↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Many existing anomaly detection models struggle with class-generalizability, meaning their performance significantly drops when applied to new, unseen classes. This is because the standard one-for-one or one-for-many models learn features specific to the classes they are trained on, making them ineffective for novel data. This issue is particularly crucial in scenarios with limited data, or when retraining is impossible.
ResAD, introduced in this paper, cleverly bypasses this limitation. Instead of directly learning the original feature distributions, it focuses on residual features, which represent the differences between input features and their nearest normal counterparts. This clever design drastically reduces feature variations across different classes, allowing the model to generalize effectively to new classes even with limited training data. ResAD achieves superior results compared to existing methods, showcasing its efficiency and efficacy in addressing the class-generalizability challenge.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on anomaly detection due to its novel approach to class-generalizable anomaly detection. It directly addresses the limitations of existing methods by focusing on residual feature learning and offers a simpler, more effective framework. This opens exciting new research avenues for improving generalizability and robustness in anomaly detection systems, impacting various applications.
Visual Insights#

This figure provides an intuitive illustration of class-generalizable anomaly detection and its core concept, residual feature learning. Panel (a) shows how a unified model, trained on multiple known classes, can generalize to detect anomalies in unseen classes without retraining. Panel (b) highlights the advantage of using residual features (differences between input features and reference normal features). Residual features exhibit less variation across different classes, enabling the model to more effectively distinguish anomalies from normal instances in new, unseen classes.
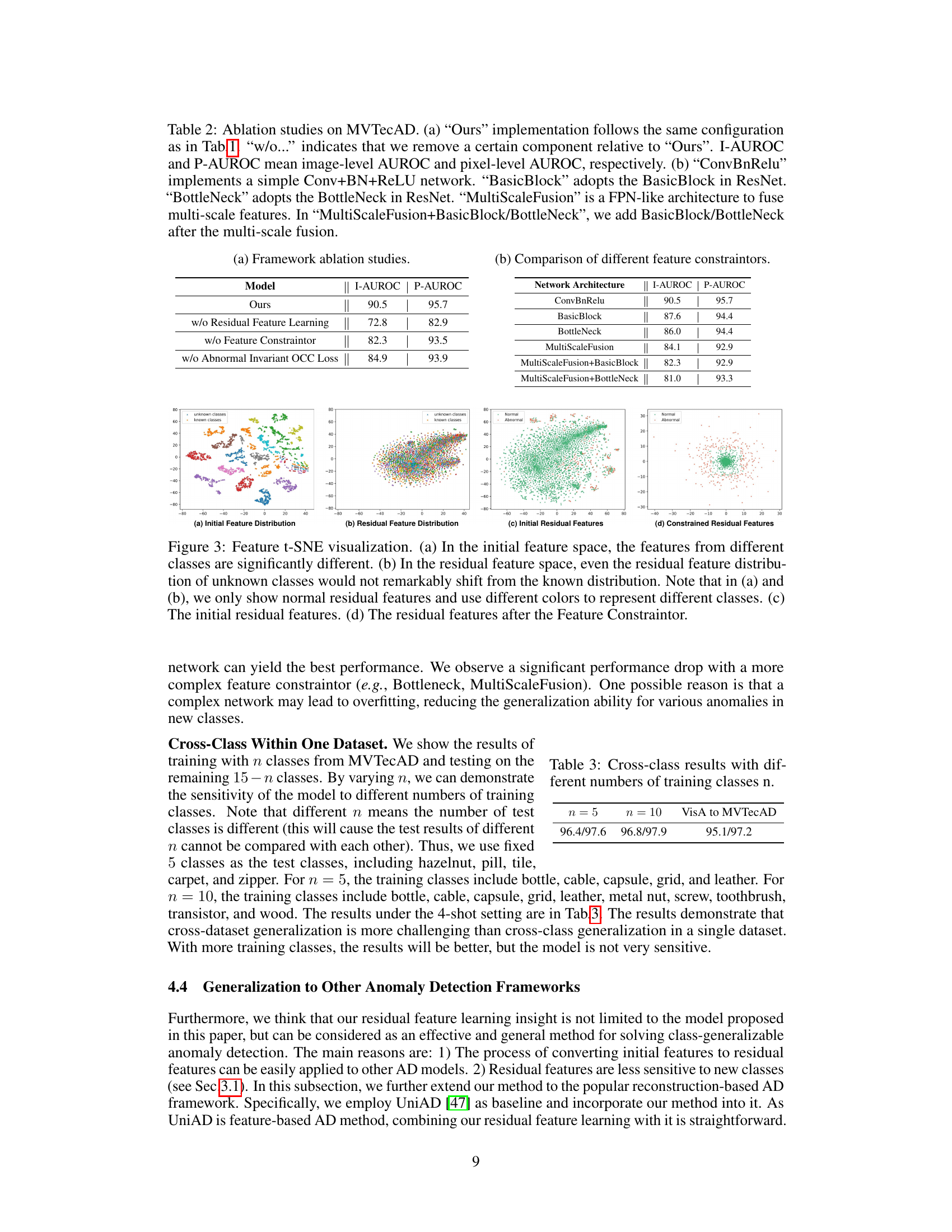
This table presents the performance comparison of ResAD against several state-of-the-art anomaly detection methods on six real-world datasets (four industrial and two medical/video) using two different few-shot settings (2-shot and 4-shot). The results are presented in terms of Area Under the Receiver Operating Characteristic Curve (AUROC) for both image-level and pixel-level anomaly detection. It highlights ResAD’s ability to generalize across different datasets and its superiority over other methods, even without fine-tuning. Note that the pixel-level AUROCs for InCTRL are missing because the method does not provide this information.
In-depth insights#
ResAD Framework#
The ResAD framework offers a novel approach to class-generalizable anomaly detection by focusing on residual feature learning. Instead of directly modeling the initial feature distributions, which vary significantly across classes, ResAD learns the distribution of residual features obtained by subtracting matched normal reference features from input features. This clever strategy effectively reduces feature variations, enabling the model to generalize well to unseen classes with minimal retraining. The framework’s simplicity is a strength, incorporating a Feature Converter, a Feature Constraintor (using an OCC loss to constrain features into a hypersphere), and a Feature Distribution Estimator. This design reduces feature variations and maintains consistency in feature scales across classes, enhancing performance on new, unseen data. The effectiveness is demonstrated by its strong performance on multiple real-world datasets, even with limited reference samples, highlighting its potential for practical application in various anomaly detection domains.
Residual Feature#
