↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Reinforcement Learning from Human Feedback (RLHF) is a powerful technique for aligning AI systems with human values. However, existing RLHF methods often struggle with the inherent diversity of human preferences, leading to suboptimal performance for minority groups. This is because these methods typically average over differing preferences, leading to inaccurate reward models and poor results for subgroups. This paper addresses this challenge by focusing on the need for a pluralistic approach, acknowledging and respecting the diverse preferences of various user populations.
The paper introduces Variational Preference Learning (VPL), a novel framework that models human preferences as a latent variable. VPL infers a user-specific latent representation from a few preference annotations, then learns reward models and policies conditioned on this latent without requiring additional user-specific data. The experiments demonstrate VPL’s ability to accurately model diverse preferences, resulting in improved reward function accuracy and personalized policies. The authors also show that their probabilistic framework enables uncertainty measurement and active learning of user preferences.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical challenge of personalizing reinforcement learning from human feedback (RLHF). Current RLHF methods struggle with diverse user preferences, leading to inaccurate rewards and poor performance. This work is relevant to many researchers in AI alignment, robot learning, and human-computer interaction, opening avenues for building more inclusive and effective AI systems.
Visual Insights#

The figure illustrates the limitations of current Reinforcement Learning from Human Feedback (RLHF) techniques that assume a unimodal reward model, ignoring diverse user preferences. It contrasts this with the proposed Variational Preference Learning (VPL) method which models multiple reward functions based on inferred user-specific latent variables. VPL personalizes the rewards and policies to better align with individual user preferences, addressing issues of under-representation in traditional RLHF.

This table compares the performance of three different reward models (BTL, DPL, and VPL) on two datasets (Pets and UltraFeedback). It shows the accuracy of each model in predicting user preferences, with VPL significantly outperforming the baselines. The results are presented separately for GPT-2 and Llama2-7b language models.
In-depth insights#
Pluralistic RLHF#
Pluralistic RLHF addresses a critical limitation of standard RLHF: its inability to handle diverse human preferences. Traditional RLHF often averages preferences, leading to suboptimal or even unfair outcomes for minority groups. Pluralistic RLHF aims to overcome this by explicitly modeling and incorporating the diversity of human values and preferences. This might involve techniques like latent variable models to infer underlying preferences from user behaviors, multimodal RLHF methods to leverage different data types representing preferences, or active learning strategies that efficiently gather preference data from diverse users. A key challenge lies in ensuring that the learned model is both accurate in capturing individual preferences and robust enough to generalize well to unseen users. Algorithmic considerations, such as reward scaling and handling of noisy preferences, are crucial for the success of pluralistic RLHF. The ultimate goal is to build AI systems that are truly aligned with the diverse values of their users, leading to more equitable and beneficial outcomes.
VPL Algorithm#
The Variational Preference Learning (VPL) algorithm presented in the paper offers a novel approach to personalizing reinforcement learning (RL) by explicitly modeling diverse human preferences. VPL addresses the limitations of existing RLHF methods that often average over differing preferences, resulting in suboptimal performance for individual users. Instead, VPL leverages a latent variable model to infer user-specific preferences, effectively learning a distribution of reward functions. The algorithm uses a variational encoder to infer a latent representation capturing user-specific contexts, conditioning the reward model and subsequent policy on this latent variable. This allows for personalized policies that better cater to individual user needs. A key contribution is the technique used to resolve issues of reward scaling, which typically arises from the lack of information about the magnitude of rewards in pairwise preference comparisons. VPL incorporates a pairwise classification scheme to appropriately bound and scale reward estimates, thereby improving the efficiency of policy optimization. The latent variable framework further enables uncertainty quantification and active learning, allowing the system to efficiently learn user preferences through targeted queries. Overall, VPL represents a significant advancement in RLHF, offering a more robust and adaptable approach to aligning AI systems with diverse human preferences.
Reward Scaling#
Reward scaling in reinforcement learning from human feedback (RLHF) is a crucial yet often overlooked challenge. The core issue is that while binary comparisons (A preferred to B) reveal relative preferences, they do not provide information about the magnitude of the reward difference. This lack of scale information significantly affects downstream policy optimization, as reward functions with vastly different scales can lead to unstable training dynamics and suboptimal performance. The paper addresses this by proposing several techniques such as pairwise classification and likelihood-based reward scaling, aiming to appropriately bound and scale reward estimates across different latent user preferences. The authors emphasize that careful algorithmic considerations around model architecture are needed to handle this intrinsic ambiguity of reward scaling and highlight how their chosen approach is specifically designed to address this challenge. The proposed solution enhances the performance of downstream policies by ensuring appropriate reward scaling. This is particularly relevant in scenarios with multiple users with divergent preferences where accurately capturing the diverse reward landscapes is critical for generating truly personalized and effective AI systems.
