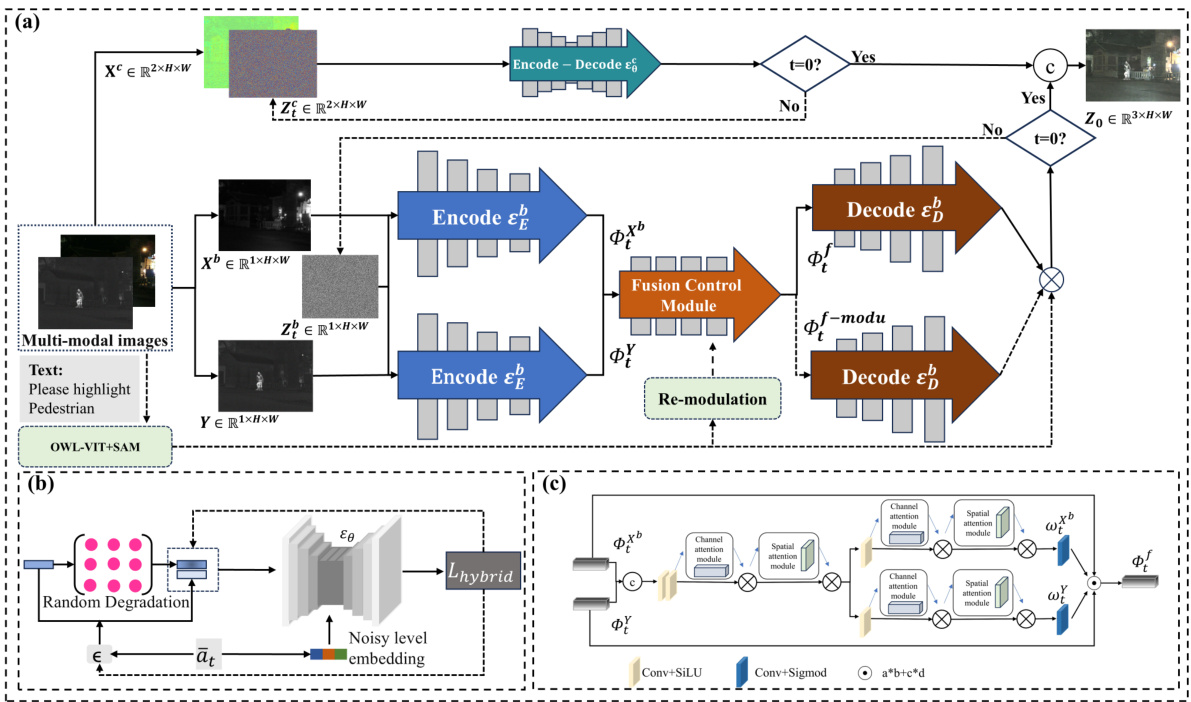
This figure illustrates the pipeline of the Text-DiFuse model, an interactive multi-modal image fusion framework based on a text-modulated diffusion model. Panel (a) shows the overall process, starting with multi-modal images and text input. The model uses a text-controlled diffusion fusion process, with independent conditional diffusion steps for degradation removal. Multi-modal information is fused using a Fusion Control Module (FCM). Finally, a text-controlled re-modulation strategy is applied to highlight objects of interest. Panel (b) details the training of the diffusion model for degradation removal, showing how random degradation is introduced and then processed through the encoder-decoder network. Panel (c) zooms in on the FCM structure, highlighting its use of channel and spatial attention modules to manage feature integration in a multi-modal context.

