↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Generating realistic images from natural language is challenging due to the limitations of linear structures in representing complex relationships between multiple objects. Existing text-to-image or layout-to-image models often struggle with such tasks. Scene graphs provide a powerful structured representation of a scene, but directly using them for image generation has limitations, resulting in illogical spatial arrangements or missing objects.
To address these challenges, this paper introduces DisCo, a novel framework. DisCo first uses a Semantics-Layout Variational AutoEncoder (SL-VAE) to disentangle layout and semantics from the input scene graph, allowing for more diverse and reasonable image generation. Then, it integrates these disentangled elements into a diffusion model with a Compositional Masked Attention (CMA) mechanism. Furthermore, DisCo’s Multi-Layered Sampler (MLS) enables object-level graph manipulation while maintaining visual consistency. Through extensive experiments, DisCo significantly outperforms current text/layout/scene-graph based approaches, demonstrating its superior generation rationality and controllability.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to image generation that significantly improves the ability to create complex scenes with intricate relationships between objects. Its generalizable framework for object-level graph manipulation opens new avenues for research in image editing and manipulation, controllability, and the intersection of computer vision and natural language processing. The superior results achieved, shown in various benchmark comparisons, validate its effectiveness. This research is highly relevant to current trends in image generation and scene understanding.
Visual Insights#
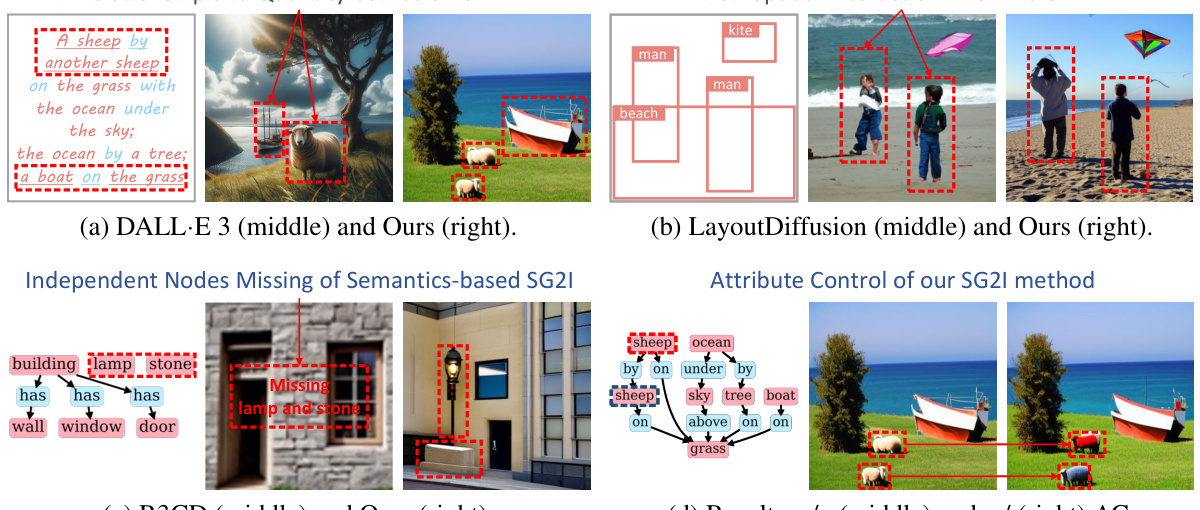
This figure showcases the limitations of existing text-to-image (T2I), layout-to-image (L2I), and semantics-based scene graph to image (SG2I) methods in generating complex scenes. Specifically, (a) demonstrates the inability of DALL-E 3 to accurately represent relationships and quantities in a complex scene. (b) shows LayoutDiffusion’s struggles with non-spatial interactions. (c) highlights the missing independent nodes from R3CD. Finally, (d) demonstrates the improved, consistent object attribute control achieved by the authors’ proposed DisCo method.