Active Learning#
Active learning, in the context of this research paper, is a crucial technique for efficiently gathering human feedback in reinforcement learning from human feedback (RLHF). The core idea is to intelligently select the most informative data points for labeling, thus maximizing the information gained about the underlying latent distribution of user preferences. Instead of passively labeling all data, active learning strategically queries users, focusing on areas where preferences are most uncertain or divergent. This not only minimizes the number of labels needed for accurate model adaptation but also enhances the efficiency and personalization of RLHF. The effectiveness of active learning relies on a probabilistic model (the variational encoder in this specific paper), enabling the quantification of uncertainty in user preferences and the selection of the most informative queries based on information gain. By actively focusing on areas of high uncertainty, active learning accelerates the learning process, particularly useful when dealing with diverse user populations with potentially conflicting preferences, a key aspect addressed in this work. The paper’s success demonstrates the significant value of active learning in navigating the challenges of pluralistic alignment in AI.
LLM Alignment#
LLM alignment, the process of aligning large language models (LLMs) with human values, is a critical challenge in AI safety. Current methods often fall short due to limitations in capturing the diversity of human preferences. Approaches relying on a singular reward function struggle to account for the inherent plurality of human values and preferences, leading to suboptimal or even harmful outcomes for certain user groups. Variational Preference Learning (VPL), as presented in the research paper, aims to address this challenge by modeling human preferences as a multi-modal distribution. Instead of averaging diverse preferences into a single reward function, VPL uses a latent variable formulation to infer user-specific preferences, enabling personalization and improved alignment across a broad spectrum of user values. VPL demonstrates improved accuracy in reward modeling and personalized policy learning, successfully handling conflicting preferences and actively learning from limited user interactions. The work suggests that VPL could significantly enhance the safety and societal impact of LLMs by enabling alignment across diverse communities and mitigating potential biases resulting from current unimodal reward learning methods. However, challenges regarding scalability and practical applications in real-world scenarios remain an area for further exploration and research.
More visual insights#
More on figures
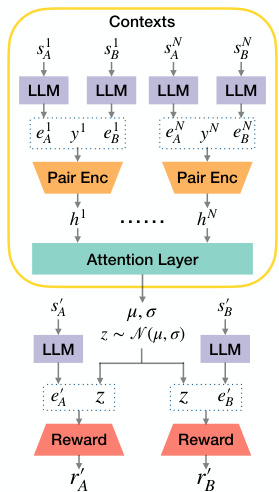
This figure illustrates the architecture of the Variational Preference Learning (VPL) model for Large Language Models (LLMs). The left side shows the encoder which takes pairs of prompt and response embeddings as input, processes them through a pair encoder and an attention layer to infer a latent representation z (representing user preferences). The right side shows the reward model, which takes the latent representation z and a new state (prompt and response) as input, to predict a reward. The model uses a pre-trained LLM to encode prompt and response pairs.
