↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Visual representation learning, crucial in computer vision, faces challenges with existing CNNs and ViTs due to their high computational costs. Vision Transformers, despite superior learning capabilities, suffer from self-attention’s quadratic complexity, hindering their application in high-resolution images. This necessitates efficient network architectures, hence this research.
VMamba uses a stack of Visual State Space (VSS) blocks containing a novel 2D Selective Scan (SS2D) module. SS2D enhances the collection of contextual information compared to traditional methods. Extensive experiments on ImageNet and other datasets show VMamba outperforms existing benchmarks in accuracy and computational efficiency, particularly with larger inputs. This highlights VMamba’s superior input scaling efficiency and potential for future efficient vision models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision due to its introduction of VMamba, a novel vision backbone with linear time complexity, significantly improving efficiency in processing high-resolution images. Its 2D Selective Scan method is a significant advancement, offering a new approach to visual representation learning and paving the way for more scalable and efficient vision models. The superior input scaling efficiency demonstrated by VMamba across diverse tasks will prompt researchers to explore and adapt its architecture for various applications.
Visual Insights#

The figure compares self-attention and the proposed 2D-Selective-Scan (SS2D) mechanisms for establishing correlations between image patches. In (a), self-attention shows the query patch (red box) interacting with all other patches, indicated by the many yellow lines. Opacity of patches represents information loss. In (b), SS2D shows how the query patch interacts with patches only along four specific scanning paths, shown by the colored lines. The compressed hidden state computed along each path is used to acquire contextual knowledge. This method is less computationally expensive than self-attention, showing its linear time complexity.
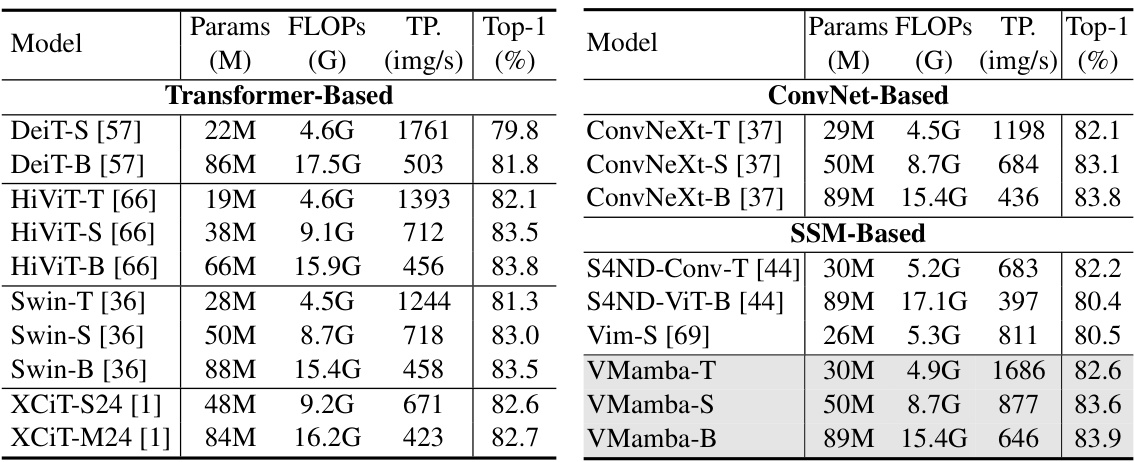
This table compares the performance of various vision models, including VMamba, on the ImageNet-1K image classification benchmark. Metrics include the number of model parameters (Params), floating point operations (FLOPs), throughput (TP, images per second), and top-1 accuracy. The table highlights VMamba’s competitive performance and efficiency compared to other state-of-the-art models.
In-depth insights#
Visual SSMs#
Visual State Space Models (SSMs) represent a novel approach to visual representation learning, offering a compelling alternative to traditional CNNs and ViTs. Their inherent linear time complexity is particularly attractive for handling high-resolution images, a significant challenge for quadratic-complexity methods like self-attention. While SSMs have shown promise in NLP, their application to the spatial domain of visual data requires careful consideration. The core challenge lies in bridging the ordered nature of sequential data processing inherent in SSMs with the non-sequential structure of 2D image data. Innovative scanning mechanisms, such as 2D Selective Scan (SS2D), are crucial to effectively capturing contextual information in visual data using SSMs. Careful design of the scanning paths is necessary to allow the collection of relevant contextual information from multiple perspectives. By addressing the computational and representational challenges inherent in applying SSMs to visual data, Visual SSMs open up exciting new avenues for creating efficient and scalable vision architectures with potentially superior performance in downstream tasks.
SS2D Scan#
The conceptualization of a 2D Selective Scan (SS2D) presents a significant advancement in visual representation learning. SS2D directly addresses the limitations of applying 1D selective scan mechanisms, inherent in previous State-Space Models (SSMs), to 2D image data. Unlike the sequential nature of text, images lack inherent order. SS2D ingeniously overcomes this by employing four distinct scanning routes (cross-scan) across the image, enabling each patch to capture contextual information from diverse perspectives. The subsequent processing of these independent scan sequences (using S6 blocks) and merging of the results (cross-merge) creates rich 2D feature maps with enhanced contextual understanding. This approach not only preserves the linear time complexity of SSMs but also enhances global receptive field properties in the 2D space, leading to improved performance across various visual perception tasks. The efficacy of SS2D rests in its ability to efficiently capture long-range dependencies in a linear time framework, thereby representing a substantial step towards more efficient and effective visual backbone architectures.