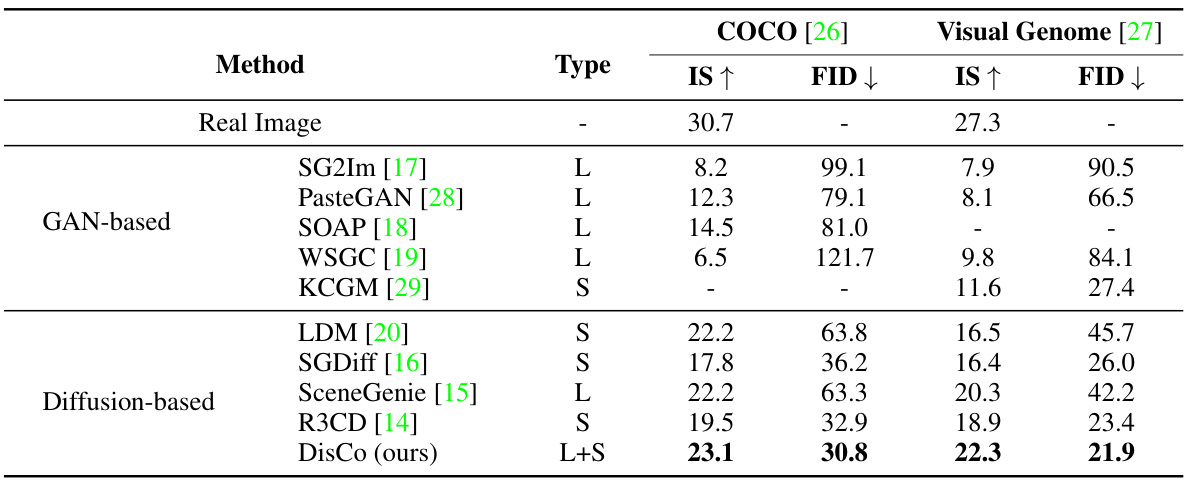
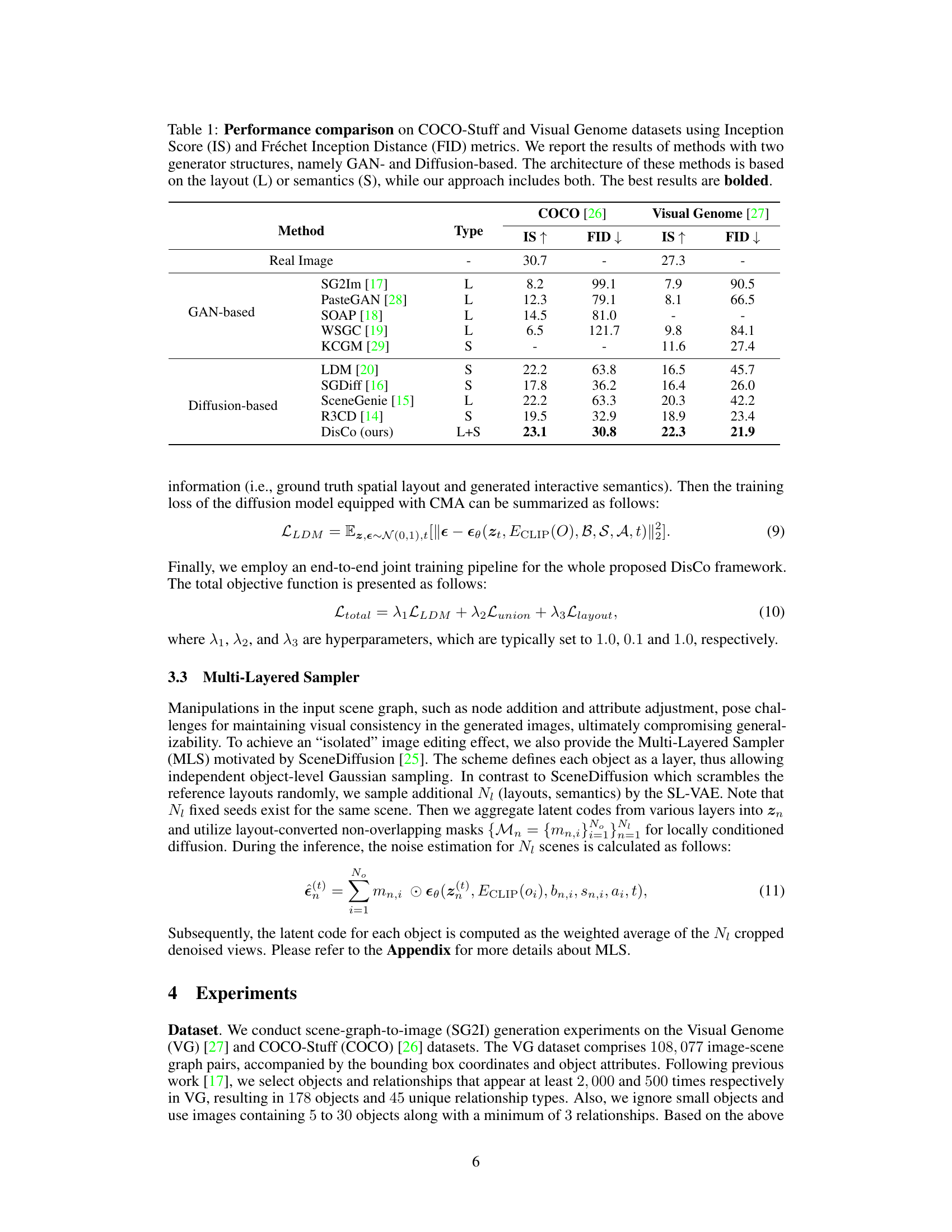
This table presents a quantitative comparison of the proposed DisCo model against several state-of-the-art GAN-based and diffusion-based image generation methods on two benchmark datasets: COCO-Stuff and Visual Genome. The comparison focuses on two key metrics: Inception Score (IS) and Fréchet Inception Distance (FID). IS measures the quality and diversity of generated images, while FID assesses the similarity between generated and real images. The table highlights DisCo’s superior performance, outperforming existing models in both IS and FID scores, and showcasing the benefit of using a combined layout and semantics approach compared to models based solely on layout or semantics.
In-depth insights#
Scene Graph Power#
The concept of “Scene Graph Power” in the context of image generation refers to the effectiveness of scene graphs in representing complex scenes and guiding image synthesis. A strong scene graph captures object relationships and spatial arrangements in a structured format. This structured representation allows for more controllable and accurate image generation, surpassing the limitations of methods solely based on text or layouts. The power comes from the ability to disentangle spatial layouts and interactive semantics, enabling diverse and reasonable generation of images while maintaining visual consistency. Handling non-spatial interactions and generating independent nodes accurately becomes possible through the detailed representation inherent in scene graphs. By leveraging scene graphs, the model can generate images that accurately reflect complex relationships, avoiding common errors like miscounting objects or improperly depicting spatial relationships. Therefore, “Scene Graph Power” emphasizes the ability to translate complex visual information into a structured format that facilitates better, more nuanced, and controlled generation of complex images.
Disentangled Encoding#