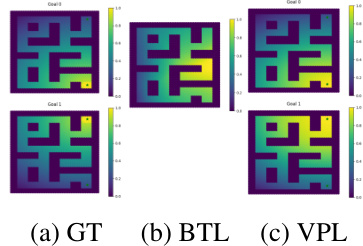
This figure compares the performance of three different reward learning methods: Ground Truth (GT), Bradley-Terry-Luce (BTL), and Variational Preference Learning (VPL) on a simulated robot navigation task with two distinct goals. The GT shows that different users prefer the robot to reach different goals. The BTL approach, which assumes a unimodal reward function, averages over the user preferences, resulting in a reward function that doesn’t accurately represent any single user’s preferences. The VPL approach, on the other hand, effectively reconstructs the diverse user preferences, capturing the multi-modal nature of the reward function and producing a personalized policy that aligns well with individual user preferences.

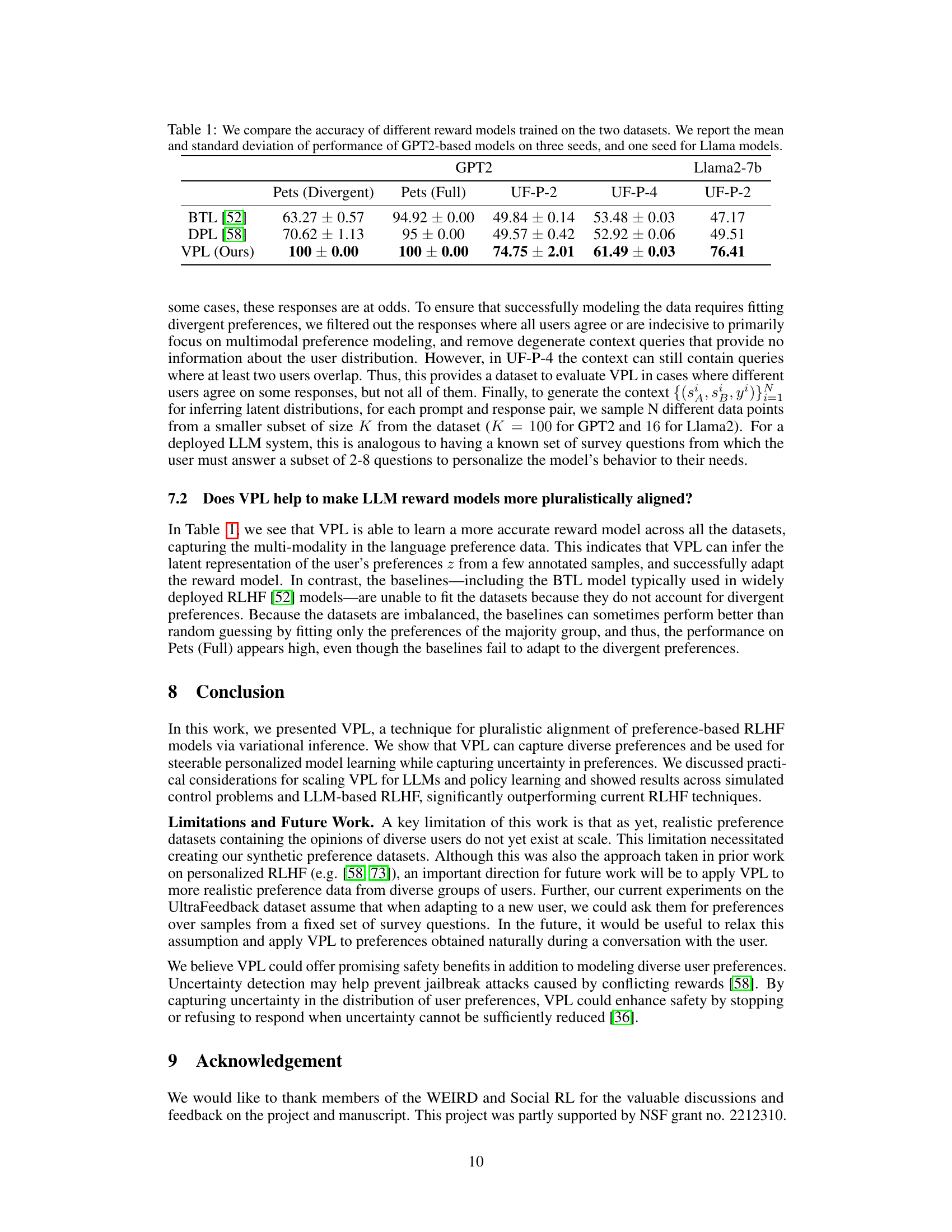
This figure compares the performance of different reinforcement learning methods (Oracle, VPL, VPL+SPO, DPL-MeanVar, DPL-Categorical, and BTL) on four diverse control and reasoning tasks: Maze-Navigation, Ravens-Manipulation, Habitat-Rearrange, and Habitat-Tidy. The y-axis represents the success rate, indicating the percentage of tasks successfully completed by the agent using policies trained with each method. The results illustrate that VPL and VPL+SPO consistently outperform the baseline methods, demonstrating their effectiveness in handling multi-modal reward functions, particularly in complex tasks. The note clarifies that for Habitat environments, due to the nature of their one-step greedy policies, reward scaling and the SPO+VPL method were not necessary.
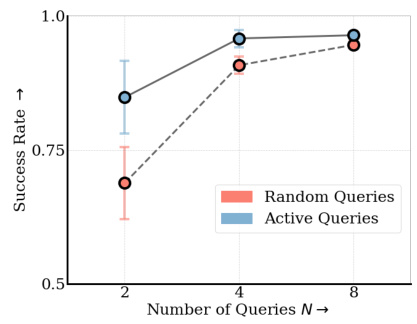
This figure shows the results of an experiment comparing the performance of active and random query selection strategies in a latent-variable preference-based reward learning method. The x-axis represents the number of queries used, and the y-axis represents the success rate of the resulting policy. The figure demonstrates that active query selection consistently outperforms random selection, achieving the same performance with only half the number of queries, thereby improving the efficiency of preference learning.

This figure shows a didactic example to illustrate the differences between standard BTL, DPL, and the proposed VPL methods for multi-modal reward learning. Four Gaussian reward functions generate diverse binary preference data. BTL averages the different modes, resulting in an inaccurate representation. DPL captures the uncertainty but fails to accurately predict the individual modes. VPL, however, infers the hidden context (latent variable) and accurately recovers the individual reward functions.
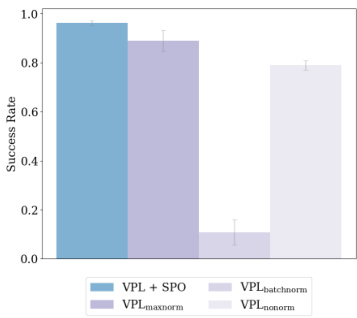
This figure compares the performance of different reward scaling methods in the Maze-Navigation task. It shows that VPL+SPO (Variational Preference Learning with Self-Play Preference Optimization) outperforms other methods, including VPL with different normalization techniques (batchnorm, maxnorm), and VPL without normalization. The results highlight the importance of appropriately scaling rewards to improve the performance of downstream policies.