The concept of “Residual Feature” in anomaly detection focuses on learning the difference between an input feature and its nearest normal counterpart. This approach is powerful because it mitigates the impact of class-specific variations in the initial feature space. By focusing on the residual, the model learns features that are more invariant across different classes, thereby improving generalization. This is particularly useful in class-generalizable anomaly detection, where the goal is to train a single model effective on unseen classes without retraining. The effectiveness hinges on the assumption that anomalies will have larger residuals than normal instances, irrespective of the class. The framework, therefore, leverages the inherent consistency in residual feature distributions to detect anomalies, even in novel classes. A key strength of this approach is its simplicity and effectiveness, and it presents a valuable alternative to traditional methods that struggle with class variability.
Few-Shot Learning#
Few-shot learning, a subfield of machine learning, addresses the challenge of training accurate models with limited data. This is particularly relevant in scenarios where obtaining large, labeled datasets is expensive or impossible. The core idea is to enable models to generalize well to new tasks or classes after being trained on only a few examples. ResAD leverages this principle by using a small number of reference images from novel classes for anomaly detection, rather than requiring extensive retraining. This addresses a crucial limitation of traditional anomaly detection methods, which often struggle to generalize to unseen classes. The effectiveness of ResAD showcases the potential of few-shot learning to improve the efficiency and applicability of anomaly detection systems in real-world applications where data is scarce and classes are diverse. The approach’s strength lies in its ability to minimize the need for extensive retraining, making it practical for dynamic environments with continuously emerging classes. This focus on efficiency and generalizability through few-shot learning makes ResAD a significant step towards more robust and practical anomaly detection models.
Cross-dataset Results#
Cross-dataset generalization is a crucial test for anomaly detection models, evaluating their ability to adapt to unseen data distributions. A successful model should perform well across diverse datasets without retraining. The ‘Cross-dataset Results’ section would ideally present a comprehensive evaluation on multiple distinct datasets, showing consistent, high performance. This could involve metrics like AUROC (Area Under the Receiver Operating Characteristic Curve) and precision-recall curves, calculated for each dataset individually and also averaged across them. Significant performance differences across datasets would indicate limitations in generalization, suggesting potential biases in the model or the need for dataset-specific fine-tuning. The analysis should not merely report numbers, but provide a detailed discussion explaining the reasons behind the observed performance variations. Factors like the visual characteristics of datasets (e.g., texture vs. object-based anomalies) and differences in image quality or resolution could significantly impact results and should be explored. Ultimately, a thorough ‘Cross-dataset Results’ section would show whether the model truly generalizes beyond its training data, demonstrating robust and reliable performance in real-world scenarios.
Future Works#
The paper’s ‘Future Works’ section would ideally delve into several key areas. Expanding the method’s applicability to various data modalities beyond images is crucial, exploring its effectiveness on video data, time series, and other complex data types. A thorough investigation into the method’s robustness to different levels of noise and data scarcity would strengthen the findings. Addressing limitations in generalization across diverse datasets by systematically evaluating performance on a wider range of benchmark datasets would be highly beneficial. The inherent simplicity of ResAD, a strength, could be further leveraged by exploring efficient implementation techniques for resource-constrained environments. Finally, a deeper theoretical analysis to explain the method’s effectiveness and limitations would greatly enhance its value and contribution to the field of anomaly detection.
More visual insights#
More on figures