Disentangled encoding, in the context of scene graph-based image generation, aims to separate the semantic and spatial information within a scene graph into independent latent representations. This is crucial because directly using scene graphs can lead to entanglement, where the model struggles to isolate individual object attributes or relationships. A well-designed disentangled encoding method will allow for greater controllability during image generation, enabling independent manipulation of object attributes, spatial layouts, or relationships. Variational Autoencoders (VAEs) are often employed for this purpose, learning a latent space where different factors of variation (semantics, layout, etc.) are represented by independent dimensions. The effectiveness of disentangled encoding is assessed by evaluating the model’s ability to generate images with specific modifications to individual objects or their relations while preserving other aspects of the scene. Success in disentanglement allows for more flexible and creative control over image generation, pushing the boundaries of current methods.
CMA Attention#
The proposed Compositional Masked Attention (CMA) mechanism is a crucial contribution, designed to address the challenges of integrating object-level scene graph information into the diffusion process. Unlike standard attention mechanisms that might lead to relational confusion or attribute leakage, CMA incorporates object-level graph information along with fine-grained attributes, preventing these issues. This is achieved through a masked attention operation that selectively focuses on relevant object features, guided by the disentangled spatial layouts and interactive semantics derived from the scene graph’s visual and textual information. The effectiveness of CMA lies in its ability to bridge the gap between global relational information from the scene graph and local visual details in the image. This enables more accurate and contextually aware image generation, significantly improving the overall fidelity and coherence of the results, especially for complex scenarios with multiple interacting objects. By carefully controlling the flow of information, CMA contributes to generalizable and controllable image synthesis that accurately reflects the nuanced relationships described in the input scene graph. This targeted attention mechanism is a key innovation in the DisCo framework and proves essential for its superior performance in image generation tasks.