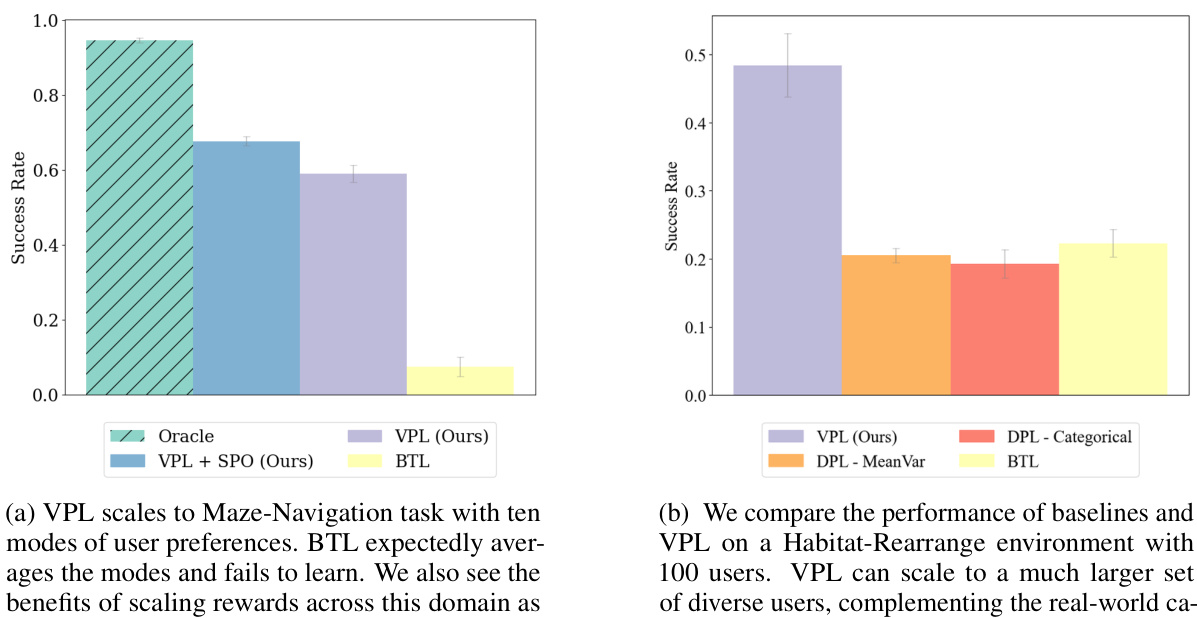
This figure compares the performance of VPL and baselines on two different tasks: Maze-Navigation and Habitat-Rearrange. The Maze-Navigation task demonstrates VPL’s ability to handle multiple reward modes, outperforming BTL which averages them. The Habitat-Rearrange task shows VPL’s scalability to a much larger dataset of diverse users, highlighting its adaptability to real-world scenarios. The benefits of reward scaling (VPL + SPO) are also illustrated in the Maze-Navigation experiment.
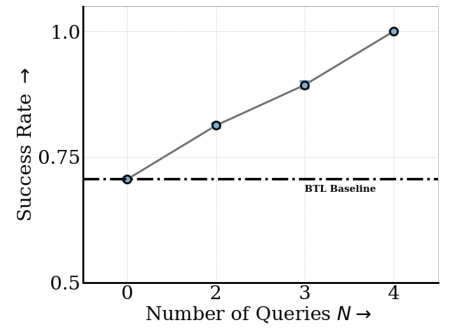
This figure shows the results of an active learning experiment comparing the performance of active and random query selection strategies for personalizing policies to user preferences. The x-axis represents the number of queries, and the y-axis shows the success rate. The results demonstrate that active query selection achieves higher success rates with fewer queries compared to random query selection. The dashed line shows the success rate of a baseline using the standard BTL method.
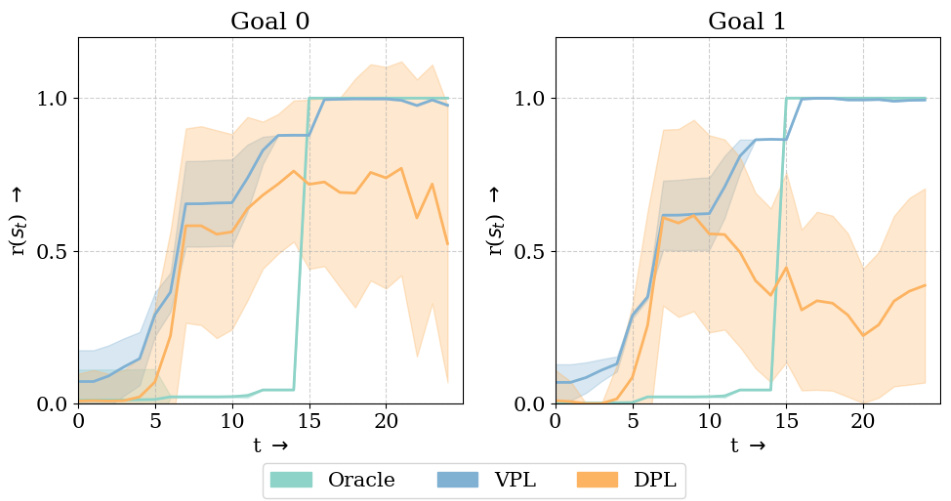