VMamba Speed#
The VMamba architecture prioritizes speed through several key design choices. Linear time complexity is achieved by replacing the quadratic self-attention mechanism of traditional vision transformers with a linear-time state-space model and a novel 2D Selective Scan (SS2D) module. SS2D efficiently gathers contextual information by traversing the image data along four scanning paths, eliminating the need for exhaustive pairwise comparisons. Furthermore, architectural enhancements and implementation optimizations, such as using the Triton language for GPU acceleration and replacing einsum operations with more efficient linear transformations, further contribute to VMamba’s speed. Input scalability is another advantage; VMamba exhibits linear growth in FLOPs with increasing input resolution, unlike ViTs that experience quadratic growth. These combined strategies result in significant speedups compared to benchmark models, highlighting VMamba’s potential for real-time vision applications.
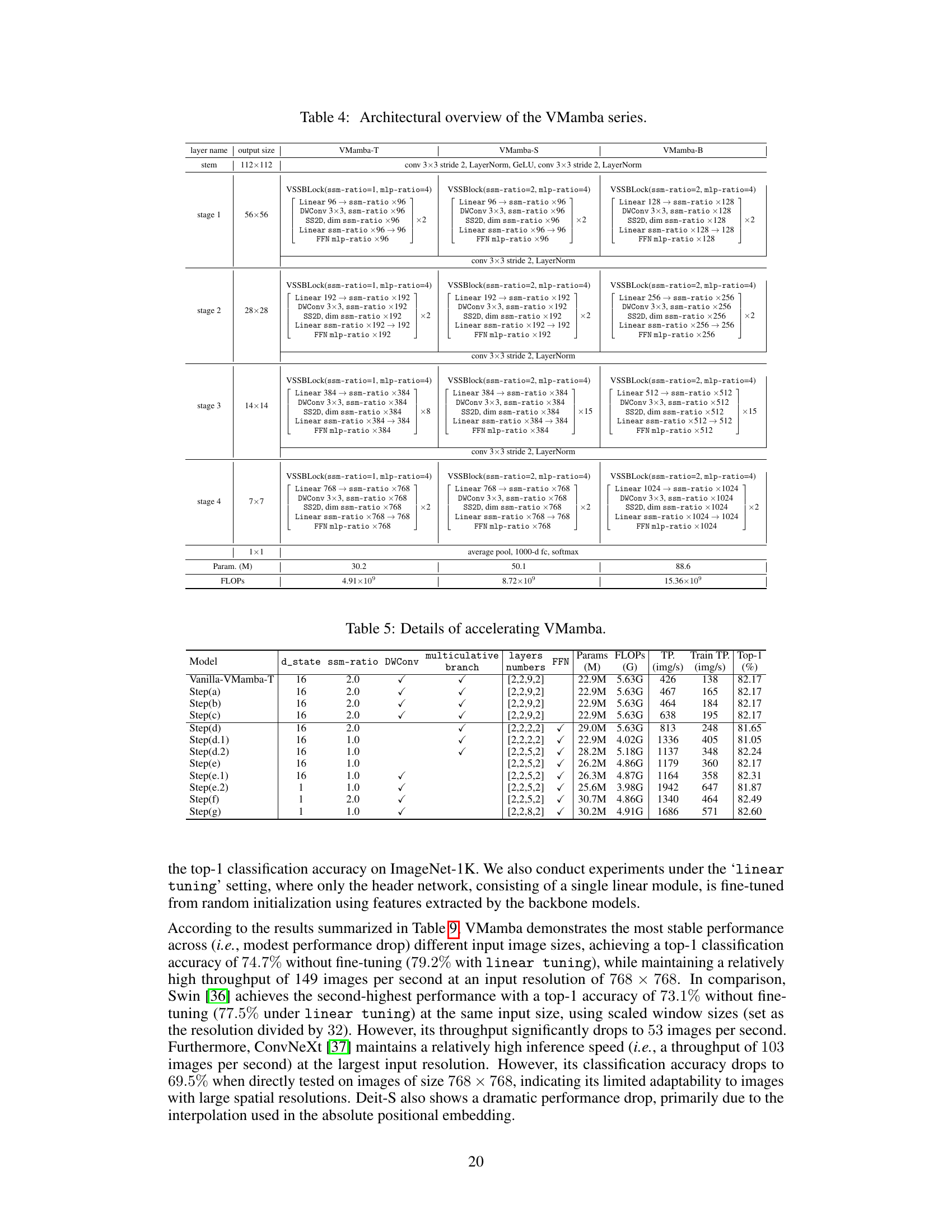
Ablation Study#
An ablation study systematically removes components of a model to determine their individual contributions. In the context of a vision model, this might involve progressively disabling or altering elements like attention mechanisms, specific scanning patterns, activation functions, or various architectural components (e.g., residual blocks, downsampling layers). By observing the impact on performance metrics (accuracy, throughput, FLOPs), researchers can pinpoint critical design elements. A well-designed ablation study isolates effects, clearly illustrating which architectural choices are most impactful and essential for the model’s success. The results of such a study guide future development, helping to refine architectures by prioritizing key components while identifying and potentially discarding less important or redundant features. Thorough ablation studies are crucial for demonstrating model robustness and providing valuable insights into model design principles. Furthermore, they help determine whether the improved performance stems from a novel aspect of the model or from simply using a more sophisticated or advanced baseline.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Extending VMamba’s capabilities to handle even longer input sequences with maintained linear complexity is crucial for applications involving high-resolution imagery or extended temporal contexts. Investigating the effectiveness of various pre-training techniques specifically designed for SSM-based architectures like VMamba would significantly enhance the model’s learning capacity and generalization performance. A comprehensive hyperparameter search, beyond the scope of this initial study, could optimize VMamba’s architecture for various visual tasks and scales. Furthermore, exploring alternative scanning mechanisms that surpass SS2D’s efficiency for specific tasks or data modalities is a worthwhile endeavor. Finally, integrating VMamba with other state-of-the-art techniques such as advanced attention mechanisms or different model architectures could further improve its performance on complex visual tasks.