Multi-Layer Sampler#
The Multi-Layer Sampler (MLS) technique, as described in the research paper, is a crucial innovation for enhancing the generalizability and controllability of complex image generation from scene graphs. MLS addresses the challenge of maintaining visual consistency when manipulating the scene graph by introducing an “isolated” image editing effect. This is achieved by treating each object as an independent layer, allowing for object-level Gaussian sampling. Unlike previous methods that rely on scrambling layouts randomly, MLS leverages diverse layout and semantic conditions generated by a Semantics-Layout Variational Autoencoder (SL-VAE). This approach enables more natural and coherent object-level manipulations (i.e., node addition, attribute control) while preserving overall image quality. The incorporation of multiple layers allows for nuanced control over individual objects, making complex image editing operations more manageable and predictable. This is particularly beneficial for generating diverse and complex scenes with multiple interacting elements, something that previous approaches have struggled to achieve. The technique is critical for generating high-quality and visually plausible results within a complex scene graph.
SG2I Generalization#
Scene Graph-to-Image (SG2I) generation aims to synthesize images from scene graph representations, which is a challenging task due to the complexities of visual relationships and object interactions. Generalization in SG2I focuses on the model’s ability to generate diverse and novel images beyond the training data, handling unseen combinations of objects and relationships. This requires robust learning of visual relationships, which often involves disentangling spatial layouts from interactive semantics and integrating both into a unified generation framework. Successful generalization is evident in the ability to handle variations in object attributes, quantities, and relationships within a scene, and to adapt to various scene compositions. A key challenge lies in managing the one-to-many mapping between scene graphs and image possibilities; a single scene graph may correspond to countless possible visual arrangements. Therefore, effective SG2I models must account for the inherent ambiguity in scene graph representations and incorporate mechanisms for controlled generation based on specific layout and semantic constraints. Overall, successful SG2I generalization hinges on strong disentanglement and robust scene representation to produce high-quality, controllable, and contextually appropriate images.
More visual insights#
More on figures
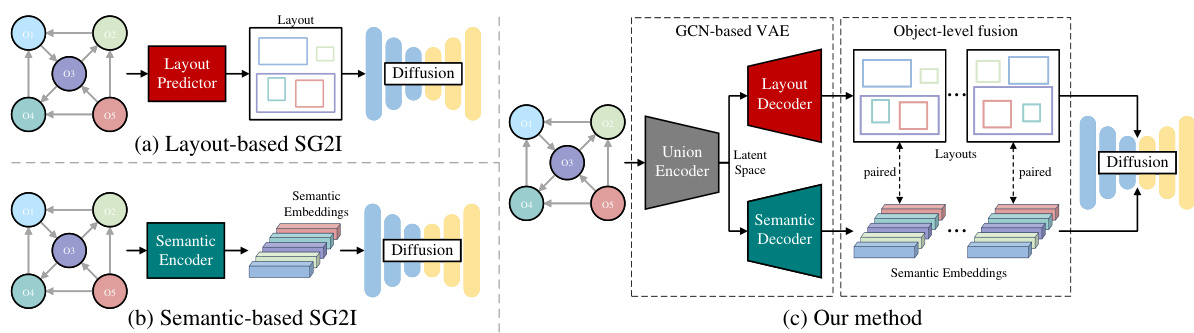
This figure compares three different scene graph to image generation (SG2I) approaches. (a) shows a layout-based approach where a layout predictor first generates the spatial arrangement of objects before image generation. (b) illustrates a semantic-based method that directly encodes graph relationships into node embeddings for generation. Finally, (c) presents the authors’ proposed method (DisCo), which uses a variational autoencoder to disentangle spatial layout and interactive semantics from the scene graph before feeding them into a diffusion model for image generation.
