↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Surgical video-language pretraining (VLP) faces challenges due to limited data and noisy annotations. Current methods struggle with the spatial-temporal aspects of surgical procedures and often lose information during transcription from lecture videos. This leads to models that underperform on downstream tasks like surgical phase recognition and cross-modal retrieval.
To address these, the researchers propose PeskaVLP, a novel framework incorporating hierarchical knowledge augmentation using large language models (LLMs) to improve textual quality. It uses a Dynamic Time Warping (DTW)-based loss function to better capture temporal relations in surgical videos. Experiments show that PeskaVLP outperforms other methods on various surgical scene understanding tasks, particularly in zero-shot settings, demonstrating its effectiveness and robustness.
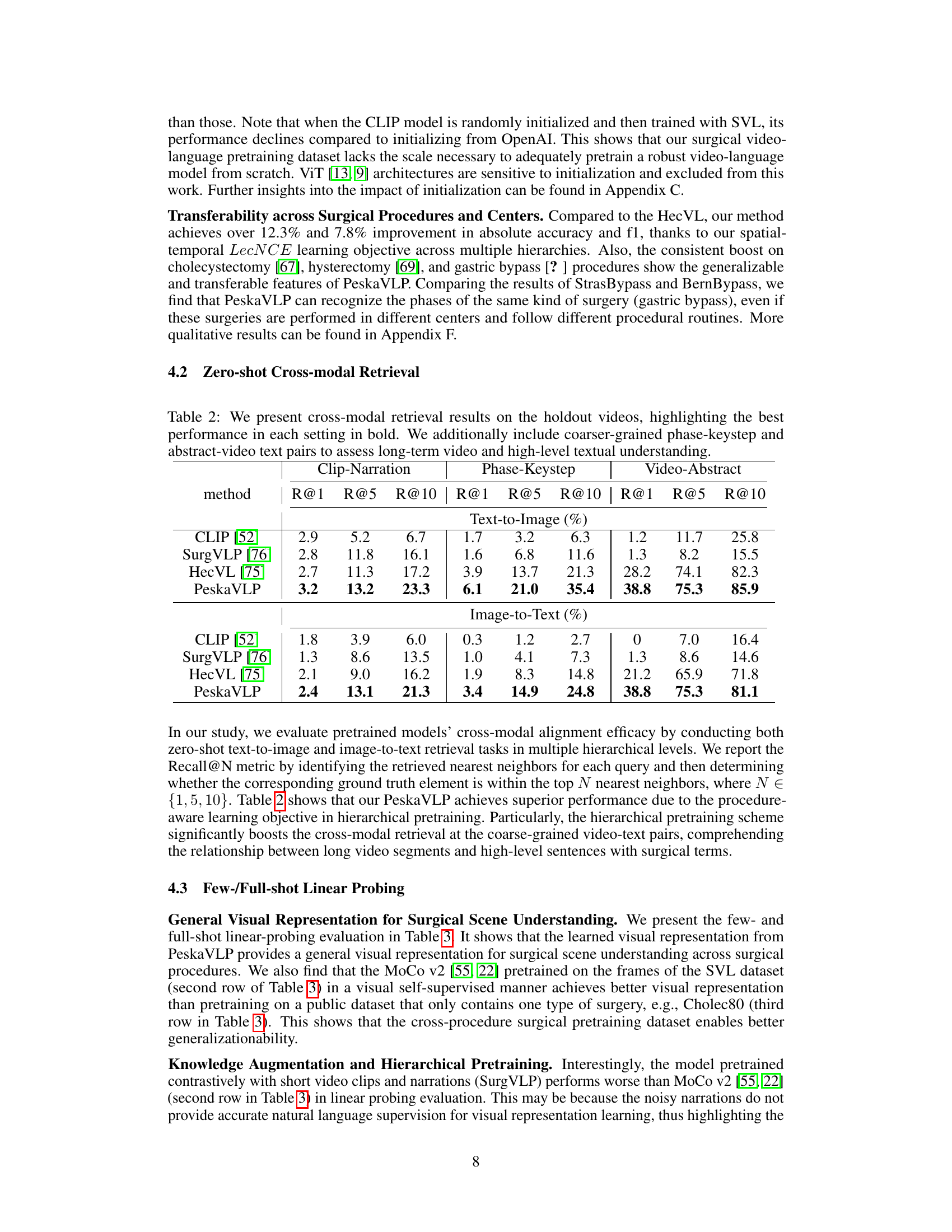
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in surgical data science and multi-modal learning. It introduces a novel approach to surgical video-language pretraining, addressing critical data scarcity and noisy annotations issues. The hierarchical knowledge augmentation and procedure-aware contrastive learning methods significantly improve model performance, opening new avenues for zero-shot transfer learning and cross-modal retrieval in surgical applications. This work will directly influence future research and development in medical image analysis and AI-assisted surgery.