More visual insights#
More on figures

The figure illustrates the 2D-Selective-Scan (SS2D) mechanism. Input image patches are scanned in four directions (Cross-Scan). Each scan produces a sequence which is then processed by independent S6 blocks. The results from the four S6 blocks are then merged (Cross-Merge) to create a final 2D feature map. This approach contrasts with self-attention, which uses a computationally expensive process involving all patches.
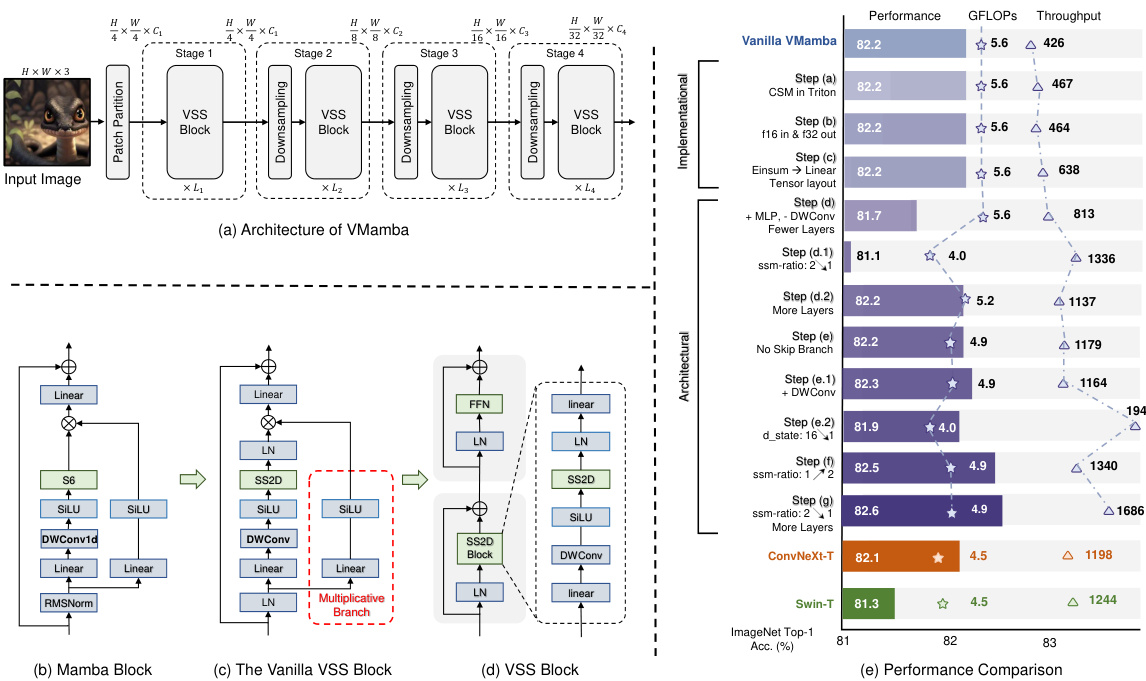
This figure shows the architecture of VMamba, comparing it to Mamba and VSS blocks. The left side illustrates the overall architecture (a) and the structure of the blocks (b-d). The right side provides a performance comparison table showing ImageNet Top-1 accuracy, GFLOPs, and throughput for different VMamba variants and benchmark models (ConvNeXt-T, Swin-T). It highlights the improvements achieved through a series of architectural and implementation enhancements.
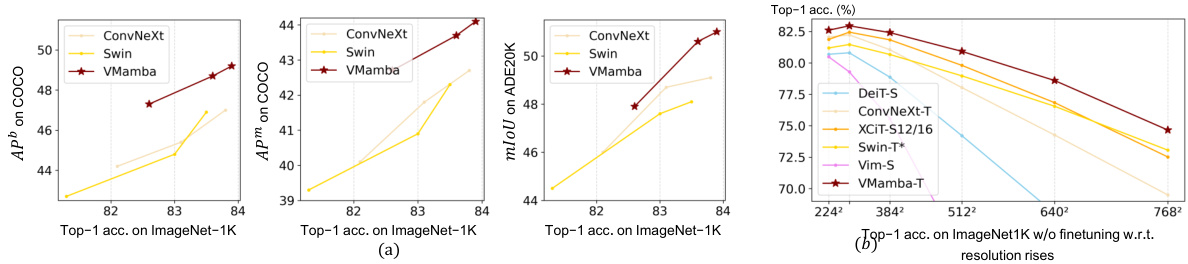
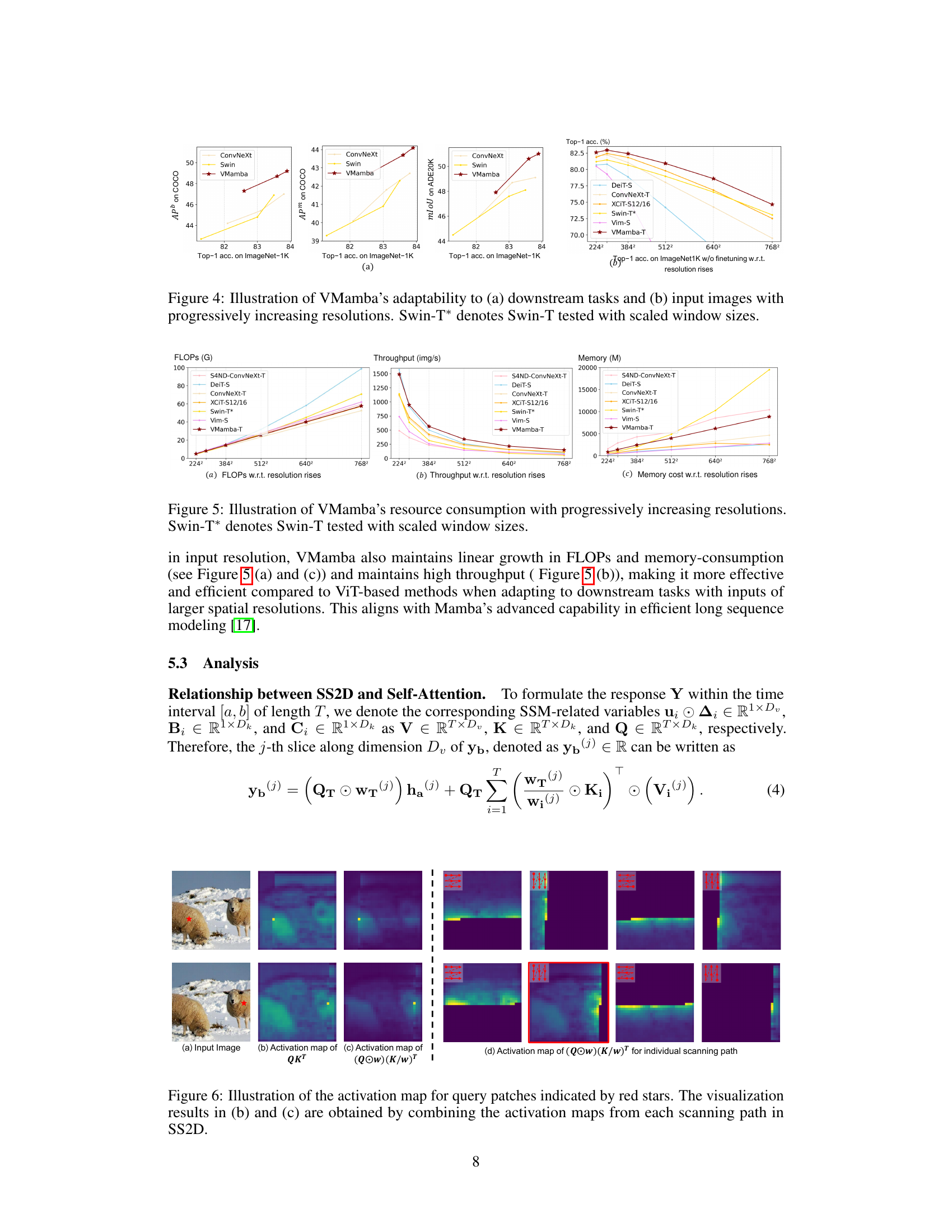
This figure demonstrates VMamba’s performance and scalability across various tasks and input resolutions. Subfigure (a) shows that VMamba outperforms other models (ConvNeXt and Swin) on object detection (APb and APm on COCO), and semantic segmentation (mIoU on ADE20K), maintaining its advantage with an increase in ImageNet-1K classification accuracy. Subfigure (b) highlights