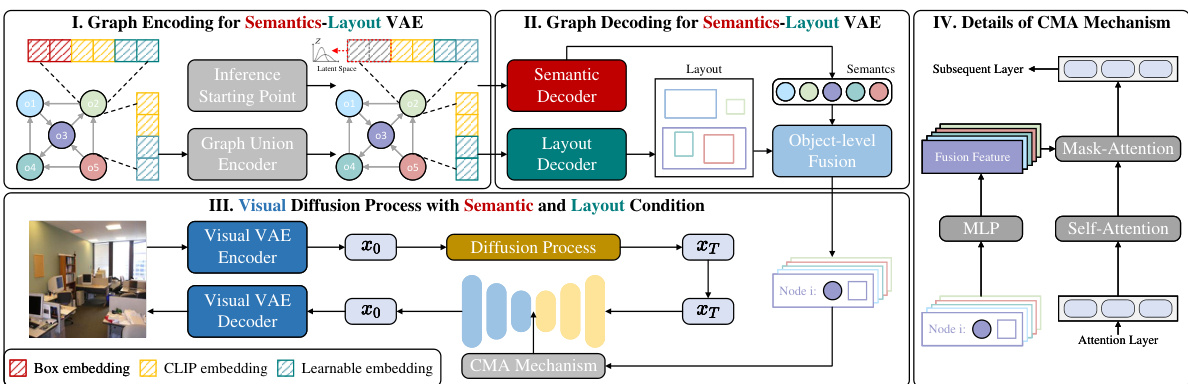
This figure illustrates the framework of DisCo, which consists of four main parts: Graph Encoding for Semantics-Layout VAE, Graph Decoding for Semantics-Layout VAE, Visual Diffusion Process with Semantic and Layout Condition, and Details of CMA Mechanism. The Graph Union Encoder jointly models spatial and non-spatial interactions in scene graphs. The Semantic and Layout Decoders generate spatial layouts and interactive semantics. A diffusion model with CMA incorporates object-level conditions to generate images from the scene graph. The detailed structure of the CMA layer is also shown.

This figure shows a toy example to illustrate the compositional masked attention mechanism. The figure consists of two parts: (a) shows the compositional masked attention mechanism that connects visual tokens and object embeddings based on bounding boxes, and (b) shows the corresponding attention mask that indicates the attention weights between visual tokens and object embeddings.

This figure showcases failure cases from state-of-the-art Text-to-Image (T2I), Layout-to-Image (L2I), and Semantics-based Scene Graph-to-Image (SG2I) methods. It highlights common issues like misinterpretations of relationships and quantities (T2I), difficulty handling non-spatial interactions (L2I), and missing objects or attributes (SG2I). In contrast, the authors’ method (DisCo) is shown to achieve greater accuracy and controllability, as evidenced by the example of consistent attribute control in (d).

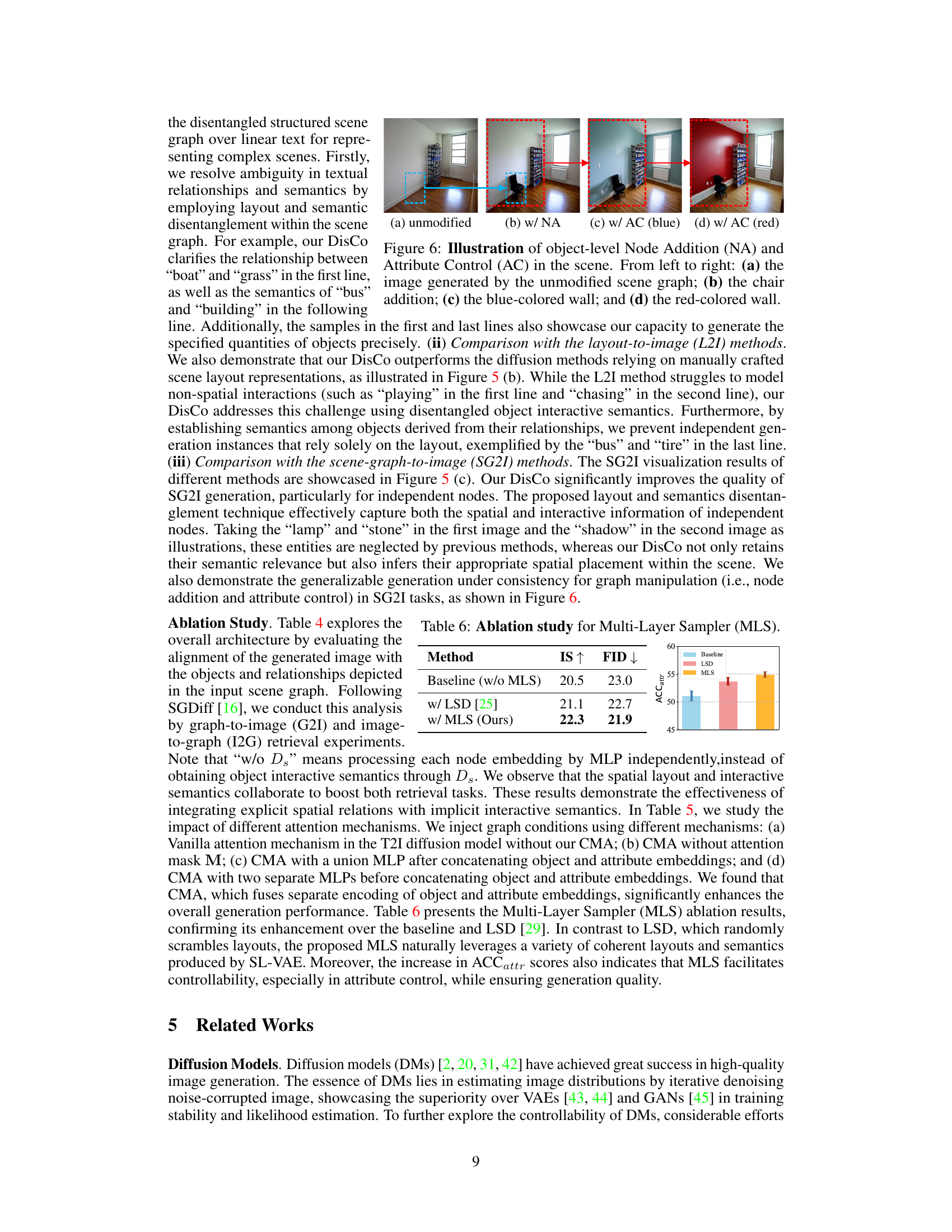
This figure demonstrates the model’s ability to perform object-level manipulation, specifically node addition and attribute control. The image shows a scene of a room. (a) is the unmodified scene. (b) shows the addition of a chair (node addition). (c) and (d) show changes in the wall color (attribute control). The dashed boxes highlight the changes made via graph manipulation.

This figure demonstrates the model’s ability to perform object-level manipulation. The image shows how the model can add new objects (node addition) or change attributes of existing objects (attribute control) while maintaining consistency in the scene. The four images showcase the effects of using an unmodified scene graph versus scene graphs modified to include a new chair, blue wall, and red wall, respectively.