Visual Insights#
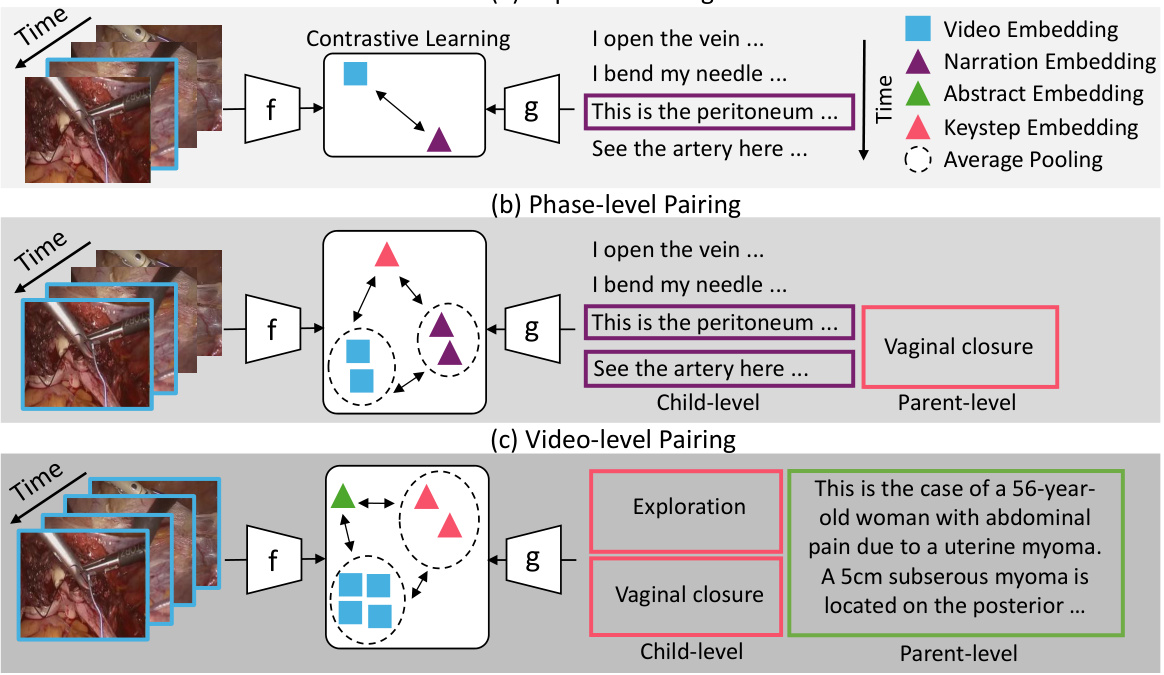
This figure illustrates the hierarchical video-language pretraining approach used in the paper. It shows three levels of pairing between video segments and text descriptions. (a) Clip-level pairing matches short video clips with their corresponding narration sentences. (b) Phase-level pairing links a longer video segment representing a surgical phase with both an overarching phase description (parent-level) and more detailed step-by-step instructions within that phase (child-level). (c) Video-level pairing shows how an entire surgical video is associated with both a summary (parent-level) and a sequence of phase-level descriptions (child-level). This hierarchical structure aims to capture the multi-level temporal dependencies inherent in surgical procedures.