This figure illustrates the ResAD framework’s architecture. It shows the process of how a test image is processed to detect anomalies. First, a pre-trained feature extractor is used to obtain initial features from both the test image and few-shot normal reference images. These initial features are then converted into residual features by subtracting the nearest normal reference feature for each. Next, a Feature Constraintor shapes the normal residual features into a hypersphere. Finally, a Feature Distribution Estimator, using a normalizing flow model, learns the normal residual feature distribution, enabling the detection of anomalies (outliers) in the test image. The loss functions used in training are also indicated.

This figure illustrates the core idea of the ResAD framework. (a) shows how a class-generalizable anomaly detection model, trained on several known classes, can generalize to detect anomalies in unseen classes. (b) demonstrates that learning residual features (the difference between an input feature and its nearest neighbor from known classes) reduces feature variations across classes, allowing for better anomaly detection in new classes.

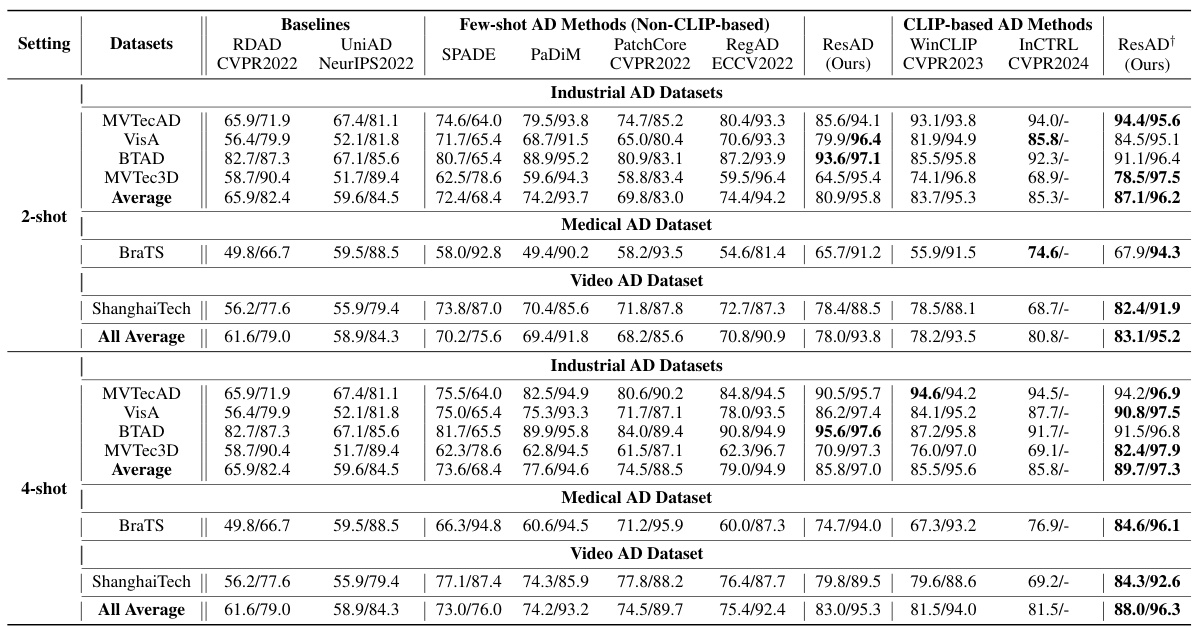
This figure shows additional qualitative results on the MVTecAD dataset. It presents anomaly score maps generated by various anomaly detection methods (RDAD, UniAD, PatchCore, WinCLIP, and the proposed method, Ours) for several examples from the dataset. Each row displays a test image, its corresponding ground truth anomaly mask, and the anomaly score maps generated by the different methods. The visualizations illustrate the performance of the methods in terms of accurately localizing anomalies in images.
This figure shows additional qualitative results on the MVTecAD dataset. It visually compares the anomaly localization maps generated by several different methods (RDAD, UniAD, PatchCore, WinCLIP, and the proposed ResAD method) against the ground truth anomaly masks for various product categories and defect types within the dataset. This allows for a direct visual comparison of the effectiveness of each method in accurately identifying and localizing anomalies within images.
More on tables