VMamba’s superior input scaling efficiency by showing a much smaller performance drop than other models (DeiT-S, ConvNeXt-T, XCIT-S12/16, Swin-T*, Vim-S) as the input resolution increases from 224x224 to 768x768, even without fine-tuning.

This figure presents a comparison of FLOPs, throughput, and memory consumption for different vision backbones (VMamba-T, Swin-T*, XCIT-S12/16, DeiT-S, ConvNeXt-T, Vim-S, and S4ND-ConvNeXt-T) across various input image resolutions (224x224, 384x384, 512x512, 640x640, and 768x768). It demonstrates VMamba-T’s linear scaling behavior in terms of FLOPs and memory usage while maintaining relatively high throughput compared to other models, particularly as resolution increases. The performance of Swin-T* is shown with scaled window sizes for a more relevant comparison.
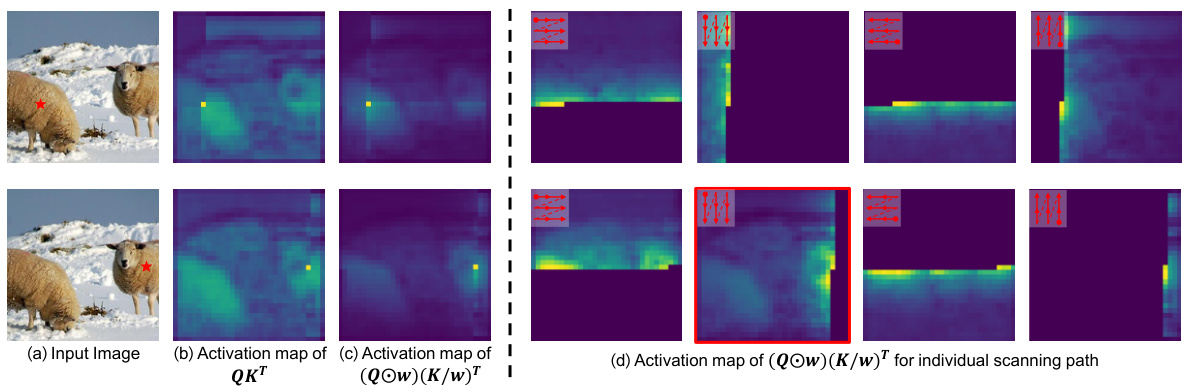
The figure shows the activation maps for query patches. (a) shows the input image with query patches marked by red stars. (b) displays the activation map generated using the standard self-attention mechanism (QKT), showcasing the activation of all previously scanned foreground tokens. (c) illustrates the activation map generated by the proposed SS2D mechanism ((Qω)(K/ω)ᵀ), demonstrating a more focused activation on the neighborhood of the query patches. (d) shows the activation maps for each scanning path, highlighting how SS2D accumulates information during traversal.
