↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Model-based reinforcement learning often suffers from ‘objective mismatch’, where models optimized for training accuracy may not perform well during actual control. Existing policy representations like feedforward networks, energy-based models, and diffusion models also have limitations in high-dimensional settings. This paper addresses these shortcomings.
The researchers introduce DiffTORI, which uses differentiable trajectory optimization to generate actions. This allows for direct optimization of the task performance through the trajectory optimization process, eliminating objective mismatch. Experiments across model-based RL and imitation learning benchmarks show DiffTORI outperforms current state-of-the-art methods, especially in high-dimensional scenarios, demonstrating its efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in deep reinforcement learning and robotics because it introduces a novel and highly effective policy representation using differentiable trajectory optimization which addresses the limitations of existing methods. It offers a significant improvement in sample efficiency and performance, paving the way for more advanced applications of model-based RL in high-dimensional settings. The proposed method’s scalability to complex tasks with high-dimensional sensory inputs opens up exciting new research avenues.
Visual Insights#
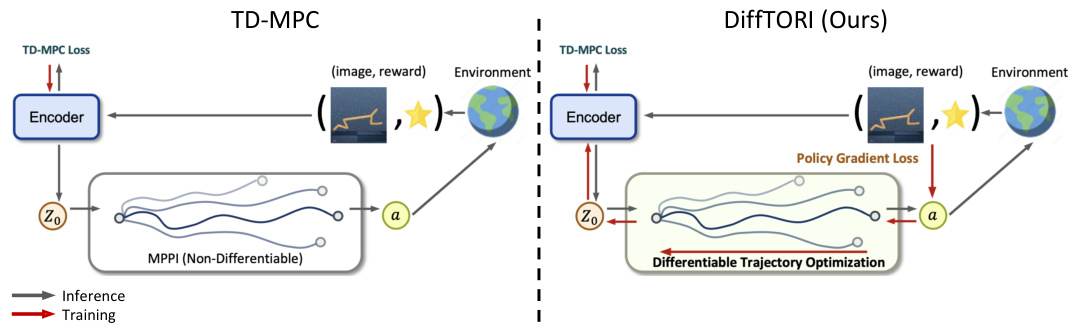
This figure compares the model-based reinforcement learning approaches of TD-MPC and DiffTORI. TD-MPC uses a non-differentiable Model Predictive Path Integral (MPPI) to generate actions. DiffTORI, in contrast, uses differentiable trajectory optimization. The key difference is that DiffTORI computes the policy gradient loss on the generated actions and backpropagates this loss to optimize not only the encoder but also the latent reward predictor and latent dynamics function. This end-to-end optimization aims to maximize task performance.
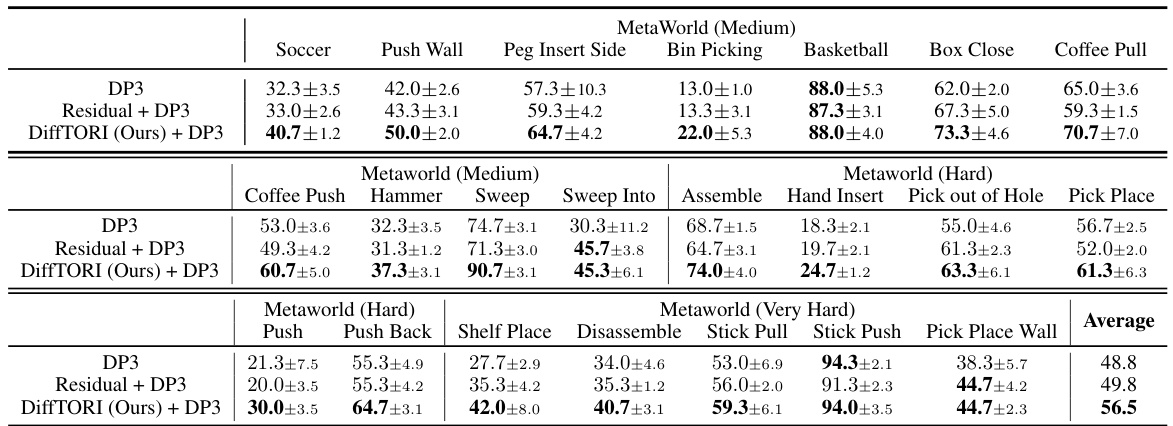
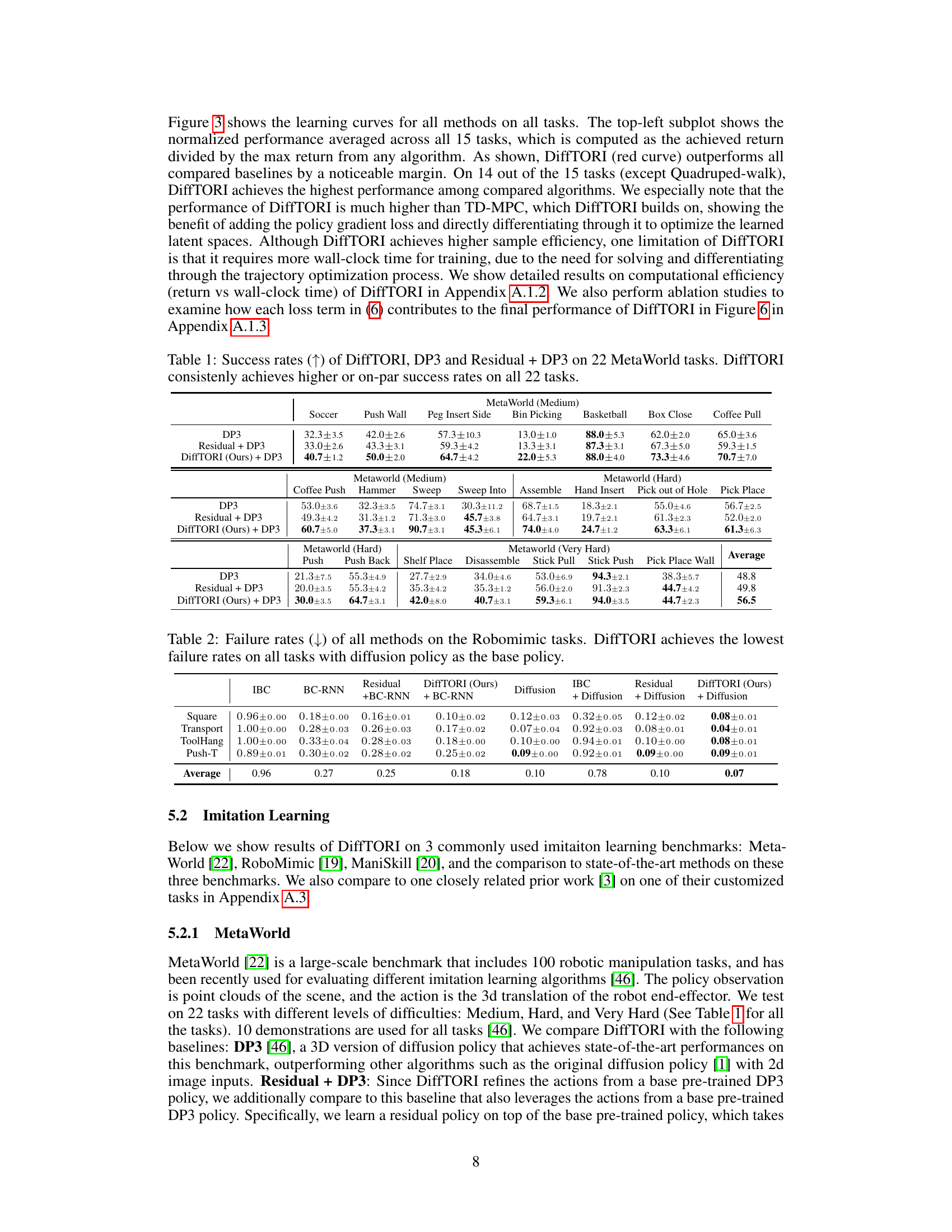
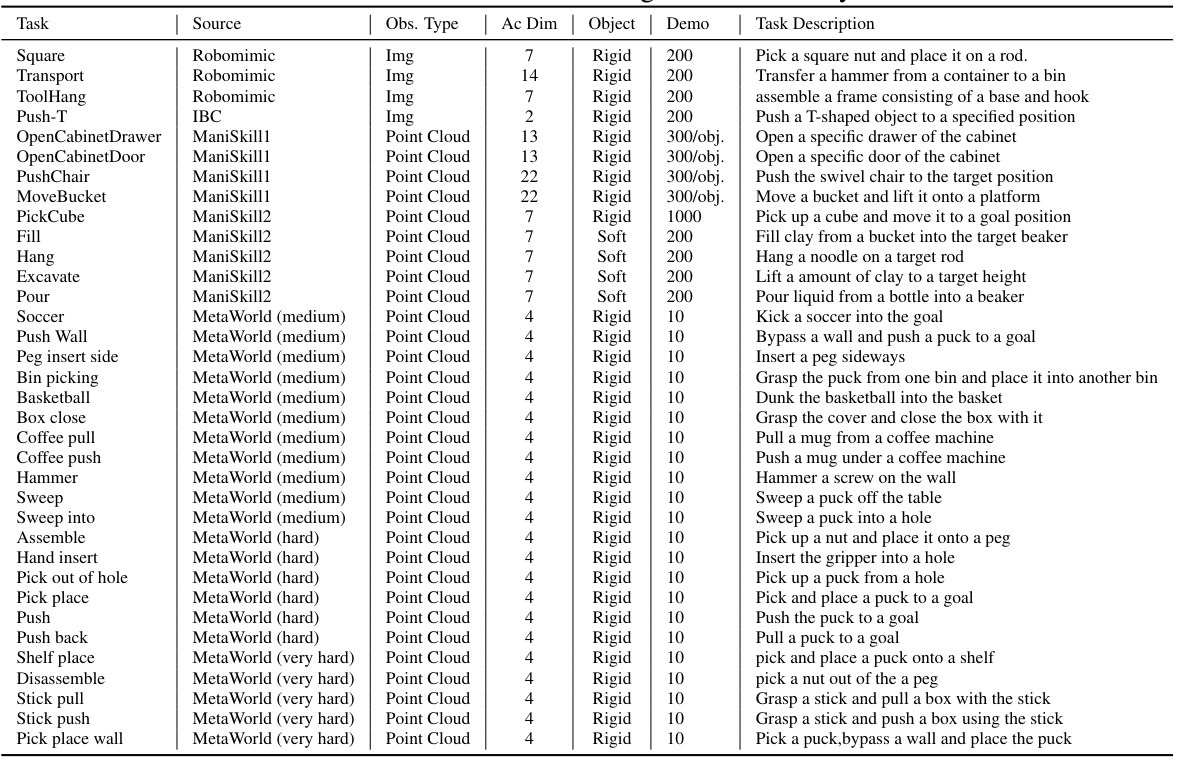
This table presents the success rates of three different methods (DiffTORI, DP3, and Residual + DP3) on 22 MetaWorld tasks, categorized by difficulty level (Medium, Hard, and Very Hard). The higher the success rate, the better the method’s performance. DiffTORI consistently shows equal to or better performance compared to other methods across all tasks. The results showcase DiffTORI’s effectiveness in robotic manipulation tasks.
In-depth insights#
DiffTORI Overview#