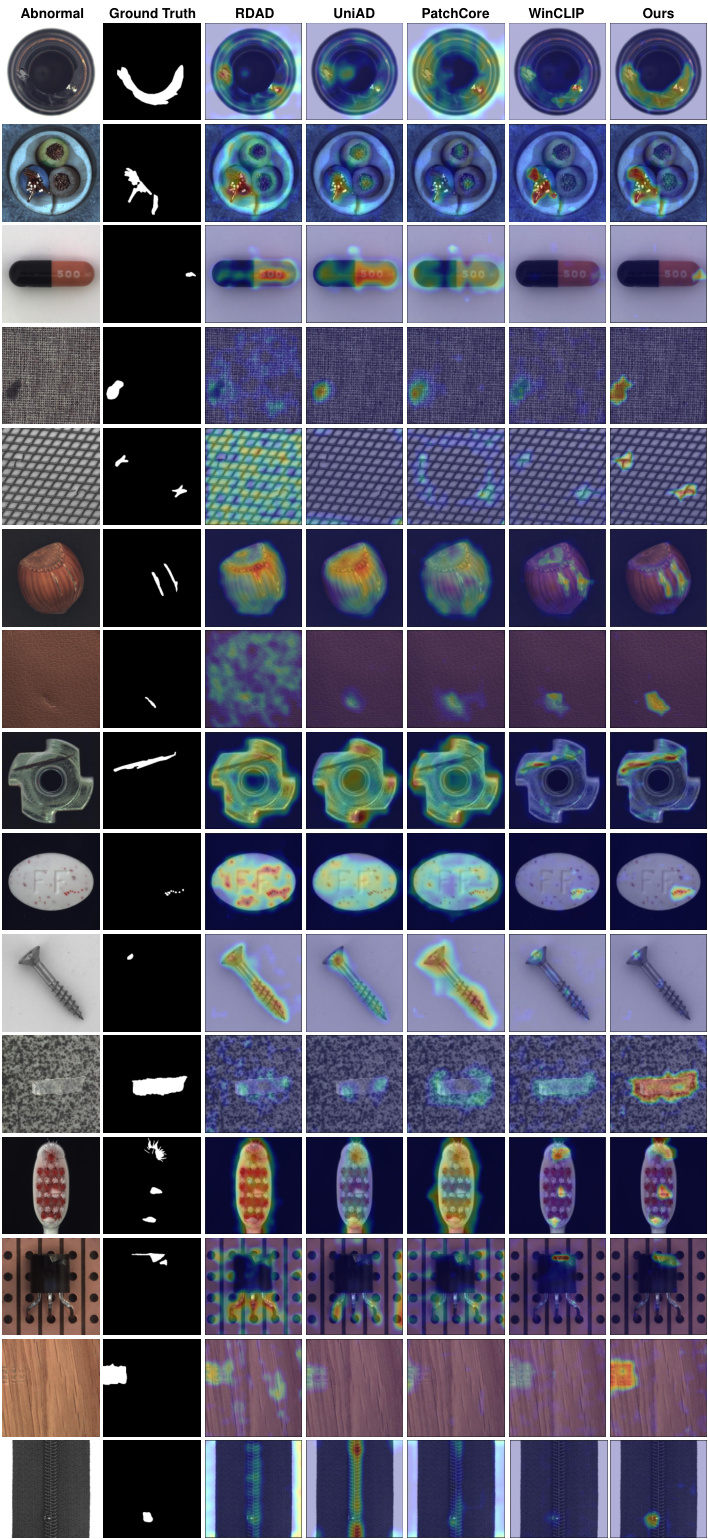
This table presents the ablation study results on the MVTecAD dataset. It shows the impact of removing key components (residual feature learning, feature constraintor, and abnormal invariant OCC loss) from the proposed ResAD model on the image-level and pixel-level AUROC. Additionally, it explores different architectures for the feature constraintor to determine the best configuration.
This table presents the ablation study results for the ResAD model on the MVTecAD dataset. It shows the impact of removing key components (residual feature learning, feature constraintor, and abnormal invariant OCC loss) and also explores the effect of different feature constraintor network architectures on the model’s performance. Image-level and pixel-level AUROC scores are reported for each configuration.