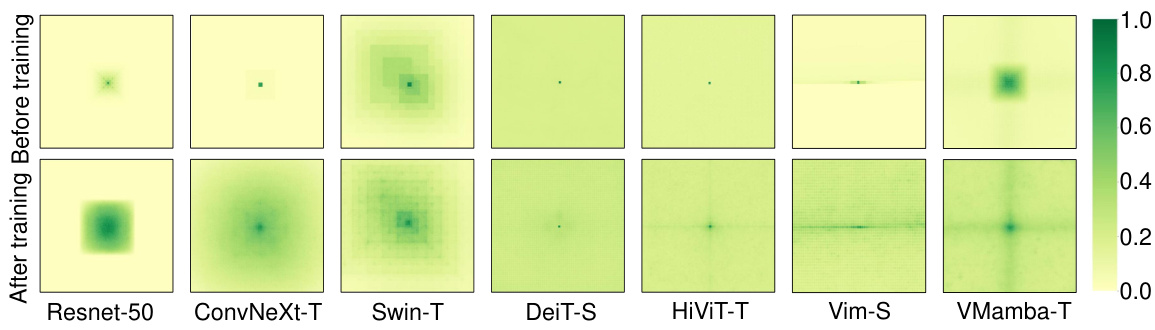
This figure compares the effective receptive fields (ERF) of VMamba and several other benchmark models (ResNet-50, ConvNeXt-T, Swin-T, DeiT-S, HiViT-T, Vim-S) before and after training. The ERF shows the region of the input image that influences the activation of a specific output unit. The heatmaps show that VMamba, along with DeiT, HiViT and Vim, demonstrates global receptive fields. This means that the activation is influenced by the entire input image. ResNet, ConvNeXt, and Swin show local receptive fields, with activation primarily centered around the central pixel. VMamba’s global receptive field indicates its ability to capture long-range dependencies in image data.
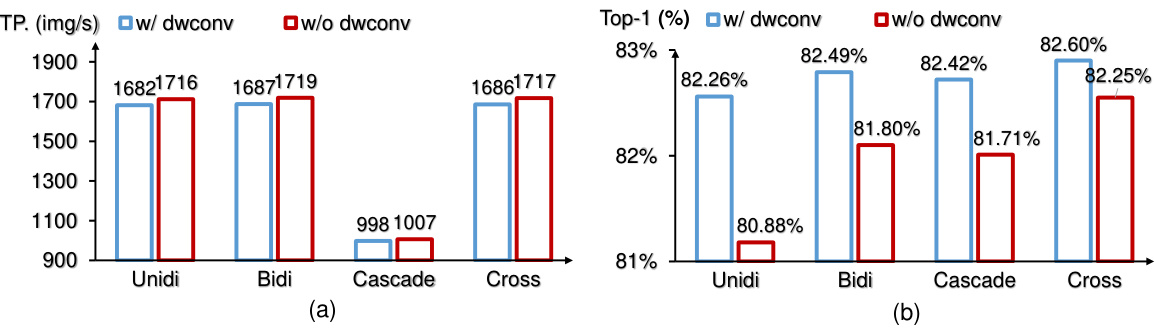
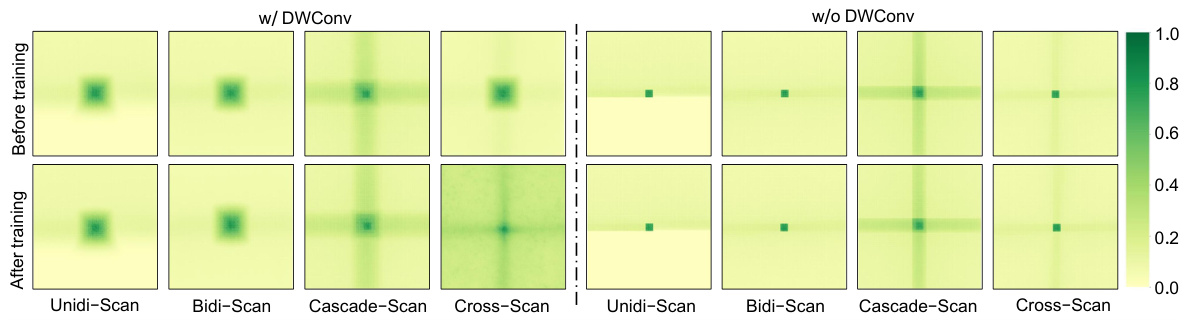
This figure compares the performance of four different scanning patterns for the 2D-Selective-Scan (SS2D) module within the VMamba architecture. The patterns are Unidi-Scan, Bidi-Scan, Cascade-Scan, and Cross-Scan. The graph shows that Cross-Scan offers the highest throughput (images/s), both with and without depthwise convolutions (DWConv), while maintaining similar performance (Top-1 accuracy) to other methods. This highlights Cross-Scan’s effectiveness in capturing 2D contextual information efficiently.