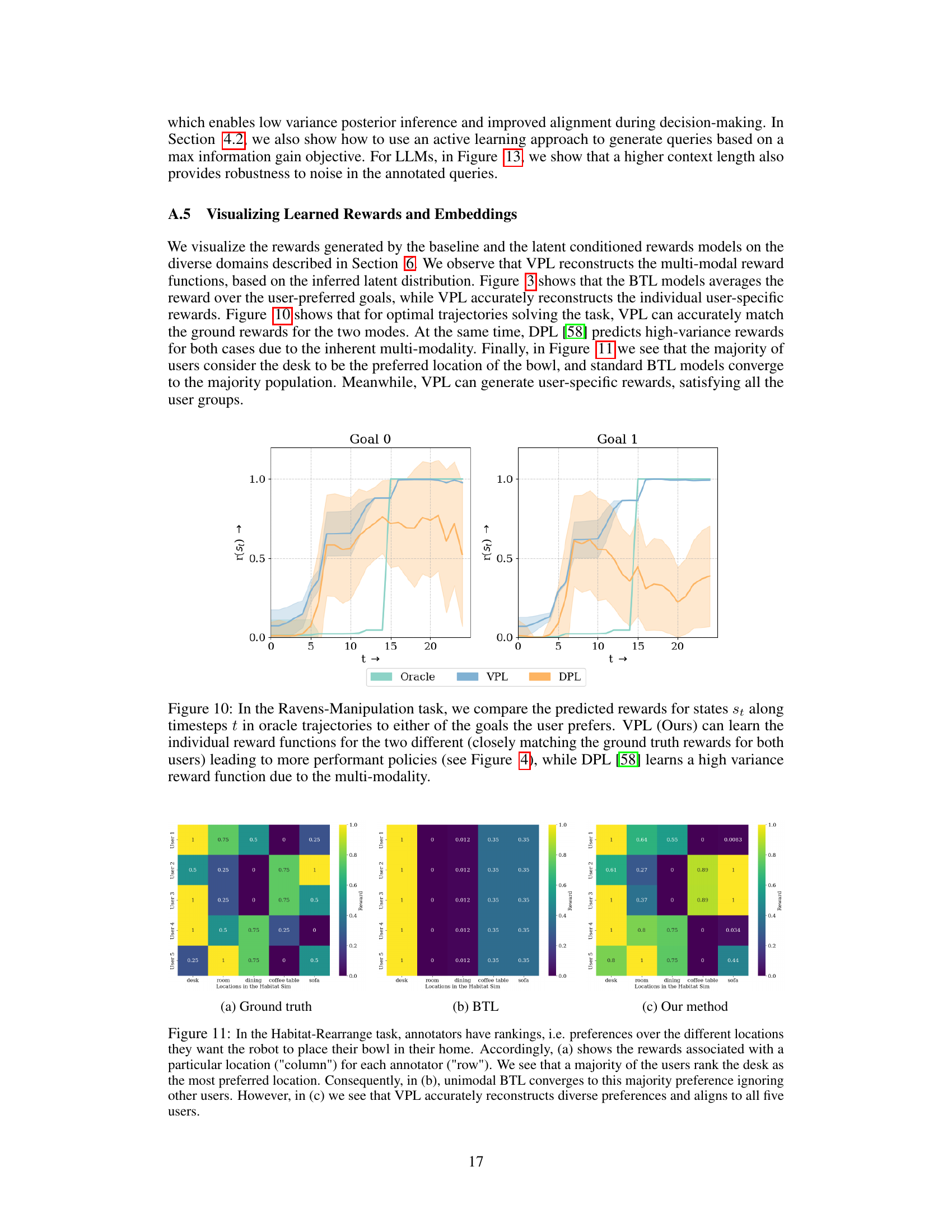
This figure compares the predicted rewards by different models (Oracle, VPL, and DPL) for states in optimal trajectories leading to two different goals. VPL accurately predicts rewards for both goals, while DPL shows high variance due to the multi-modal nature of the rewards.
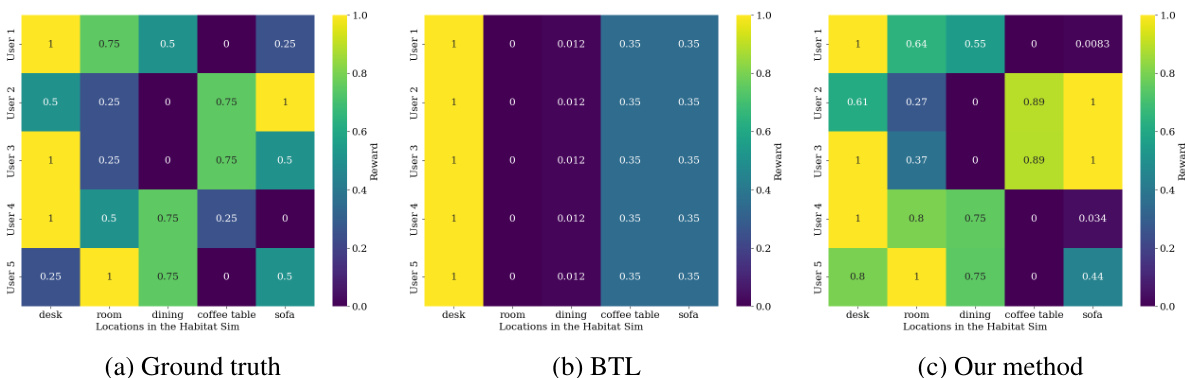
This figure compares the performance of three different methods for learning reward functions: Ground Truth, BTL, and VPL. The Ground Truth shows two distinct reward functions reflecting different user preferences (each user prefers one of two distinct goals). The BTL (Bradley-Terry-Luce) model, a standard approach in RLHF (Reinforcement Learning from Human Feedback), averages these preferences, resulting in a unimodal reward function that inaccurately reflects the true diversity of preferences. In contrast, VPL (Variational Preference Learning), the proposed method, accurately learns a multimodal reward function that captures the distinct preferences of each user. This highlights VPL’s ability to handle pluralistic preferences (multiple preferences within the user base).