This figure visualizes the results of applying graph manipulation (node addition and attribute control) to the scene graph. It demonstrates the model’s ability to generate images consistent with the manipulated graph, showing added objects and changed attributes while maintaining scene coherence. Multiple examples are given for various scene types (ocean, room, house).

This figure showcases the failure cases of existing state-of-the-art methods in generating complex images from text, layout, or scene graph. (a) shows DALL-E 3 struggling with relationships and object counts from a complex text prompt. (b) shows LayoutDiffusion’s limitations in handling non-spatial relationships (e.g., ‘playing’). (c) demonstrates the issues of R3CD with independent node generation in scene graphs. Finally, (d) highlights the improved results of the proposed DisCo method, demonstrating its ability to maintain visual consistency while manipulating the scene graph (adding and changing attributes).

This figure compares the image generation results of four different methods: GLIGEN, LayoutDiffusion, MIGC, and the authors’ proposed method (Ours). Each row shows a different text prompt used to generate the images. The figure highlights the differences in the generated images’ adherence to the specified spatial relationships and object attributes, demonstrating the strengths and weaknesses of each method.

This figure presents a qualitative comparison of the proposed DisCo model against other state-of-the-art Scene-Graph-to-Image (SG2I) methods, including SGDiff, R3CD, SG2Im, and SceneGenie. For each method, three example scenes are shown, along with their corresponding scene graphs. The scene graphs represent the objects and relationships in each scene. The generated images demonstrate the ability of each model to produce images consistent with the scene graph. The differences highlight the advantages of DisCo, particularly its ability to handle complex relationships and object interactions. The superior visual quality and coherence achieved by DisCo compared to the other methods are easily discernible. Notice how DisCo better handles objects that might otherwise be missed or misplaced in other methods.