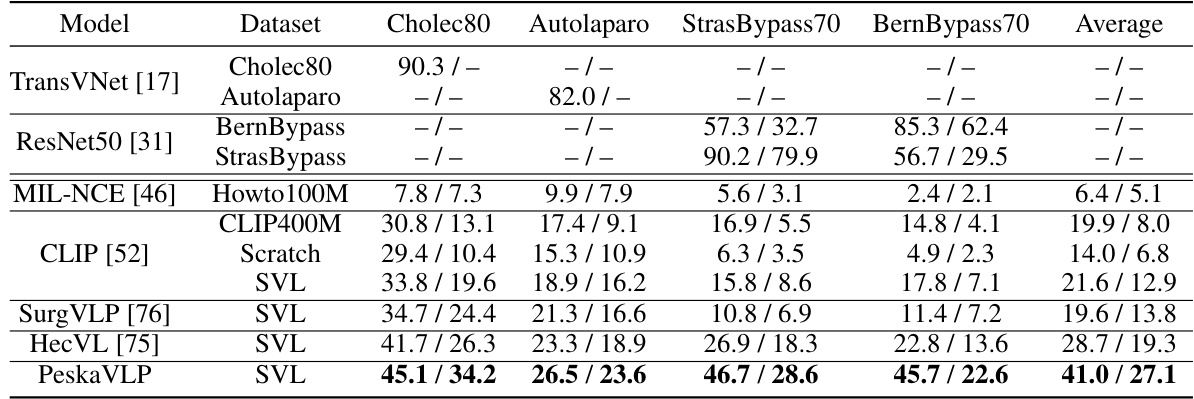
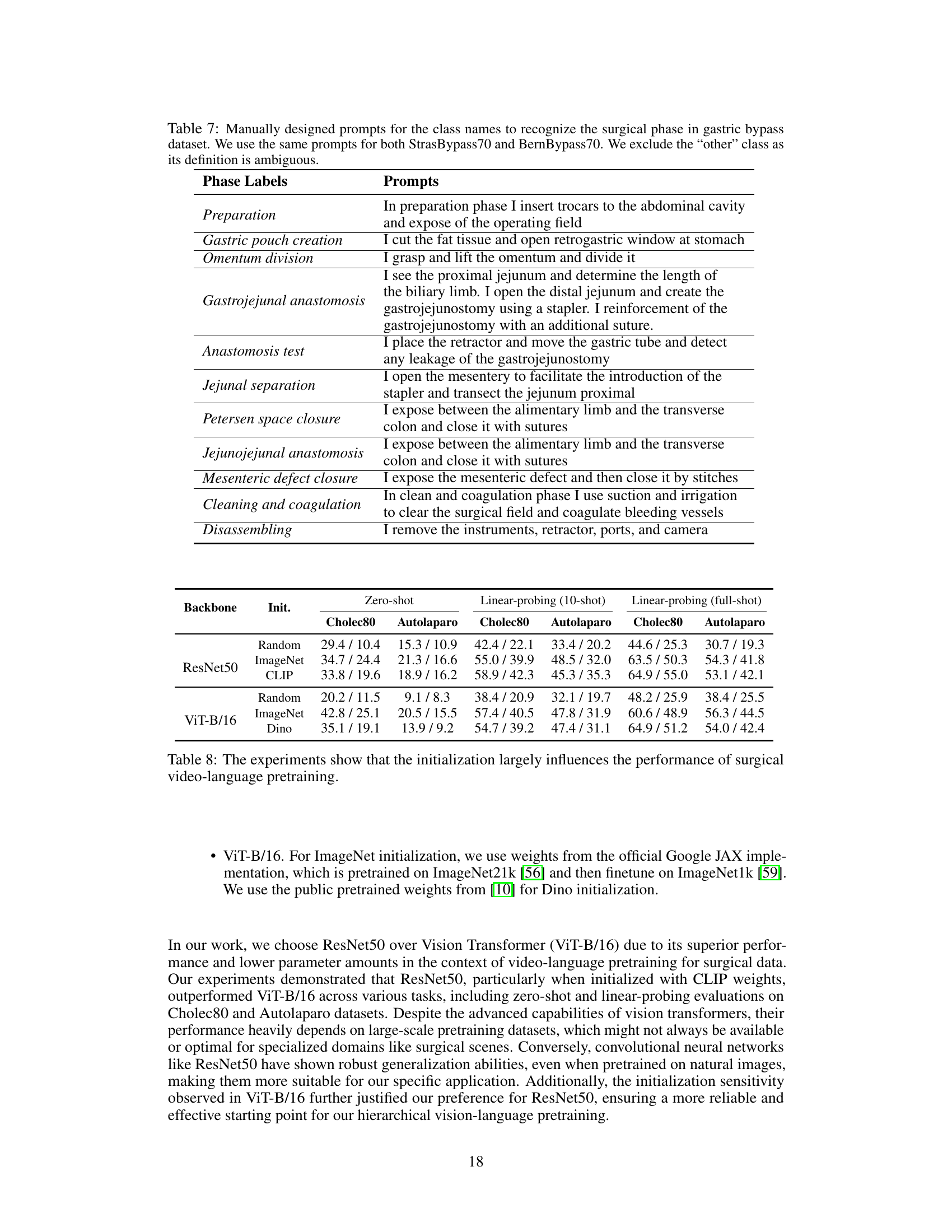
This table presents the zero-shot performance results of different models on three public surgical phase recognition datasets (Cholec80, Autolaparo, StrasBypass70, BernBypass70). The results are reported as Accuracy/F1-score. The table highlights that the proposed PeskaVLP model outperforms other state-of-the-art methods in zero-shot settings. It also notes that fully supervised fine-tuning on specific datasets leads to better performance but shows limited generalizability across different surgical procedures and institutions.