This figure visualizes the attention maps generated by the 2D-Selective-Scan (SS2D) module. It shows the attention maps from four different scanning routes (Cross-Scan) within the SS2D. The top row displays the attention maps using the QKT calculation, illustrating the relationship between the current patch and all previously scanned patches. The bottom row presents attention maps using (Q⊙w)(K/w)T, showcasing a more focused attention around the neighborhood of the query patches. The visualizations demonstrate how SS2D captures and retains information from all previously scanned tokens, especially those in the foreground.

This figure compares self-attention and the proposed 2D Selective Scan (SS2D) mechanisms for establishing correlations between image patches. The left panel (a) shows that self-attention computes correlations between all image patches, while the right panel (b) illustrates that SS2D computes correlations only along its scanning paths. The opacity of the red boxes indicates how much information is lost with each method.

This figure compares how self-attention and the proposed 2D-Selective-Scan (SS2D) method establish correlations between image patches. The opacity of the red boxes, which represent the query patch, illustrates the degree of information loss in each method. Self-attention considers all patches simultaneously, while SS2D traverses patches along specific paths, capturing context in a computationally efficient manner.
This figure compares the effective receptive fields (ERFs) of VMamba and other benchmark models (ResNet-50, ConvNeXt-T, Swin-T, DeiT-S, HiViT-T, and Vim-S) before and after training. The ERF is a measure of the region in the input image that influences the activation of a specific output unit. Higher intensity pixels in the heatmaps indicate stronger responses from the central pixel, which is representative of the region’s influence on activation. The figure shows that VMamba and some other models (DeiT, HiViT, and Vim) achieve global ERFs after training, meaning that the receptive field spans a significant part of the image. In contrast, other models, such as ResNet and ConvNeXt-T, largely maintain local receptive fields even after training. VMamba’s global ERF indicates its capacity to capture long-range contextual information.

This figure visualizes the Effective Receptive Fields (ERF) of VMamba before and after training, comparing three different initialization methods: Mamba-Init, Rand-Init, and Zero-Init. The ERFs are represented as heatmaps, showing the intensity of response for the central pixel in relation to the surrounding pixels. The comparison allows for an assessment of how the different initialization strategies impact the receptive field of the model, indicating the influence of initialization on the model’s ability to capture global contextual information.
More on tables
This table compares the performance of various vision models (Transformer-based, ConvNet-based, and SSM-based) on the ImageNet-1K image classification benchmark. Metrics include model parameters, FLOPs (floating point operations), throughput (images per second), and Top-1 accuracy. The table highlights VMamba’s performance relative to existing state-of-the-art models.
This table compares the performance of VMamba against other state-of-the-art models on the ImageNet-1K dataset for image classification. Metrics include the number of parameters (Params), GFLOPs (floating point operations), throughput (TP) in images per second, and top-1 accuracy. It highlights VMamba’s superior performance and throughput compared to models based on Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and other State Space Models (SSMs).
This table compares the performance of VMamba against various other transformer-based, convolutional neural network-based, and SSM-based models on the ImageNet-1K dataset. The metrics used are the number of parameters (in millions), GigaFLOPs (GFLOPs), throughput (images per second), and Top-1 accuracy (%). It highlights VMamba’s superior performance and efficiency relative to its competitors.

This table compares the performance of VMamba against other state-of-the-art models on the ImageNet-1K dataset. Metrics include the number of parameters (Params), GigaFLOPS (FLOPS), throughput (TP) in images per second, and Top-1 accuracy. The table is organized to compare VMamba against other Transformer-based models, ConvNet-based models, and other SSM-based models.

This table compares the performance of VMamba against various other state-of-the-art vision models on the ImageNet-1K image classification benchmark. Metrics include the number of parameters (Params), GigaFLOPs (FLOPs), throughput (TP, images/second), and top-1 accuracy. It highlights VMamba’s superior performance and efficiency compared to Transformer-based and Convolutional Neural Network-based models.