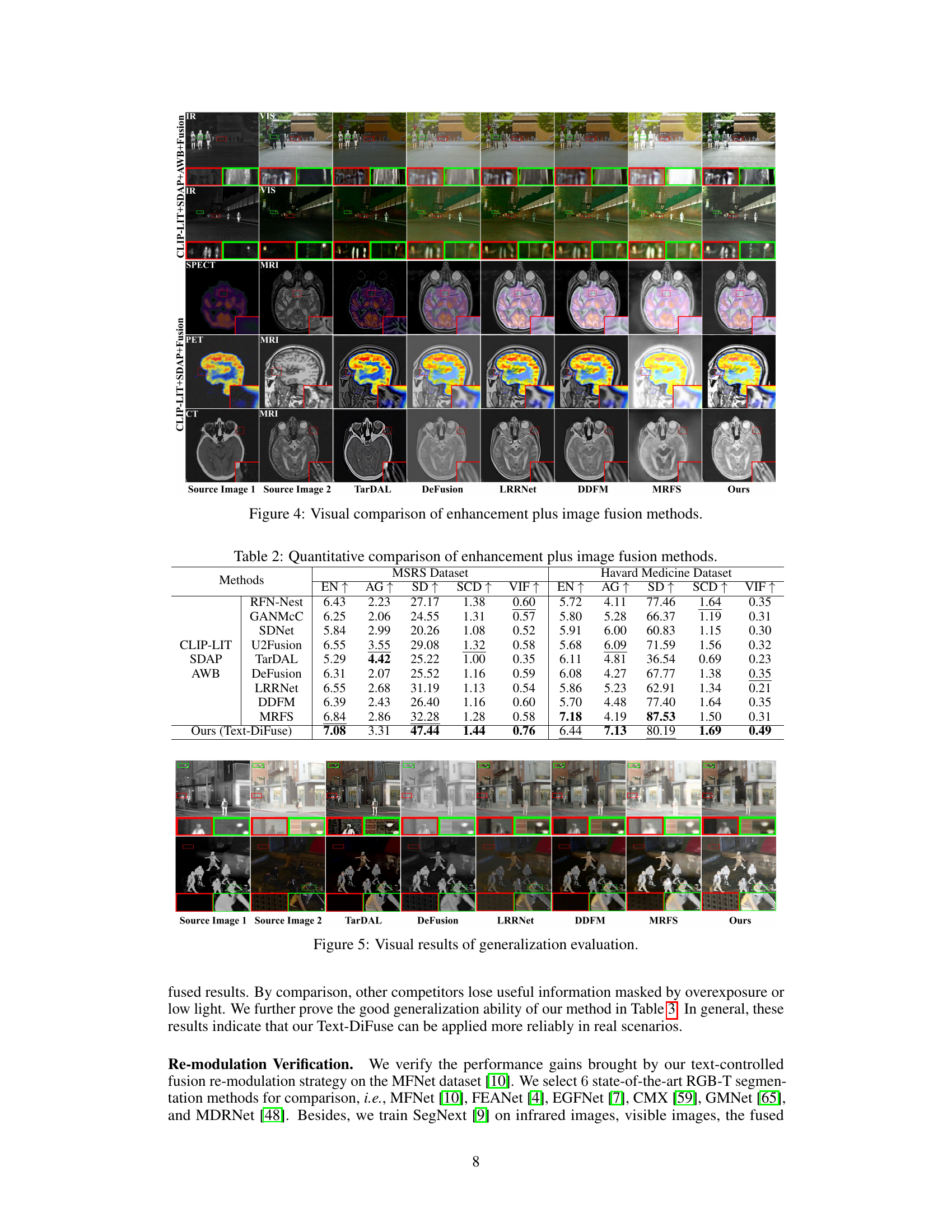
This figure presents a visual comparison of image fusion results obtained using different methods on various datasets. The top two rows showcase infrared and visible image fusion, highlighting improvements in color correction, noise reduction, and overall clarity achieved by the proposed method (Ours) compared to other state-of-the-art techniques (TarDAL, DeFusion, LRRNet, DDFM, MRFS). The following rows demonstrate medical image fusion, again showing that the proposed method excels at preserving important physiological structures while maintaining functional distribution, outperforming other approaches in image quality and information preservation. The red boxes highlight regions of interest to emphasize the differences in fusion quality.

This figure compares the results of various image fusion methods after pre-processing with enhancement techniques (CLIP-LIT, SDAP, and AWB). The top two rows show infrared and visible image fusion results, while the bottom rows demonstrate medical image fusion results (SPECT-MRI, PET-MRI, and CT-MRI). Each column represents a different method: TarDAL, DeFusion, LRRNet, DDFM, MRFS, and the proposed ‘Ours’ method. The figure visually demonstrates the performance of each fusion method in improving image quality by comparing the fused images with the original source images.

This figure provides a visual comparison of different image fusion methods, including the proposed Text-DiFuse method and several state-of-the-art techniques. The comparison is performed on both infrared and visible image fusion (IVIF) and medical image fusion (MIF) scenarios. The results visually demonstrate the superior performance of Text-DiFuse in terms of noise reduction, color correction, detail preservation, and overall image quality.