In-depth insights#
Surgical VLP#
Surgical Video-Language Pretraining (VLP) presents a unique challenge in the field of computer vision due to the limited availability of high-quality multi-modal datasets and the inherent complexity of surgical procedures. Standard VLP approaches often struggle with the domain-specific terminology, spatial-temporal nuances, and substantial variations across surgical procedures and centers. Addressing these challenges requires innovative methods that go beyond simple video-text matching. Hierarchical knowledge augmentation, using large language models (LLMs) to enrich textual descriptions and provide comprehensive language supervision, emerges as a promising solution. This technique tackles the issue of textual information loss from noisy transcripts. Furthermore, incorporating procedure-aware contrastive learning improves the alignment between visual and textual modalities, thus allowing the model to effectively understand the temporal dependencies inherent in surgical workflows. This approach leads to improved performance across several downstream tasks like surgical phase recognition, highlighting the potential of sophisticated VLP models for better surgical scene understanding.
Hierarchical Augmentation#
The concept of “Hierarchical Augmentation” in the context of surgical video-language pretraining suggests a multi-level approach to enhance the training data. Instead of relying solely on simple video-text pairs, the method would incorporate richer contextual information at different levels of granularity, such as clip-level, phase-level, and video-level annotations. This hierarchical structure allows for a more comprehensive understanding of surgical procedures and improves the model’s ability to capture temporal dependencies and procedural context. Specifically, it might involve augmenting simple narration transcripts with richer descriptions from large language models, enriching keystep descriptions with additional details, and summarizing overall procedure goals at the video level. This layered approach tackles the challenges of noisy transcriptions and limited data by providing more robust and informative training signals. The effectiveness hinges on the LLM’s ability to accurately capture and refine medical knowledge, thus reducing reliance on potentially flawed or incomplete initial annotations. The key benefit is a more robust and generalized model, capable of zero-shot transfer learning to new surgical domains and tasks.
PeskaVLP Framework#
The PeskaVLP framework, as inferred from the provided context, is a novel approach to surgical video-language pretraining that tackles the challenges of limited data and noisy annotations. Hierarchical knowledge augmentation, leveraging large language models (LLMs), is a core component, enriching textual descriptions and improving language supervision. This addresses textual information loss in surgical videos, reducing overfitting and improving model robustness. Furthermore, PeskaVLP uses visual self-supervision alongside language supervision at the clip level, enhancing efficiency, particularly with smaller datasets. The framework incorporates a dynamic time warping (DTW) based loss function for effective cross-modal alignment at the phase and video levels, ensuring understanding of the temporal dependencies within surgical procedures. This method improves zero-shot transfer and yields generalizable visual representations, potentially advancing surgical scene understanding.
Zero-shot Transfer#
Zero-shot transfer, a crucial aspect of multi-modal learning, is especially relevant in resource-scarce domains like surgical video analysis. It evaluates a model’s ability to generalize to unseen tasks or datasets without any fine-tuning. Success in zero-shot transfer demonstrates the model’s robust feature extraction and generalizable representation learning capabilities. In surgical video-language pretraining, the effectiveness of zero-shot transfer is vital for broad applicability. A strong model, pretrained on a limited dataset, should transfer its learned knowledge to new datasets representing diverse surgical procedures and clinical settings. The paper’s experimental results, showing significant improvement in zero-shot performance compared to existing methods, are encouraging evidence of the model’s robust generalizability. However, further investigation into the model’s performance on even larger and more diverse datasets is crucial for demonstrating truly robust zero-shot transfer capabilities and establishing its effectiveness in real-world applications.