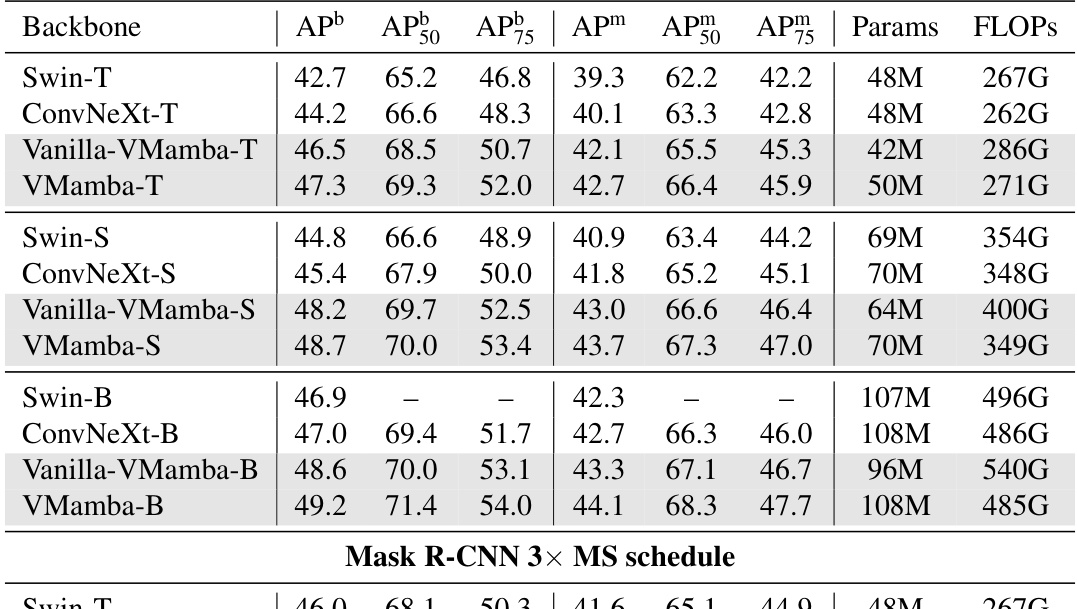
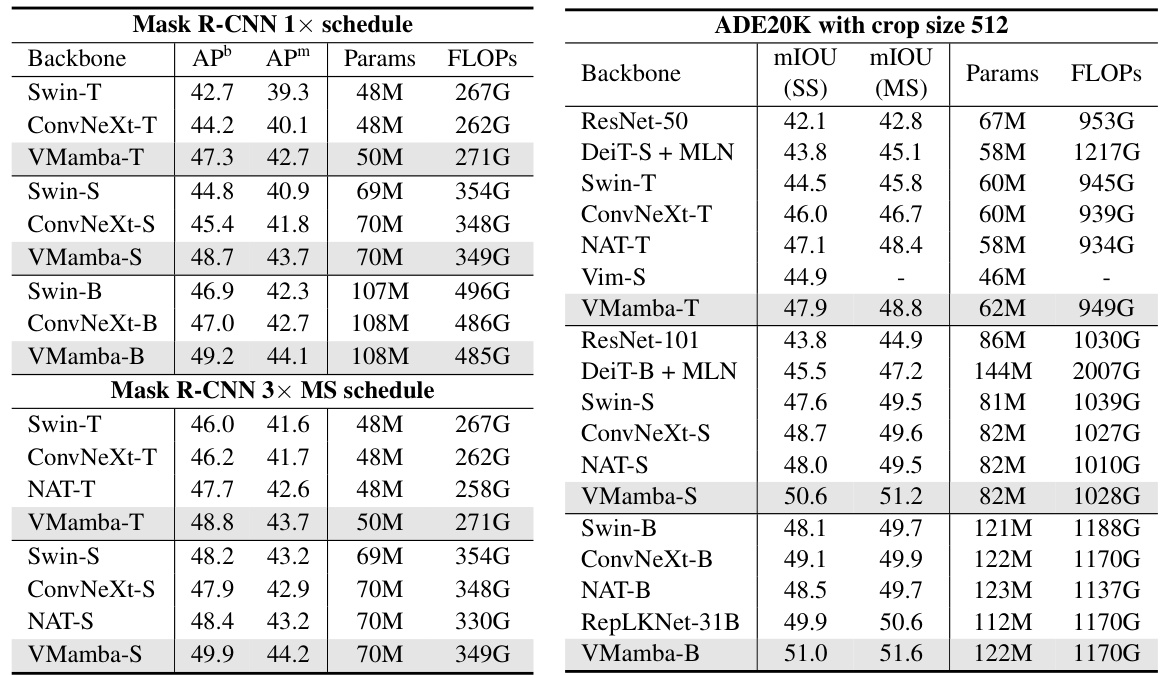
This table presents a comparison of object detection and instance segmentation performance on the MS COCO dataset for different model architectures. It shows the average precision (AP) metrics, including box AP (APb) and mask AP (APm), for different models with varying parameter counts and FLOPs. The results are reported for both a 12-epoch fine-tuning schedule and a 36-epoch multi-scale training schedule.
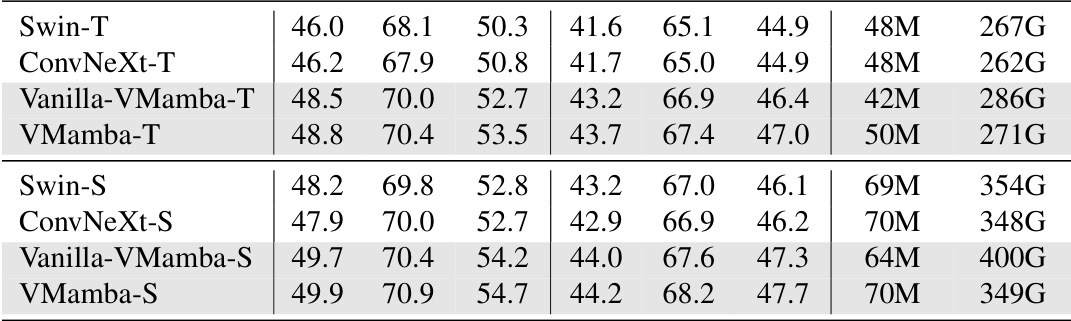
This table presents a comparison of the performance of various models on object detection and instance segmentation tasks using the COCO dataset. It shows the average precision (AP) for both bounding boxes (APb) and masks (APm) at different intersection over union (IoU) thresholds. The models are trained using both a 12-epoch schedule and a 36-epoch multi-scale training schedule. The table also includes the model parameters (Params) and floating point operations (FLOPs).