DiffTORI presents a novel approach to deep reinforcement and imitation learning by leveraging differentiable trajectory optimization. Instead of using traditional neural network policies, DiffTORI employs trajectory optimization as its policy representation, where the policy’s parameters directly define the cost and dynamics functions within the optimization process. This allows for end-to-end learning, enabling the model to directly learn cost and dynamics functions that maximize task performance. The differentiability of the optimization process is crucial, allowing for the computation of gradients of the loss function with respect to the policy parameters, thus enabling efficient backpropagation and optimization. This addresses the ‘objective mismatch’ problem, frequently observed in model-based RL, where training performance does not directly translate to task performance. By optimizing the cost and dynamics functions to directly improve task performance, DiffTORI shows promise in high-dimensional robotic manipulation tasks and surpasses current state-of-the-art methods in both reinforcement learning and imitation learning settings.
Model-Based RL#
Model-based reinforcement learning (RL) approaches learn a model of the environment’s dynamics to make predictions about future states given current actions. This learned model is then used to plan optimal actions via methods like tree search, or trajectory optimization. A key advantage is improved sample efficiency compared to model-free RL, since the model allows for simulated experience, reducing the need for costly real-world interactions. However, model accuracy is crucial, and inaccuracies in the learned model can lead to suboptimal or even unsafe behavior. Objective mismatch, where the model optimizes a different objective than the true reward, is a common problem. Model-based RL also introduces additional complexity in designing, training and debugging the model itself. Addressing these challenges, including methods to improve model accuracy and address objective mismatch, are active areas of research and crucial for achieving robust and efficient RL systems.
Imitation Learning#
The provided text focuses on DiffTORI’s application in imitation learning, highlighting its capacity to learn cost functions directly through differentiable trajectory optimization. This approach contrasts sharply with prior methods which often use explicit or implicit policies, sometimes suffering from training instabilities. DiffTORI’s test-time optimization, using the learned cost function, proves effective. The paper showcases DiffTORI’s superior performance on various robotic manipulation tasks, particularly those with high-dimensional sensory inputs. The use of conditional variational autoencoders (CVAEs) is particularly notable, enabling DiffTORI to handle multimodal action distributions effectively. This is a significant improvement, especially considering the challenges posed by training instability frequently seen in alternative approaches. The results demonstrate the efficacy of combining differentiable trajectory optimization and deep model-based RL techniques for enhanced imitation learning capabilities. Overall, the paper presents a novel and promising technique that addresses key challenges in imitation learning and achieves state-of-the-art results in several benchmarks.