More on tables

This table presents a comparison of the proposed DisCo model against several state-of-the-art text-to-image methods on the T2I-CompBench benchmark. The benchmark evaluates the models’ ability to generate images based on compositional prompts. The table shows the performance of each method across four metrics: UniDet, CLIP, B-VQA, and 3-in-1, which assess the generation of spatial/non-spatial relationships, attributes, and complex scenes.

This table presents the results of a user study conducted to evaluate the alignment between image prompts and generated images. Fifty participants scored the alignment of prompts and images from different methods on a scale of 1-5. The average scores are presented here, indicating DisCo’s superior performance in generating images that align well with the given prompts.
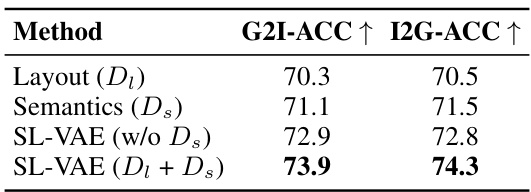
This table presents the results of ablation studies conducted to analyze the impact of different components on the overall performance and attention mechanism. Table 4 shows the ablation results for the overall architecture of the model, specifically focusing on the role of the layout decoder (D_l), semantic decoder (D_s), and their combination in the SL-VAE. It also includes a comparison using SL-VAE without the semantic decoder (D_s). The metrics used for evaluation are G2I-ACC and I2G-ACC. Table 5 presents ablation results for different attention mechanisms, including vanilla attention, CMA without the mask (M), CMA with a union Multilayer Perceptron (MLP), and CMA with separate MLPs. The evaluation metrics used here are IS and FID.
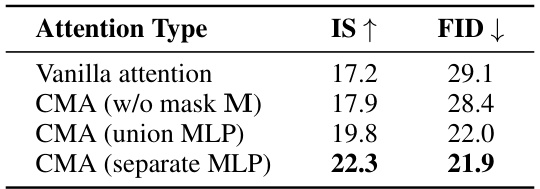
This table presents the ablation study for different attention mechanisms used in the proposed model. It compares the performance of using the vanilla attention mechanism from a standard text-to-image diffusion model against the proposed Compositional Masked Attention (CMA) mechanism with and without different variations of the masking and Multi-Layer Perceptron (MLP) structures. The results are evaluated using the Inception Score (IS) and Fréchet Inception Distance (FID) metrics. The table shows that the CMA with separate MLPs significantly improves the performance compared to the other methods.
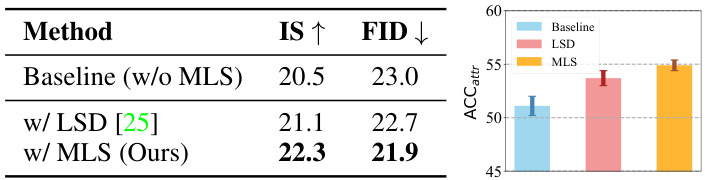
This ablation study compares the performance of three different methods for generating images using scene graphs: a baseline method, a method using Layered Scene Diffusion (LSD), and the proposed Multi-Layered Sampler (MLS) method. The table shows the Inception Score (IS), Fréchet Inception Distance (FID), and Attribute Classification Accuracy (ACCattr) for each method. The results demonstrate the improved performance of the proposed MLS method compared to the baseline and LSD methods, particularly in terms of attribute control.

This table presents the ablation study on the impact of different components in the graph construction process. It shows the Inception Score (IS) and Fréchet Inception Distance (FID) metrics when excluding CLIP embeddings, bounding box embeddings, and learnable embeddings from the graph. The results indicate that all components contribute to performance gains.

This table compares the performance of various image generation methods on two benchmark datasets (COCO-Stuff and Visual Genome). The methods are categorized by their underlying architecture (GAN-based or Diffusion-based) and the type of input condition (layout or semantics). The DisCo method, proposed by the authors, uses both layout and semantic information. Performance is evaluated using Inception Score (IS) and Fréchet Inception Distance (FID), with higher IS and lower FID indicating better image quality and diversity.
Full paper#