Future Directions#
Future research could explore enhanced data augmentation techniques to address the limitations of current surgical video-language datasets. This could involve synthetic data generation to supplement real-world data, or cross-domain transfer learning leveraging datasets from related medical domains. Another important direction is improving the robustness and generalizability of the models. This might be achieved through the development of more sophisticated architectures capable of handling noise and variations in data, or through the use of domain adaptation methods. Finally, investigating the clinical applicability of these models is crucial. Future work should focus on developing methods for reliable and safe integration of these models into clinical workflows to support real-time surgical decision-making and improve patient outcomes. Addressing ethical concerns around data privacy and algorithmic bias will also be critical for successful clinical deployment.
More visual insights#
More on figures

This figure illustrates the hierarchical video-language pretraining approach used in the PeskaVLP framework. It shows how video clips are paired with text at three levels: clip-level (short video segments paired with short descriptions), phase-level (longer segments paired with descriptions of a surgical phase), and video-level (entire video paired with a summary). The hierarchical structure helps the model learn temporal relationships and understand the overall surgical procedure.
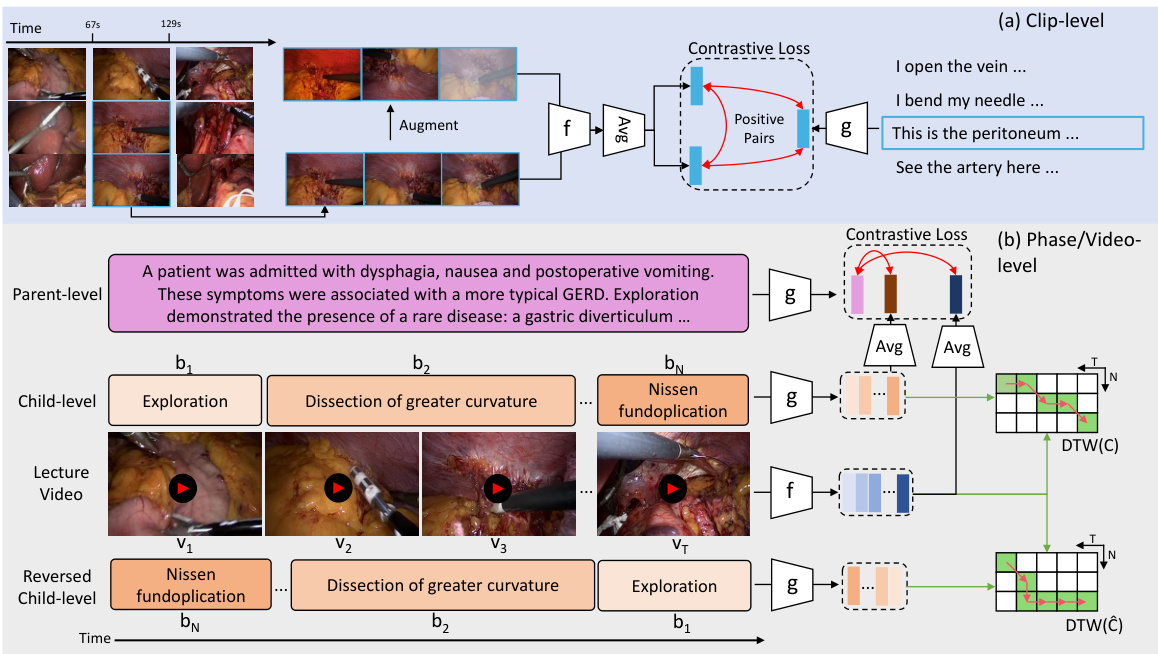
This figure illustrates the PeskaVLP framework’s pretraining pipeline across three hierarchical levels: clip, phase, and video. Clip-level pretraining uses contrastive learning with both language supervision (matching video clips to their narration texts) and visual self-supervision (maximizing similarity between two augmented views of the same clip). Phase and video-level pretraining use a procedure-aware contrastive learning approach which incorporates a Dynamic Time Warping (DTW) based loss function to account for temporal relationships between video frames and text sequences. Hard negative samples are generated by reversing the temporal order of the text sequences, making the model learn the correct temporal alignment. This hierarchical approach is designed to efficiently learn multi-modal surgical representations from a relatively small dataset.