High-Dim. Sensory Input#
The ability to effectively process high-dimensional sensory input, such as images and point clouds, is a crucial challenge in robotics and AI. This paper’s focus on “High-Dim. Sensory Input” is significant because it directly addresses this challenge, demonstrating the scalability of differentiable trajectory optimization (DTO) methods. The success in handling high-dimensional data is a key contribution, showing that DTO is not limited to low-dimensional state spaces. By using encoders to effectively project high-dimensional observations into lower dimensional latent spaces, the method avoids the curse of dimensionality. This approach allows the model to learn complex relationships within the high-dimensional data while maintaining computational tractability. The results on multiple robotic manipulation benchmarks showcase this capability, surpassing the performance of existing state-of-the-art model-based RL and imitation learning algorithms. The robustness of DTO when applied to such diverse data types suggests significant potential for real-world applications where high-fidelity sensors are prevalent.
Future Work#
Future research directions stemming from this work on DiffTORI could explore several promising avenues. Extending DiffTORI to handle more complex robotic tasks involving intricate manipulation, multi-agent interactions, or long-horizon planning would significantly broaden its applicability and demonstrate its robustness in real-world scenarios. Improving the computational efficiency of the differentiable trajectory optimization process is crucial for real-time applications. Investigating alternative optimization algorithms or hardware acceleration techniques could significantly speed up the process. Investigating the theoretical properties of DiffTORI, such as convergence guarantees and sample complexity under different