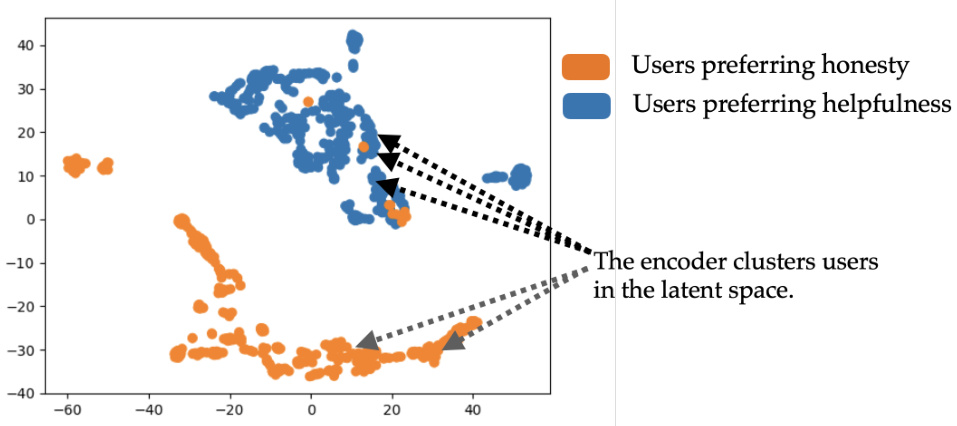
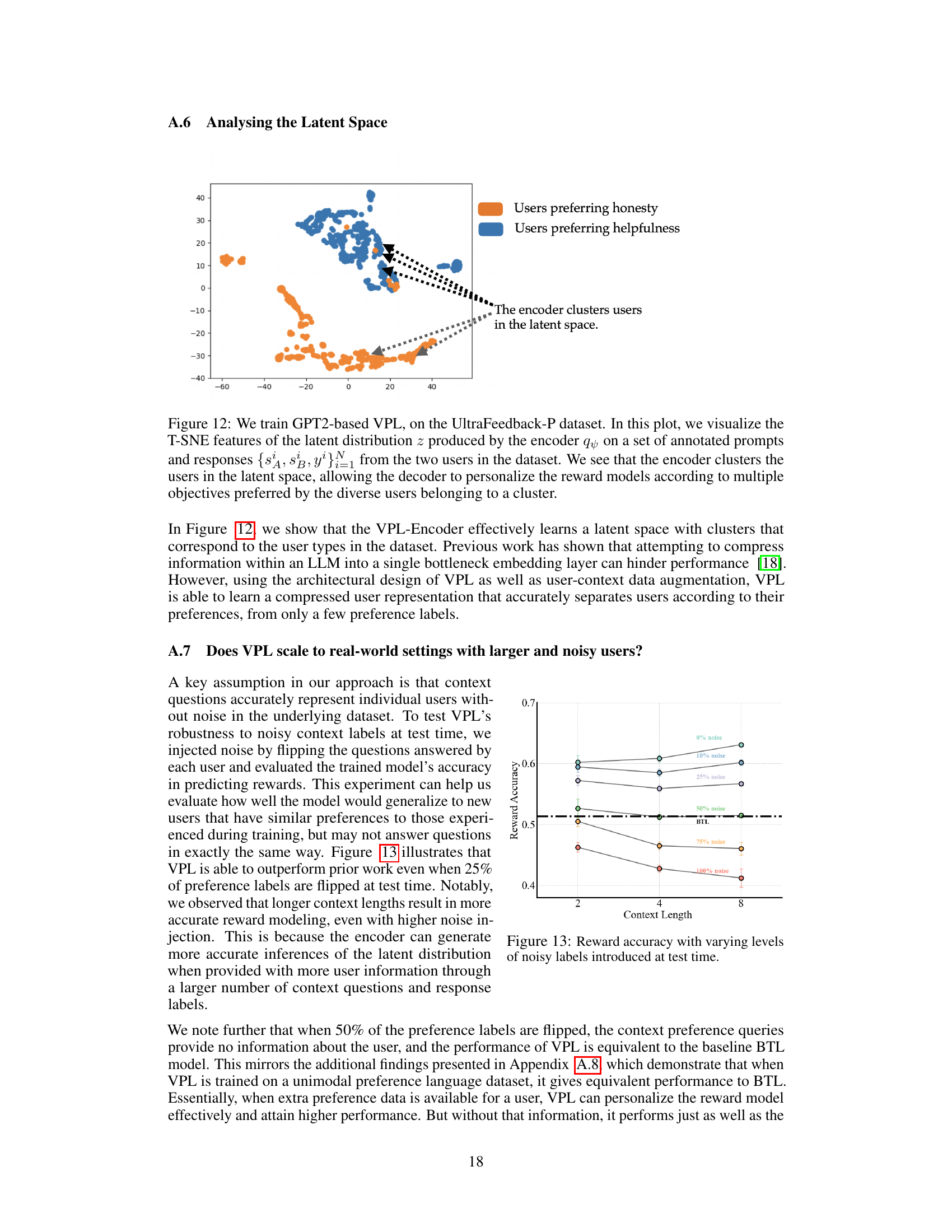
This figure visualizes the t-SNE features of the latent distribution z learned by the encoder in the VPL model. It shows that the encoder effectively clusters users in the latent space based on their preferences. This allows the decoder to create personalized reward models for different user groups.