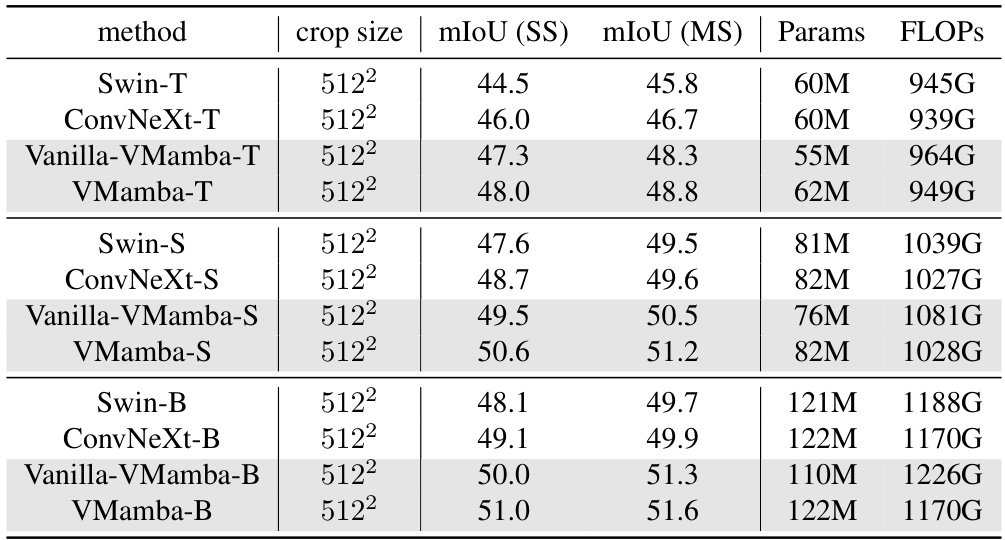
This table presents a comparison of semantic segmentation performance on the ADE20K dataset using different models. It shows the mean Intersection over Union (mIoU) for both single-scale and multi-scale testing, along with model parameters and FLOPs. The models compared include Swin Transformer, ConvNeXt, and various versions of VMamba.

This table compares the performance of VMamba against other state-of-the-art vision models on the ImageNet-1K dataset. Metrics include the number of parameters (Params), GigaFLOPs (FLOPs), throughput (TP), and Top-1 accuracy. The table highlights VMamba’s superior performance and efficiency across different model sizes (Tiny, Small, Base).

This table compares the performance of VMamba-T using four different scanning patterns: Unidi-Scan, Bidi-Scan, Cascade-Scan, and Cross-Scan. The comparison includes parameters (M), FLOPS (G), throughput (TP. img/s), training throughput (Train TP. img/s), and Top-1 accuracy (%). It shows the impact of the scanning pattern on various performance metrics, with and without depthwise convolutions (dwconv).

This table compares the performance of VMamba with other state-of-the-art models on the ImageNet-1K image classification benchmark. The metrics reported include the number of parameters (Params), GigaFLOPS (FLOPs), throughput (TP) in images per second, and the Top-1 accuracy. It shows VMamba’s performance advantage in accuracy and throughput, especially when considering the computational efficiency.
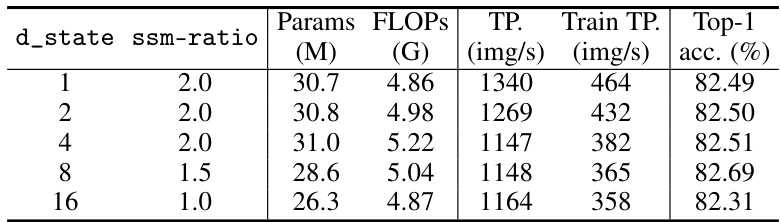
This table compares the performance of VMamba with other state-of-the-art models on the ImageNet-1K dataset using images of size 224x224. Metrics include the number of parameters (Params), GigaFLOPs (FLOPs), throughput (TP, images/s), training throughput (Train TP, images/s), and top-1 accuracy. The table highlights VMamba’s competitive performance and efficiency compared to other transformer and convolutional neural network based models. Note that the Vim model’s training throughput is obtained from a different source due to the practical use of float32 during its training phase.
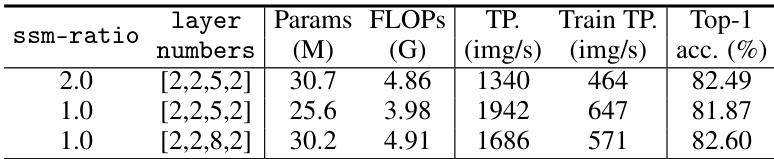
This table compares the performance of various vision models, including VMamba, on ImageNet-1K. Metrics include the number of parameters, GFLOPs, throughput (images per second), and top-1 accuracy. It highlights VMamba’s performance relative to other state-of-the-art models, showcasing its efficiency and accuracy.
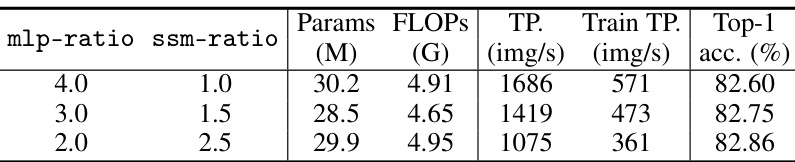
This table compares the performance of various vision models on the ImageNet-1K image classification benchmark. The metrics include the number of model parameters (Params), the number of floating point operations (FLOPs), the throughput (TP, images per second), and the top-1 accuracy. The models are categorized into Transformer-based, ConvNet-based, and SSM-based models, allowing for comparison across different architectural approaches.

This table compares the performance of VMamba with other state-of-the-art vision models on the ImageNet-1K dataset. The models are evaluated based on parameters, FLOPs, throughput (images/second), training throughput, and top-1 accuracy. The table highlights VMamba’s efficiency and competitive performance compared to other Transformer-based, ConvNet-based, and SSM-based models.
Full paper#