This figure illustrates the PeskaVLP framework’s hierarchical video-language pretraining process. It shows three levels: clip-level, phase-level, and video-level. Clip-level pretraining uses both language supervision (matching video clips with their narration texts) and visual self-supervision (maximizing similarity between two augmented views of the same clip). Phase- and video-level pretraining focus on procedure awareness, using a Dynamic Time Warping (DTW)-based loss function to align video frames and texts, considering their temporal order. The figure visually represents the different components and connections within the framework, illustrating how the model learns multi-modal representations at multiple levels of detail.
This figure illustrates the hierarchical video-language pretraining approach used in the PeskaVLP framework. It shows how video clips are paired with multiple levels of textual descriptions. At the clip level, short video segments are paired with single sentences describing the action. At the phase level, longer video segments are paired with multiple sentences describing different key steps within a surgical phase. At the video level, the entire video is paired with a summary of the entire procedure. This hierarchical approach allows the model to learn both short-term and long-term temporal relationships between visual and textual information in surgical videos.
This figure illustrates the hierarchical video-language pretraining approach used in the PeskaVLP framework. It shows three levels of pairing: clip-level (short video segments paired with single sentences), phase-level (longer video segments paired with multiple sentences describing a phase of the procedure), and video-level (the entire video paired with a summary). This hierarchical structure allows the model to learn relationships between visual information and text at different granularities, improving understanding of complex surgical procedures.
More on tables

This table presents the results of a zero-shot cross-modal retrieval experiment. The experiment evaluated the ability of different models to retrieve relevant videos given text queries and vice-versa, at three different levels of granularity: clip-narration (short-term video-text pairs), phase-keystep (mid-term video-text pairs), and video-abstract (long-term video-text pairs). The Recall@N metric (where N=1,5,10) is reported, indicating the percentage of times the correct video or text was among the top N retrieved results. The table highlights the best-performing model (PeskaVLP) across various retrieval tasks.
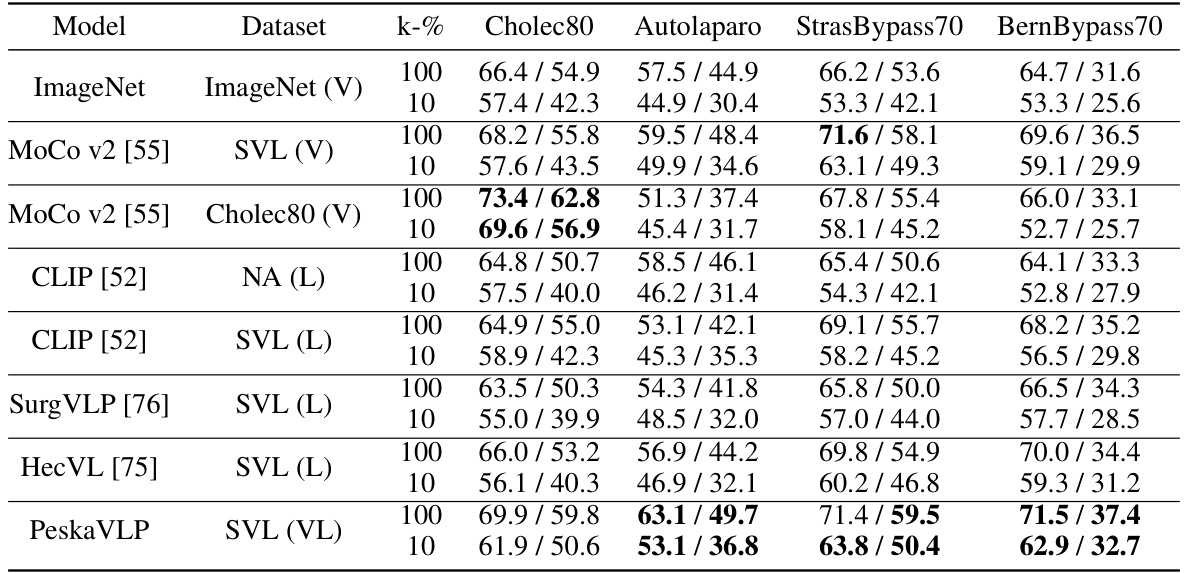
This table presents the zero-shot performance of various models on three public surgical phase recognition datasets (Cholec80, Autolaparo, StrasBypass70, BernBypass70). The results are reported as Accuracy and F1-Score. The table highlights that PeskaVLP outperforms other methods, indicating its superior generalizability. A comparison is also made with fully supervised state-of-the-art models which shows that while they perform well on their specific dataset, they lack generalizability.