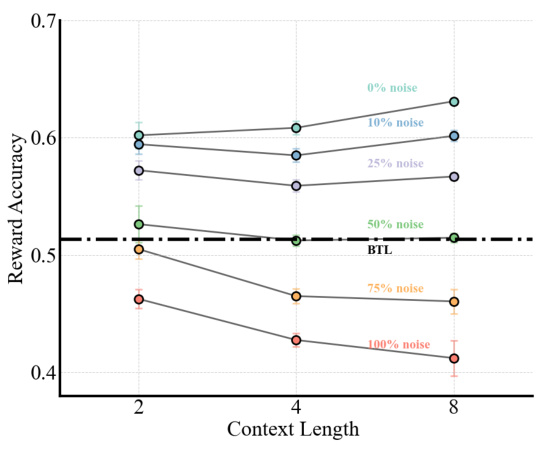
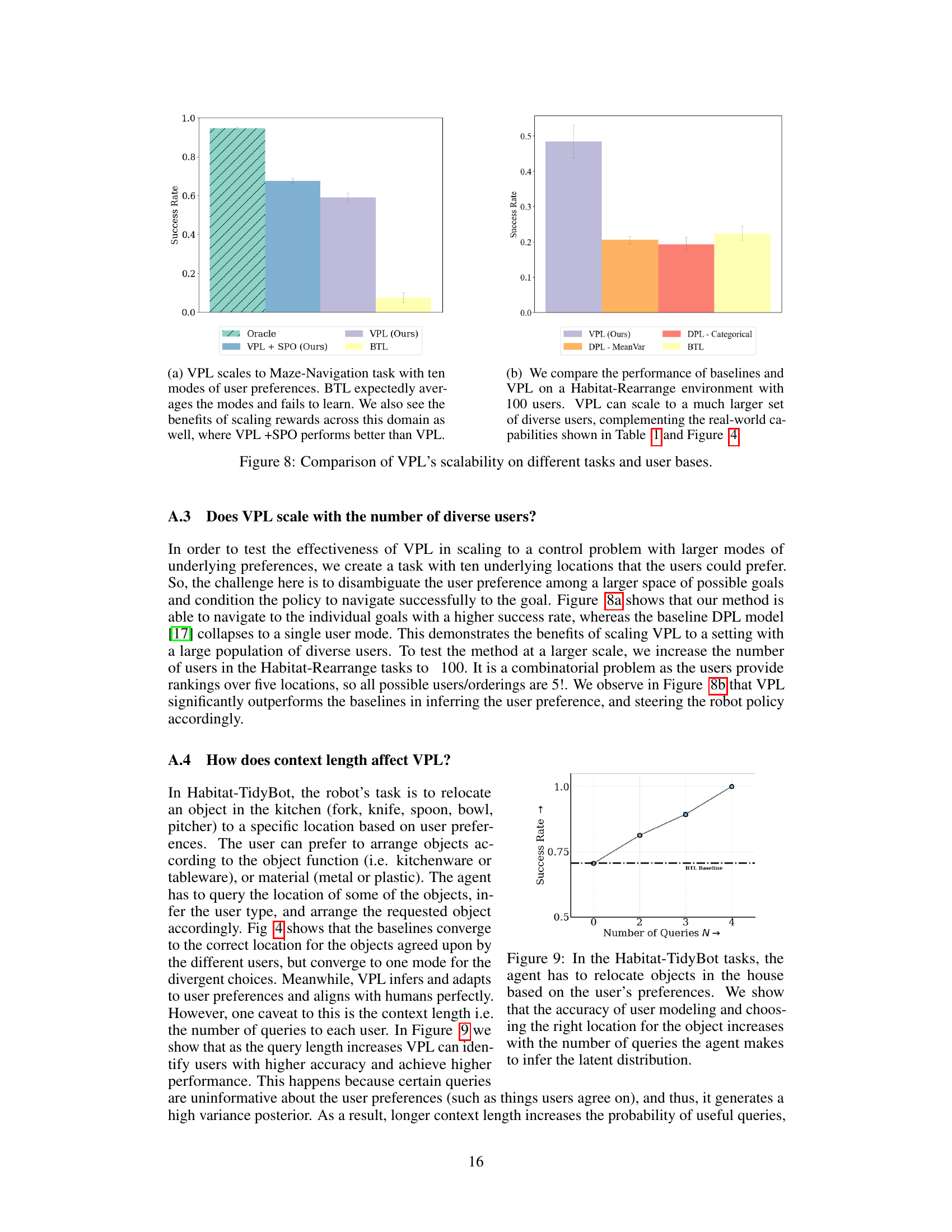
This figure demonstrates the robustness of VPL to noisy labels during testing. It shows reward accuracy across different levels of injected noise (0%, 10%, 25%, 50%, 75%, 100%) in the preference labels used for inference at test time. Different context lengths (2, 4, 8) are also evaluated. The results indicate that VPL maintains relatively high accuracy even with significant noise, especially with longer context lengths. The BTL baseline is shown for comparison, highlighting the performance improvement achieved by VPL.
