↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Many real-world applications of contextual bandits, such as clinical trials and online advertising, face the challenge of limited adaptivity, where frequent policy updates are infeasible. Existing algorithms often struggle with this constraint or fail to provide strong theoretical guarantees. This paper addresses this limitation by studying the contextual bandit problem with generalized linear reward models. The problem is particularly challenging due to instance-dependent non-linearity parameters that can significantly affect the performance of algorithms.
The researchers propose two novel algorithms, B-GLinCB and RS-GLinCB, to tackle the problem. B-GLinCB is designed for a setting where the update rounds must be decided upfront. RS-GLinCB addresses a more general setting where the algorithm can adaptively choose when to update its policy. Both algorithms achieve optimal regret guarantees (Õ(√T)), notably eliminating the dependence on the instance-dependent non-linearity parameter. This is a significant improvement over previous algorithms, which often have sub-optimal regret bounds. The algorithms also demonstrate computational efficiency, making them practically feasible for various real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical challenge of limited adaptivity in contextual bandit algorithms, a common constraint in real-world applications. By providing novel algorithms with optimal regret guarantees that are free of instance-dependent parameters, it enables more effective decision-making in various scenarios with limited feedback. This work opens up new avenues for research into designing efficient algorithms for scenarios with limited feedback while maintaining optimality.
Visual Insights#
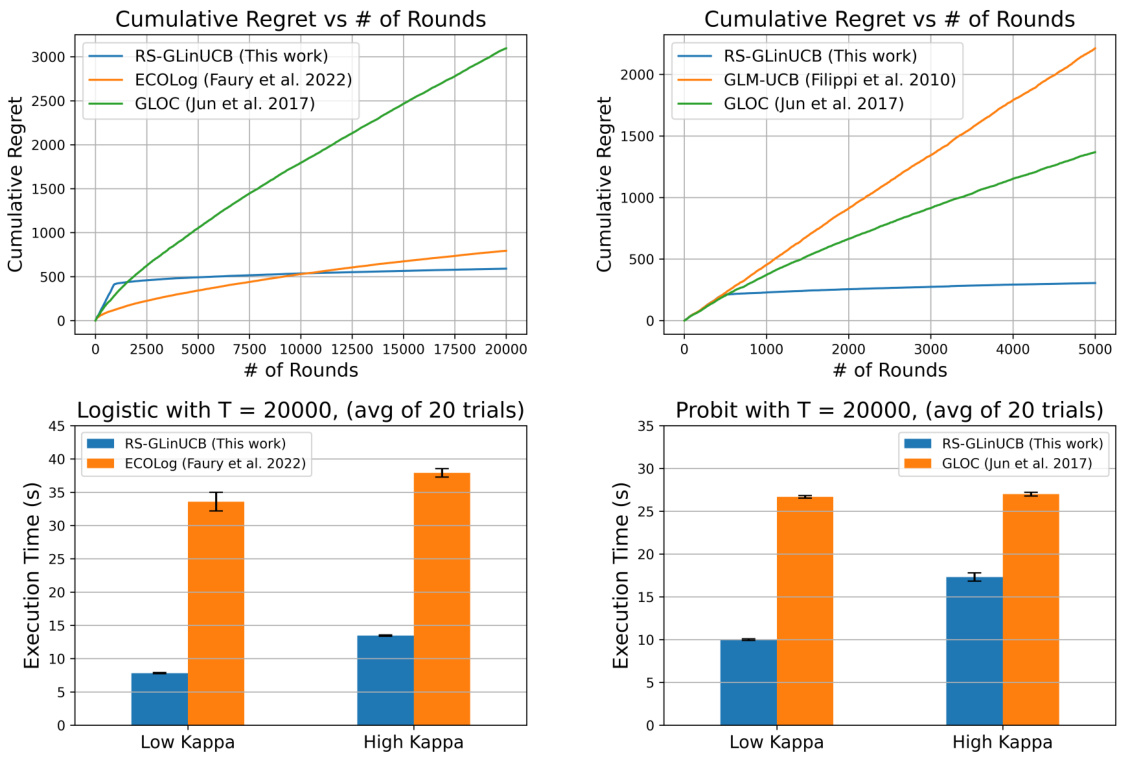
The figure compares the performance of RS-GLinUCB with other algorithms (ECOLog, GLOC, GLM-UCB) in terms of cumulative regret and execution time. The top panels show the cumulative regret for Logistic and Probit reward models, while the bottom panels show the execution time for different values of kappa (a measure of non-linearity). RS-GLinUCB demonstrates lower regret and comparable or better execution times.
Full paper#