This table presents the results of anomaly detection and localization experiments using various few-shot anomaly detection methods on six real-world datasets. The AUROC (Area Under the Receiver Operating Characteristic Curve) metric is used to evaluate the performance, reported separately for image-level and pixel-level detection. The table compares the performance of the proposed ResAD method against several state-of-the-art (SOTA) methods, including those that don’t use few-shot fine-tuning (RDAD, UniAD) and those that only provide image-level scores (InCTRL). The results are shown for 2-shot and 4-shot scenarios, indicating the performance with limited normal sample data.

This table presents the results of anomaly detection and localization experiments using the Area Under the ROC Curve (AUROC) metric on six real-world datasets. The experiments were conducted under various few-shot anomaly detection settings (2-shot and 4-shot). The table compares the performance of the proposed ResAD method with several state-of-the-art (SOTA) methods, including one-for-one and one-for-many approaches. Image-level and pixel-level AUROC scores are provided. Note that some methods don’t use few-shot samples for fine-tuning, and one method (InCTRL) only provides image-level scores.

This table presents a comparison of the proposed ResAD model with other state-of-the-art anomaly detection methods on six real-world datasets. The comparison considers both image-level and pixel-level Area Under the ROC Curve (AUROC) scores. It demonstrates the performance of each method under different few-shot settings (2-shot and 4-shot), highlighting ResAD’s superior class-generalizable ability, especially compared to those models that require fine-tuning or re-training with the new classes.

This table presents a comparison of different anomaly detection methods on six real-world datasets. The results are shown for both image-level and pixel-level AUROC scores, using 2-shot and 4-shot settings (meaning only 2 or 4 normal samples per class were used for reference). Note that some methods only provide image-level results.

This table presents a comparison of anomaly detection and localization results using the Area Under the Receiver Operating Characteristic Curve (AUROC) metric. The results are shown for six real-world datasets across two different few-shot settings (2-shot and 4-shot). The table compares the performance of ResAD against several state-of-the-art (SOTA) methods, including both one-for-one and one-for-many approaches. Note that some methods, like InCTRL, only provide image-level scores, whereas others provide both image-level and pixel-level AUROCs.

This table presents a comparison of anomaly detection and localization results using the Area Under the Receiver Operating Characteristic Curve (AUROC) metric. It evaluates various state-of-the-art (SOTA) methods on six real-world datasets, varying the number of few-shot normal samples used (2-shot and 4-shot). The table highlights the performance differences between methods designed for one-to-one or one-to-many anomaly detection versus those specifically designed for few-shot settings. It also notes that some methods (like InCTRL) only provide image-level scores, thus lacking pixel-level AUROC values.
Full paper#