More on tables
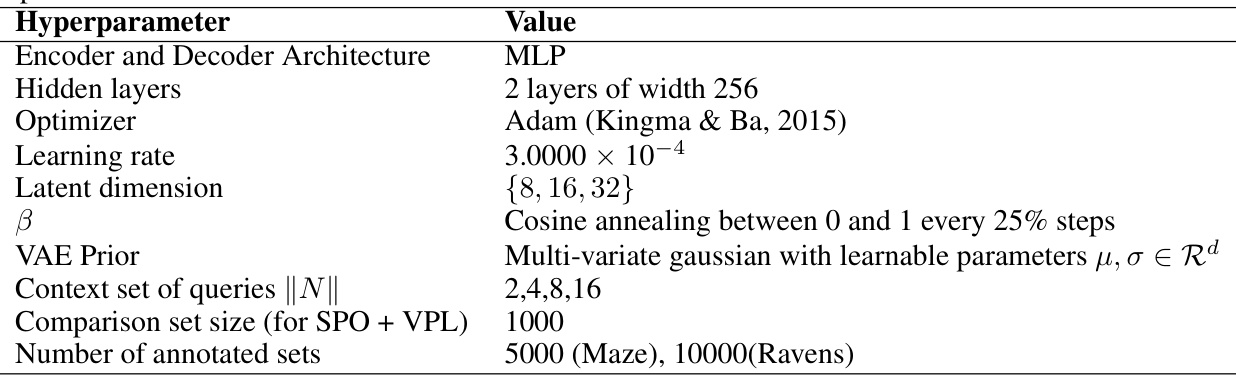
This table lists the hyperparameters used for training reward models with the Variational Preference Learning (VPL) method. The hyperparameters include architectural choices (encoder/decoder structure, number of hidden layers, their width), optimization settings (optimizer, learning rate), the dimensionality of the latent space, a regularization parameter (β), details of the prior distribution over the latent variable (VAE Prior), and the sizes of the data subsets used during training (context set, comparison set, number of annotated sets). The authors swept over different values for these hyperparameters to find the best performing configuration.

This table lists the hyperparameters used for Implicit Q-Learning (IQL), the offline reinforcement learning algorithm used in the paper’s experiments. The hyperparameters include architectural details (MLP layers and widths), the optimizer used (Adam), learning rate, discount factor, expectile, temperature and dataset size. The same hyperparameters were used across all experiments for consistency and reproducibility.
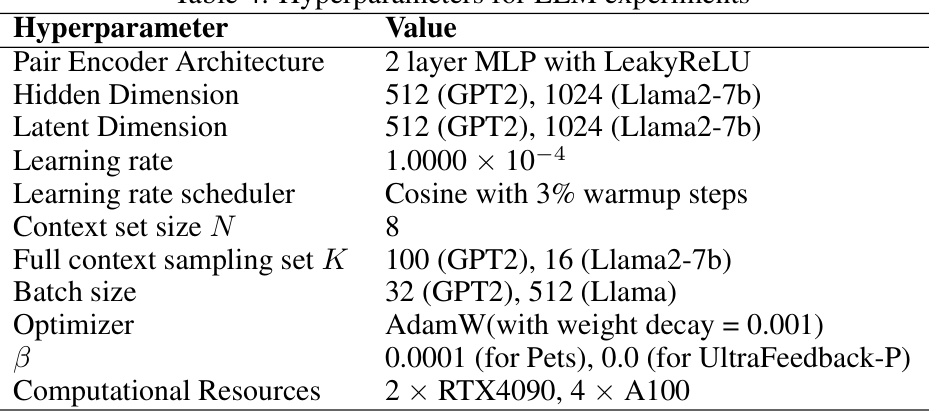
This table lists the hyperparameters used in the experiments with large language models (LLMs). It includes details about the pair encoder architecture, hidden and latent dimensions, learning rate and scheduler, context and sampling set sizes, batch size, optimizer, beta value, and computational resources used.
Full paper#