assumptions, would strengthen the understanding of its capabilities and limitations. A deeper dive into the relationship between the learned cost function and the task reward is also warranted. This could involve exploring methods for automatically shaping rewards or learning cost functions directly from human demonstrations. Finally, applying DiffTORI to other domains beyond robotics and control, such as autonomous driving, video game playing, or even protein folding, could uncover its wider potential and highlight its versatility as a general-purpose policy representation.
More visual insights#
More on figures
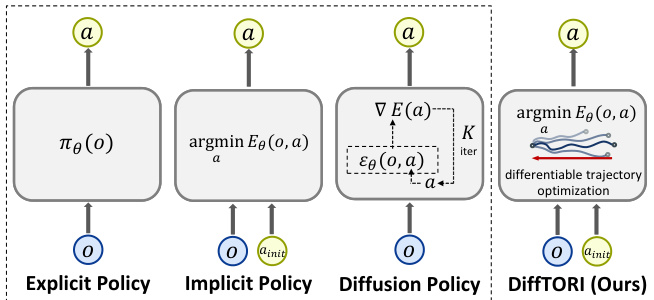
This figure compares different policy architectures for deep imitation learning. Explicit policies directly map observations to actions using a feedforward network. Implicit policies, like EBMs, learn an energy function; actions are obtained by minimizing this function at test time. Diffusion policies generate actions by iteratively refining noise through a diffusion process. DiffTORI differs by learning a cost function through differentiable trajectory optimization. Actions are generated at test time by optimizing this learned cost function, offering a different training process with reported stability advantages.
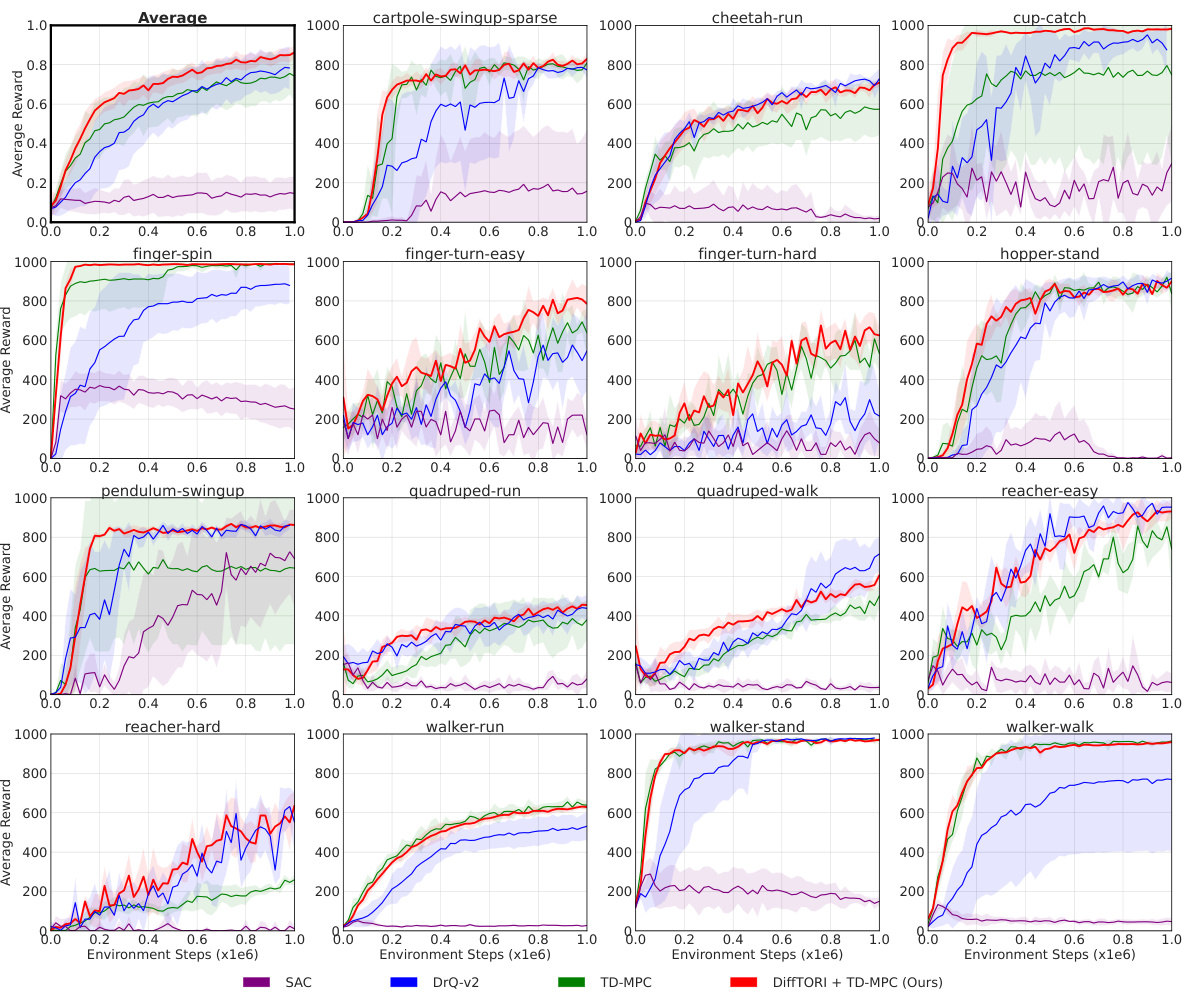
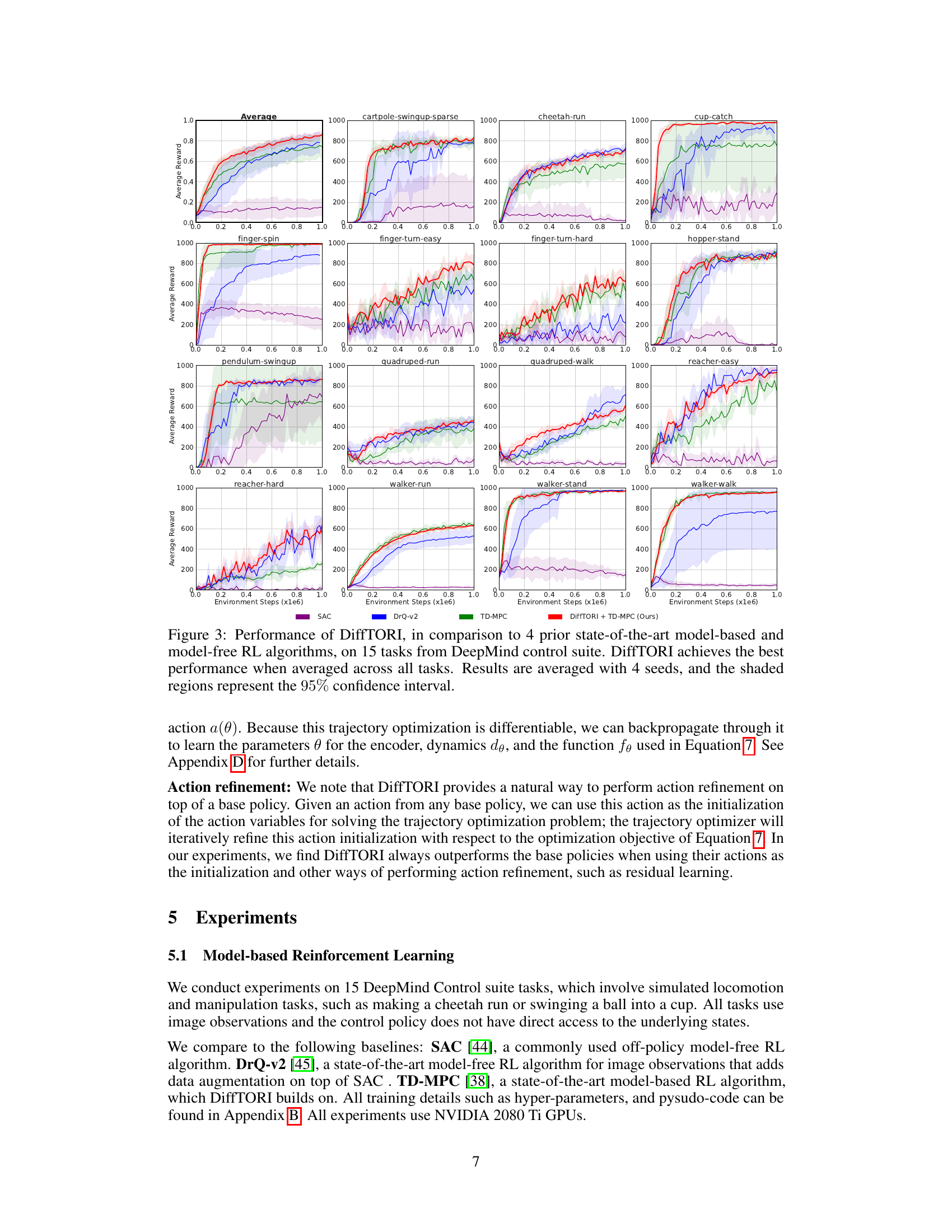
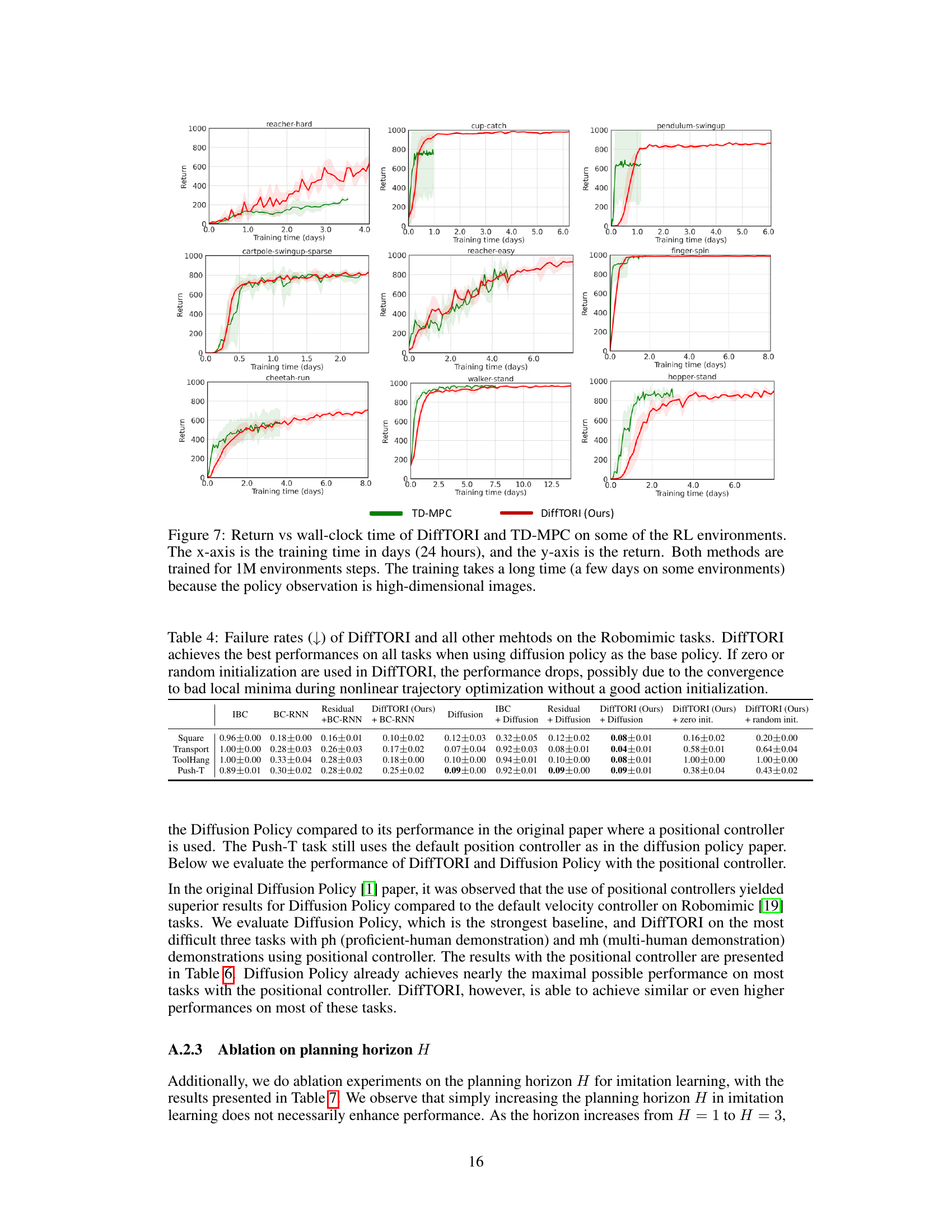
This figure shows the learning curves of different reinforcement learning algorithms across 15 tasks from the DeepMind Control Suite. The algorithms compared are SAC, DrQ-v2, TD-MPC, and DiffTORI. The y-axis represents the average reward achieved, and the x-axis shows the number of environment steps. The shaded areas around the lines indicate 95% confidence intervals. The figure demonstrates that DiffTORI significantly outperforms the other algorithms across most tasks.