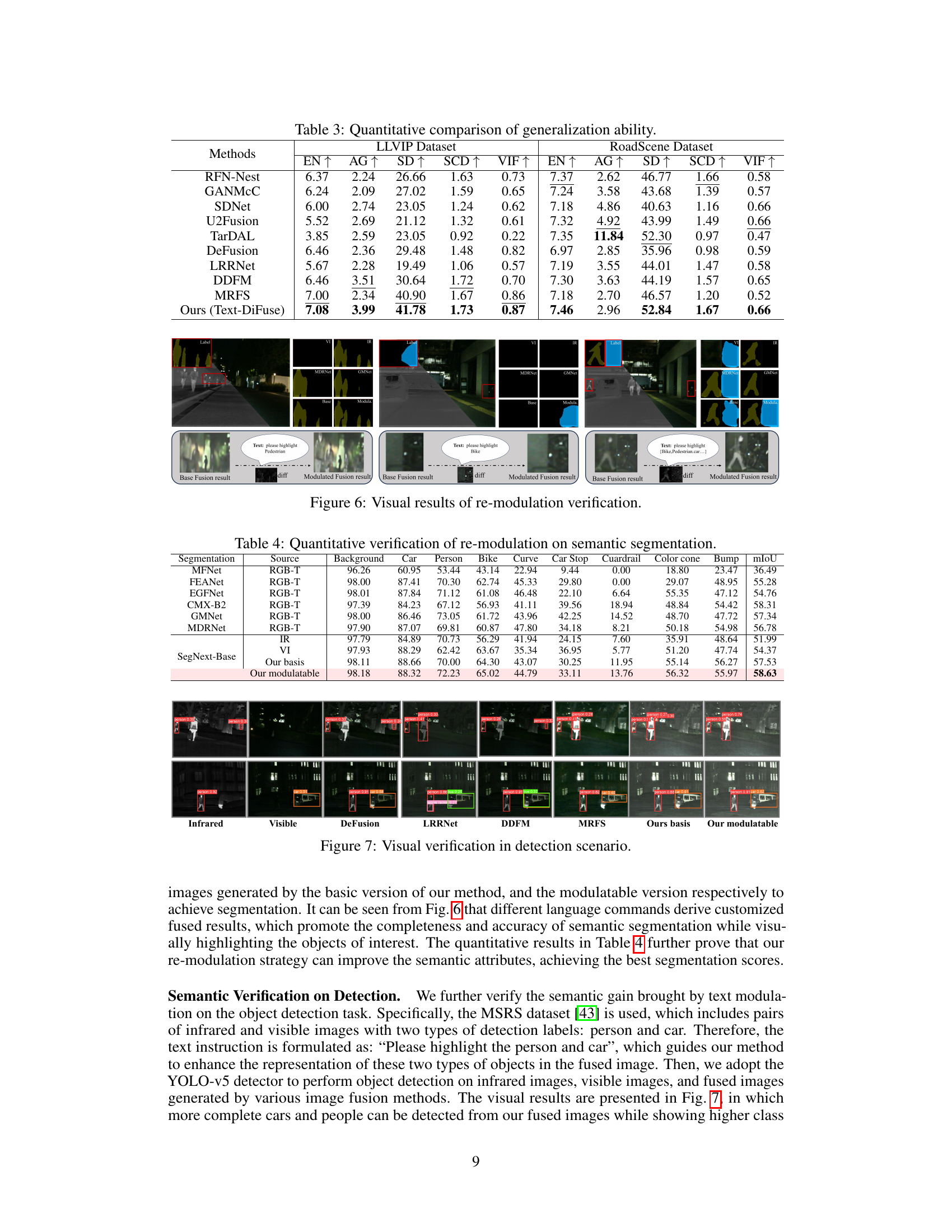
This figure shows the visual results of the re-modulation verification experiments. Three different scenarios are presented, each with a different text prompt for customization. The left side of each scenario shows the results of the base fusion model, and the right side shows the results after applying the text-controlled re-modulation strategy. The goal is to demonstrate the ability of the Text-DiFuse model to interactively enhance the salience of specific objects based on user-provided text instructions. Each scenario includes segmentation results to illustrate the impact of the text prompt on object identification.

This figure illustrates the pipeline of the Text-DiFuse model, a novel interactive multi-modal image fusion framework. It shows three main parts: (a) the text-controlled diffusion fusion process, where text input guides the fusion of multi-modal images; (b) the training of the diffusion model for degradation removal, which learns to remove various degradations from input images; and (c) the detailed structure of the fusion control module (FCM), the core component that integrates multi-modal features and manages their fusion during the diffusion process. The FCM uses spatial and channel attention mechanisms to weigh the importance of features from different modalities. This comprehensive diagram details how the Text-DiFuse model combines text-guided image fusion with a diffusion model for robust and high-quality results.

This figure presents visual results from ablation studies on the Text-DiFuse model. The top row shows the results under various modifications, removing components like the fusion control module (FCM) or different fusion strategies. The bottom row shows a comparison between the basic version of the Text-DiFuse and the modulatable version. Each column represents an input image (infrared and visible), and the subsequent images show fusion results of different versions, illustrating the impact of each removed component or strategy on the final fusion outcome. The aim is to show how different components contribute to the overall performance of the Text-DiFuse.
More on tables
This table presents a quantitative comparison of different image fusion methods on two datasets: MSRS and Harvard Medicine. The methods are evaluated using five metrics: EN, AG, SD, SCD, and VIF. Higher scores generally indicate better performance. The table highlights the best and second-best performing methods for each metric and dataset, offering a clear comparison of Text-DiFuse against state-of-the-art techniques.

This table presents the quantitative results of object detection experiments, comparing different image fusion methods. The methods are evaluated using two metrics: mAP@0.5 (mean Average Precision at IoU threshold of 0.5) and mAP@[0.5:0.95] (mean Average Precision at IoU thresholds ranging from 0.5 to 0.95). The results show the performance improvements achieved by the proposed Text-DiFuse method, particularly its text-controlled version, compared to existing state-of-the-art image fusion techniques.

This table presents a quantitative comparison of different image fusion methods on two datasets: MSRS and Harvard Medicine. The methods are evaluated using five metrics: EN, AG, SD, SCD, and VIF. Higher scores generally indicate better performance. The table highlights the best and second-best performing methods for each metric on each dataset, allowing for a direct comparison of the proposed Text-DiFuse method against existing state-of-the-art techniques.
Full paper#