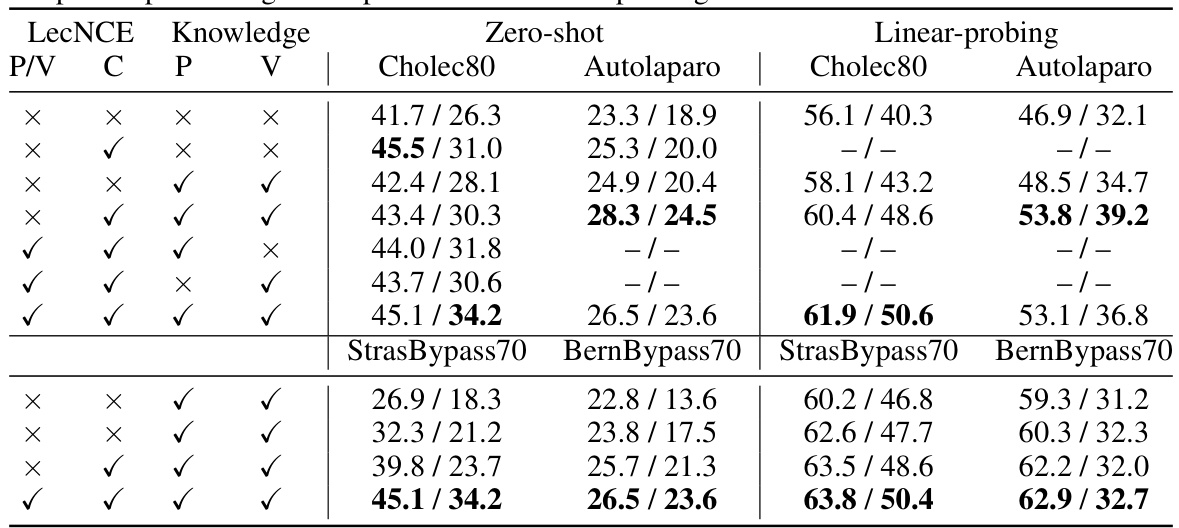
This table presents the results of an ablation study evaluating the impact of different components of the proposed PeskaVLP model on the performance of surgical phase recognition. The ablation study varies the presence of knowledge augmentation, procedure-aware pretraining, and visual self-supervision at different levels (clip, phase, video). The results, which are reported for 10% shot linear probing, show how each component contributes to the overall performance of the model.

This table presents the results of zero-shot surgical phase recognition experiments on three public datasets (Cholec80, Autolaparo, and MultiBypass). The accuracy and F1-score are reported for several models, including PeskaVLP and state-of-the-art fully supervised methods. The table highlights PeskaVLP’s superior performance and emphasizes the limited generalizability of fully supervised models when applied to different surgical procedures or centers.

This table presents the zero-shot phase recognition results on three public datasets: Cholec80, Autolaparo, and MultiBypass140. The accuracy and F1-score are reported for several models including TransVNet, ResNet50, MIL-NCE, CLIP, SurgVLP, and HecVL. The table highlights that PeskaVLP outperforms other methods across all three datasets, demonstrating its superior generalizability. It also notes that while fully supervised fine-tuning achieves higher performance, it suffers from a lack of generalizability across different surgical procedures and institutions.