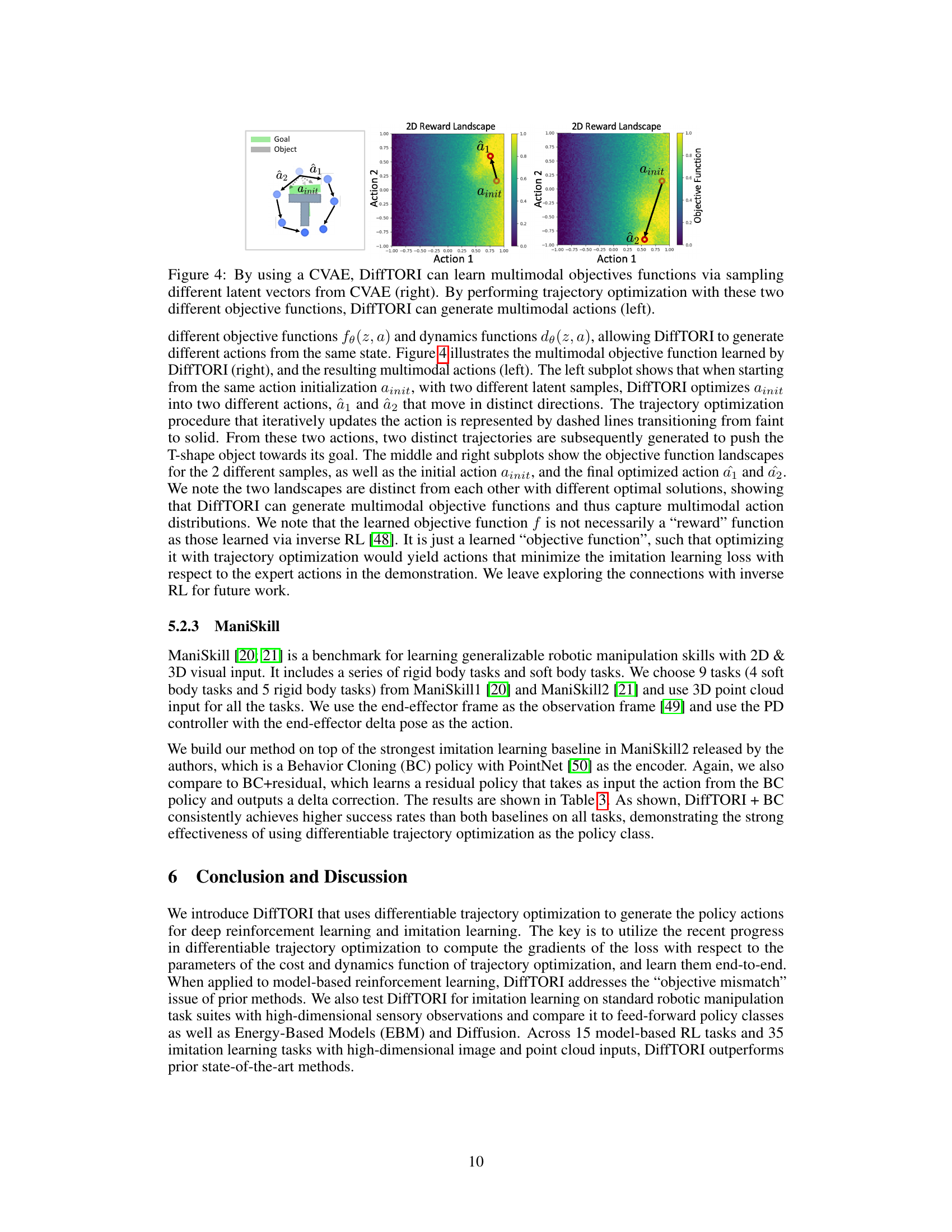
This figure demonstrates the ability of DiffTORI, when using a Conditional Variational Autoencoder (CVAE), to learn multimodal objective functions and generate corresponding multimodal actions. The left subplot shows how, starting from the same initial action, DiffTORI produces two different actions (a1 and a2) depending on the sampled latent vector from the CVAE. The middle and right subplots illustrate the distinct objective function landscapes associated with these different latent samples, highlighting how the optimization process leads to different optimal actions. This showcases DiffTORI’s capacity to handle complex scenarios with multiple possible solutions, reflecting a key advantage over methods that only learn unimodal policies.
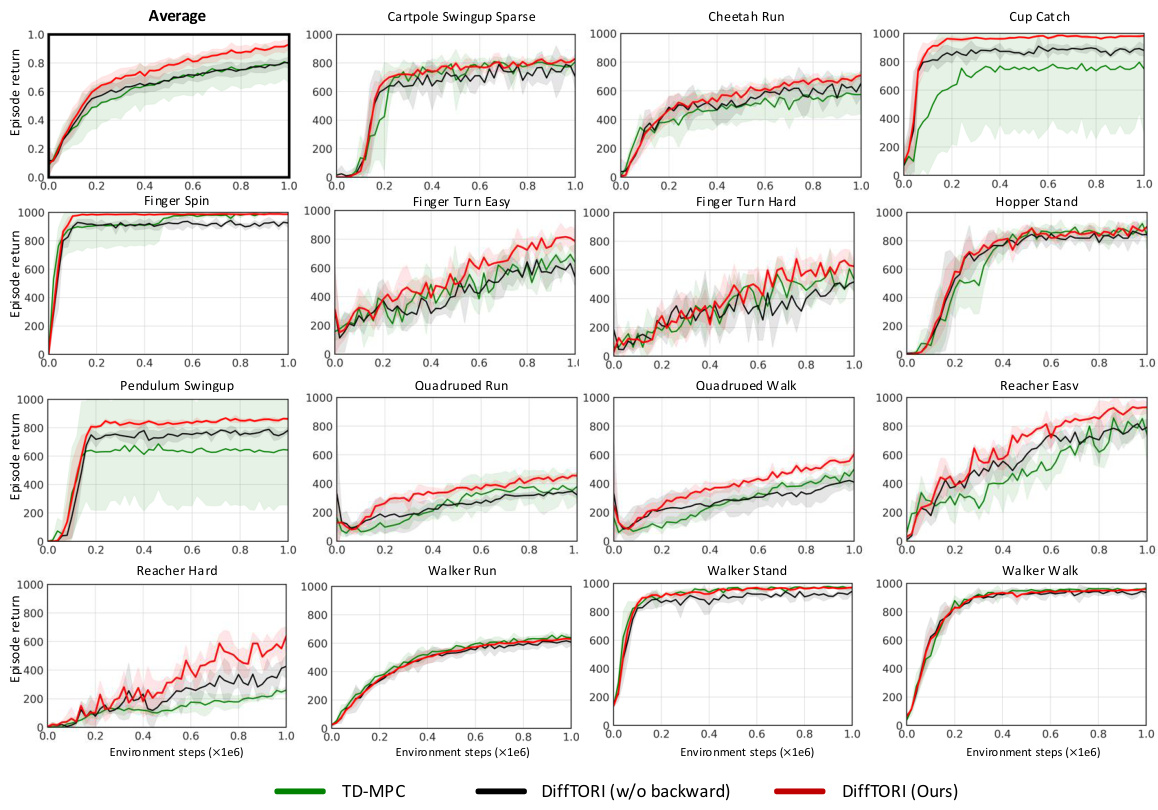
This figure compares the performance of DiffTORI with four other state-of-the-art reinforcement learning algorithms across 15 tasks from the DeepMind Control Suite. Each subplot shows the average reward over time for a specific task. The shaded area represents the 95% confidence interval, illustrating the variability in performance across multiple runs. The figure demonstrates that DiffTORI outperforms all other algorithms in most of the tasks, achieving the best overall average performance.
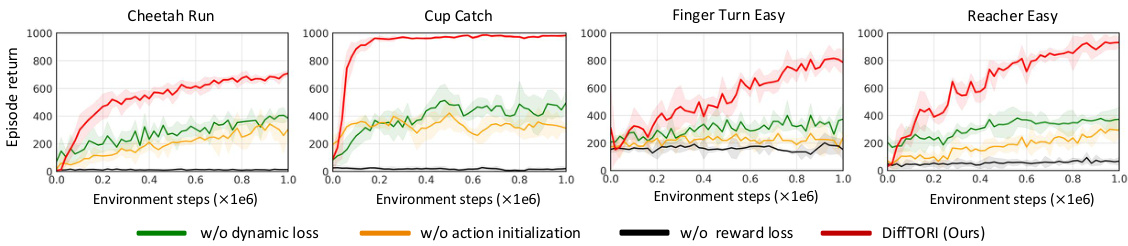
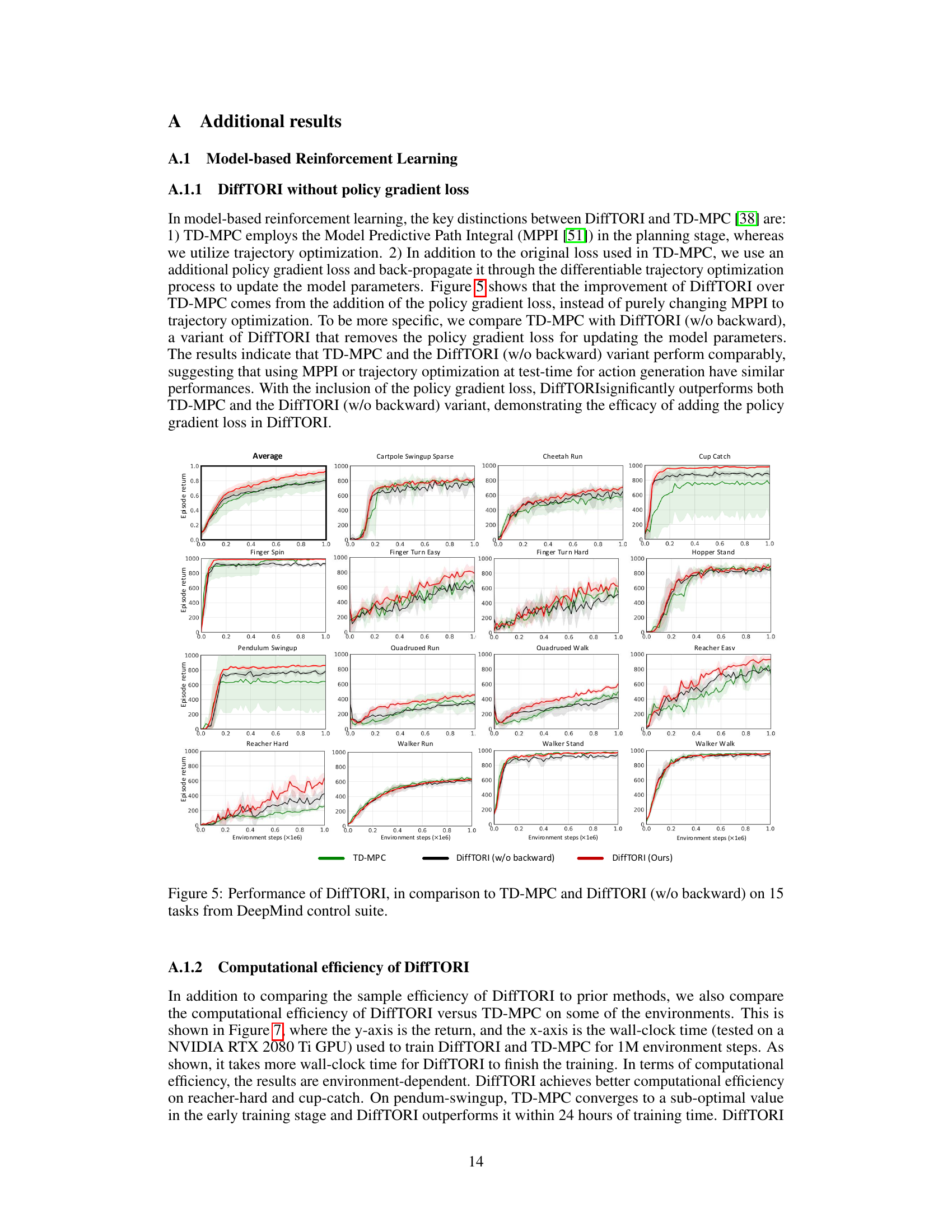
This ablation study analyzes the impact of removing individual loss terms from the DiffTORI objective function on four DeepMind Control Suite tasks. The results demonstrate the importance of all three loss components (reward prediction, action initialization, and dynamics prediction) for achieving strong performance. Removing any one of these terms significantly degrades performance, indicating the critical role each term plays in the overall effectiveness of the algorithm.