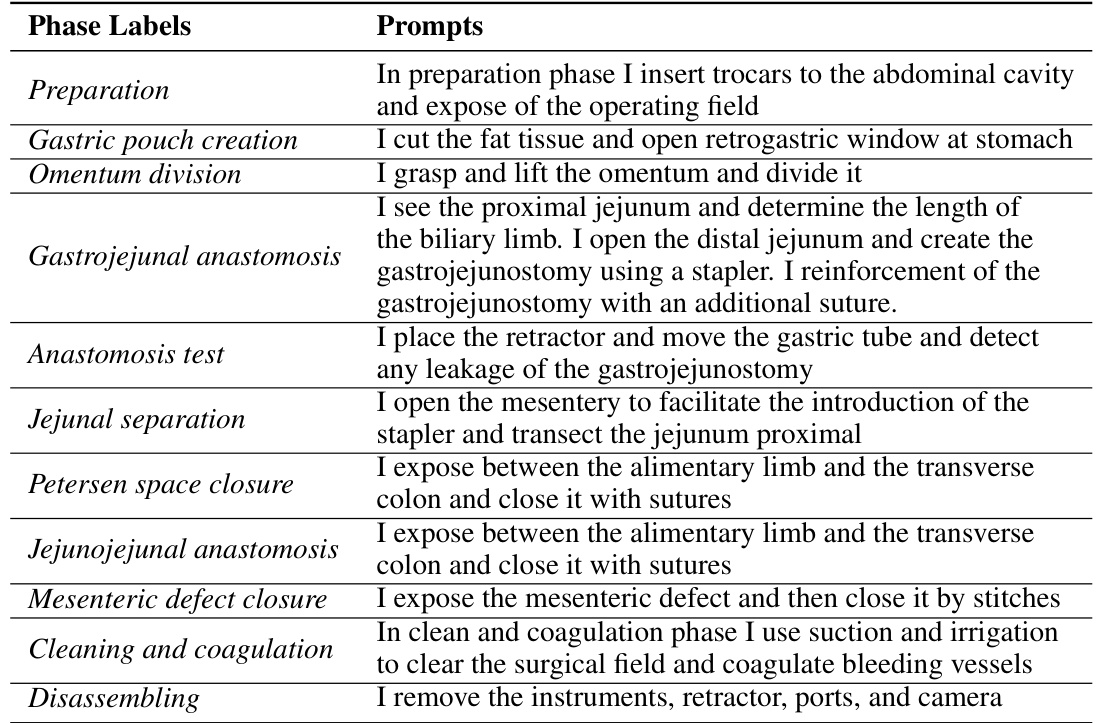
This table presents the zero-shot phase recognition results on three public datasets: Cholec80, Autolaparo, and MultiBypass140. The results compare PeskaVLP’s performance against several other state-of-the-art models. The table highlights PeskaVLP’s superior performance and demonstrates the limited generalizability of fully supervised models fine-tuned on specific datasets. Accuracy and F1-Score are reported for each dataset.
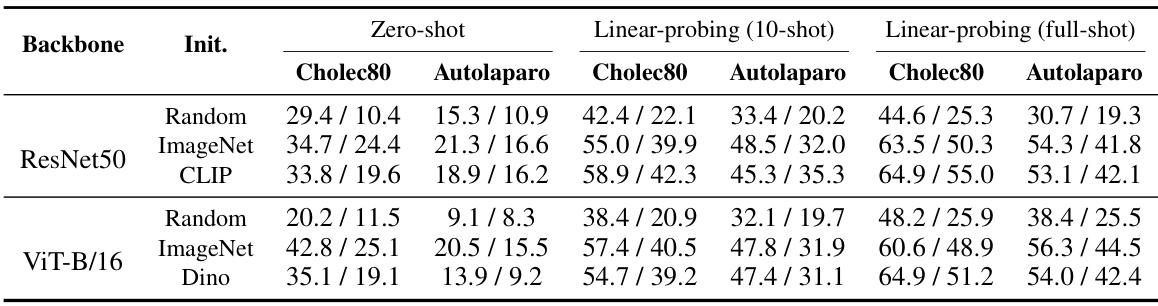
This table presents the zero-shot phase recognition performance of PeskaVLP and other state-of-the-art methods on three public surgical datasets: Cholec80, Autolaparo, and MultiBypass. Zero-shot performance means the models were not fine-tuned on these specific datasets; instead, they leveraged knowledge learned during pre-training. The results show that PeskaVLP achieves superior performance compared to other models across all three datasets. It also highlights the limited generalizability of fully supervised fine-tuned models which perform well on their specific training datasets but generalize poorly to other procedures or institutions.
Full paper#