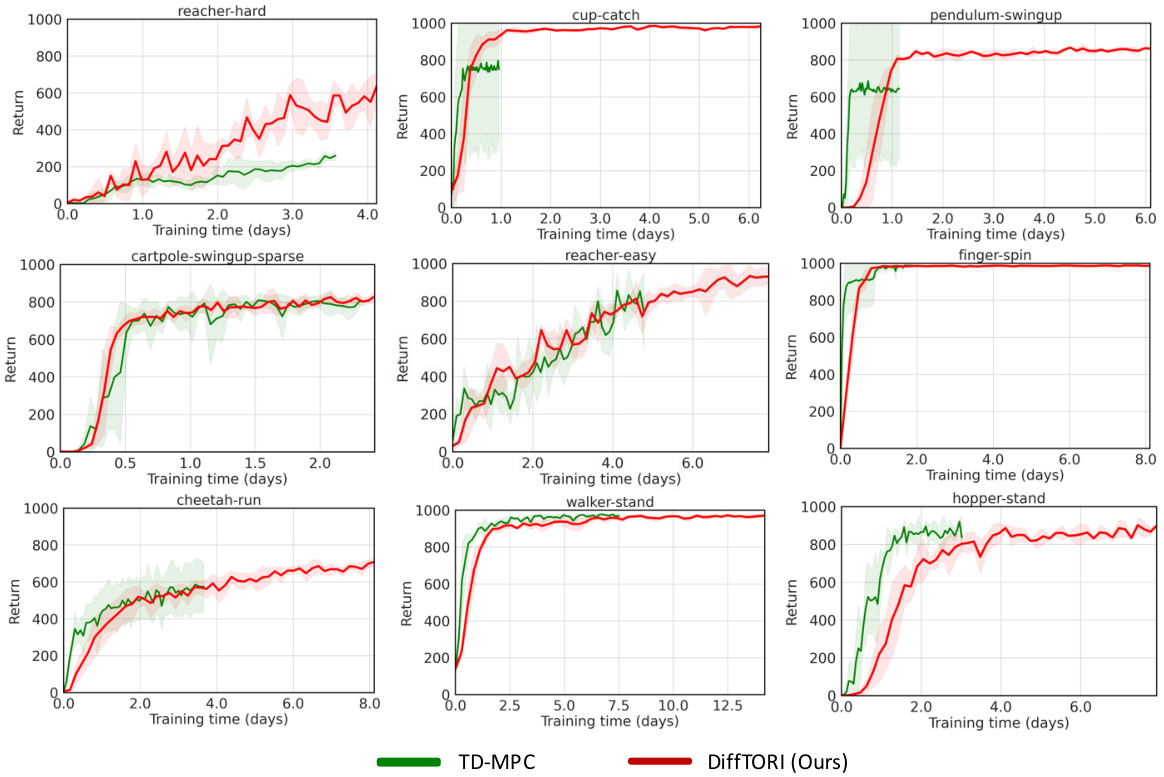
This figure compares the performance of DiffTORI against four other state-of-the-art reinforcement learning algorithms across fifteen tasks from the DeepMind Control Suite. The y-axis represents the average reward achieved, and the x-axis shows the number of environment steps. Shaded areas represent the 95% confidence interval, indicating the variability in performance across multiple trials. The results show that DiffTORI consistently outperforms the other algorithms, demonstrating its superior performance in model-based reinforcement learning.

This figure visualizes keyframes from several imitation learning tasks within the RoboMimic and ManiSkill datasets. It shows a sequence of images for each task, illustrating the robot’s actions and the changes in the environment’s state as the task progresses. The figure provides a visual representation of the complexity and diversity of the tasks used to evaluate the DiffTORI method for imitation learning.

This figure visualizes the keyframes of 22 robotic manipulation tasks from the MetaWorld benchmark used for imitation learning evaluation. Each task shows a sequence of images depicting the robot’s interaction with the objects, showcasing the complexity and diversity of the tasks.
More on tables

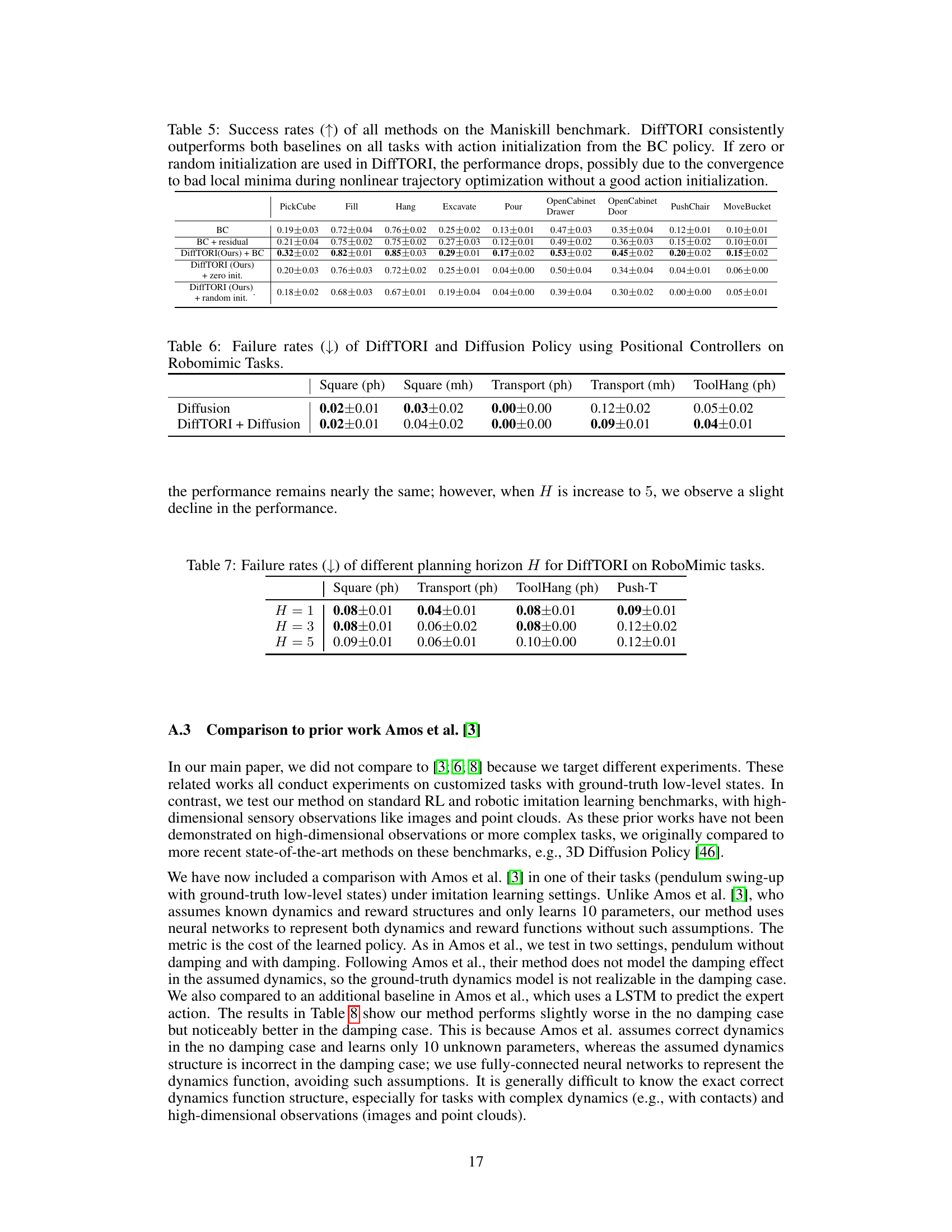
This table compares the failure rates of different imitation learning methods on four Robomimic tasks: Square, Transport, ToolHang, and Push-T. The failure rate is the percentage of trials where the robot fails to complete the task successfully. The table shows that DiffTORI consistently outperforms other methods, achieving the lowest failure rates across all tasks when using a diffusion policy as the base policy. Different variants of DiffTORI and other baselines (including IBC, BC-RNN, and residual methods with various base policies) are compared. The results highlight DiffTORI’s superior performance in robustly completing the tasks.

This table presents the success rates achieved by different methods on various ManiSkill tasks. The methods compared include a baseline Behavior Cloning (BC) approach, BC with residual learning, and DiffTORI combined with BC. DiffTORI consistently outperforms the other methods across all tasks, highlighting its effectiveness in improving the success rates of a baseline policy.

This table presents the failure rates of different imitation learning methods on the Robomimic benchmark. The methods compared include IBC, BC-RNN, Residual + BC-RNN, DiffTORI + BC-RNN, IBC + Diffusion, Residual + Diffusion, DiffTORI + Diffusion, DiffTORI + zero init., and DiffTORI + random init. The results show that DiffTORI consistently achieves the lowest failure rates across all tasks when using the Diffusion policy as the base policy. The table also shows that initializing the DiffTORI model with zero or random actions significantly increases its failure rate.

This table presents the success rates achieved by different methods on various tasks within the ManiSkill benchmark. The methods compared include a baseline Behavior Cloning (BC) method, a BC approach with residual learning, and the proposed DiffTORI method with and without different initialization strategies for its action. DiffTORI consistently demonstrates superior performance.

This table compares the failure rates of DiffTORI and Diffusion Policy when using positional controllers on three Robomimic tasks (Square, Transport, and ToolHang). It shows the failure rates for both policies using proficient human demonstrations (ph) and mixed human demonstrations (mh). The lower the failure rate, the better the performance. This table helps demonstrate DiffTORI’s improved performance compared to the base Diffusion Policy, even when using the same positional controller.

This table presents the failure rates of different imitation learning methods on the Robomimic benchmark. The methods compared include IBC, BC-RNN, Residual + BC-RNN, Diffusion Policy, IBC + Diffusion, Residual + Diffusion, and two variants of DiffTORI (DiffTORI + BC-RNN and DiffTORI + Diffusion). The results demonstrate that DiffTORI consistently achieves the lowest failure rates across all tasks when using the diffusion policy as the base policy. This highlights DiffTORI’s effectiveness in improving upon baseline policies for imitation learning.

This table compares the performance of different algorithms on a pendulum swing-up task, a common benchmark in reinforcement learning. The task is tested in two conditions: with and without damping. The table shows the cost achieved by each method, with lower cost indicating better performance. The results demonstrate that the proposed method, DiffTORI, shows a performance improvement in the more challenging scenario with damping.
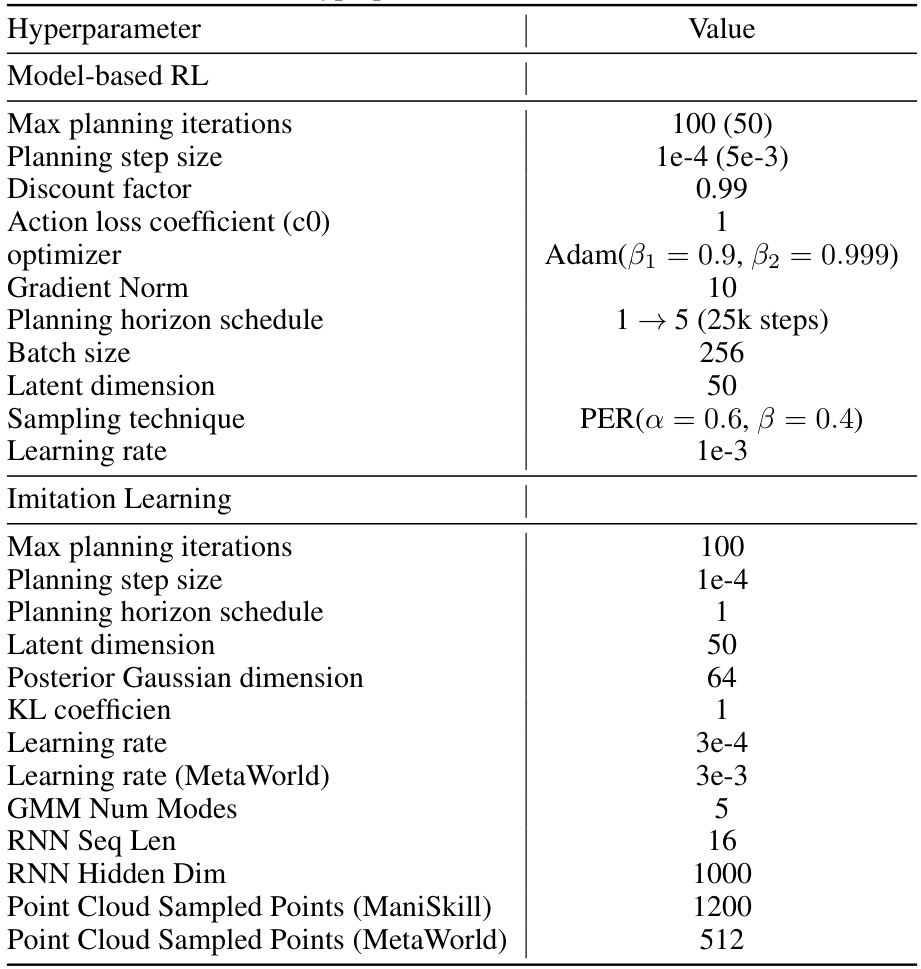
This table lists the hyperparameters used in the DiffTORI model for both model-based reinforcement learning and imitation learning experiments. For model-based RL, many parameters are shared with or similar to those used in the TD-MPC baseline. Imitation learning uses a different set of hyperparameters adjusted for that task. The table specifies the value for each hyperparameter, with some values indicating a range or schedule of changes during training.
This table presents the success rates of three different methods (DiffTORI, DP3, and Residual + DP3) on 22 tasks from the MetaWorld benchmark. The success rate represents the percentage of successful task completions. The table shows that DiffTORI consistently outperforms or matches the performance of the other two methods across all 22 tasks, highlighting its effectiveness in robotic manipulation tasks.
Full paper#