↗ OpenReview ↗ NeurIPS Proc. ↗ Hugging Face ↗ Chat
TL;DR#
Current world models often simplify environment dynamics by representing them using discrete latent variables. This simplification can lead to a loss of crucial information, especially visual details, which are vital for effective reinforcement learning. The limited expressiveness of such models restricts the applications of world models in various fields.
To address these issues, this paper introduces DIAMOND, a reinforcement learning agent that uses a diffusion model as its world model. This approach allows the agent to capture fine-grained visual information, resulting in significantly improved performance compared to existing state-of-the-art world models on the Atari 100k benchmark. Furthermore, the diffusion model is shown to be effective as an independent interactive game engine, opening doors to new applications and research.
Key Takeaways#
Why does it matter?#
This paper is significant because it demonstrates the potential of diffusion models for world modeling, outperforming existing methods on a benchmark task. It opens new avenues for research in sample-efficient reinforcement learning and generative models for interactive game engines. The release of code and models fosters further research and applications.
Visual Insights#
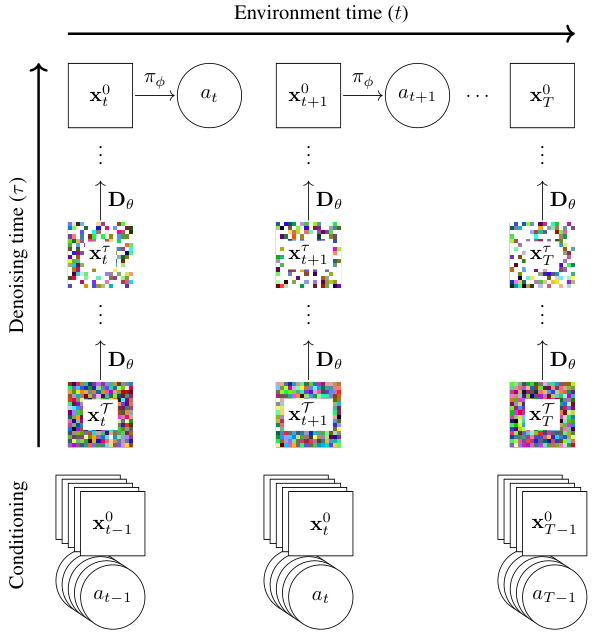
This figure illustrates the process of imagination in the DIAMOND model. The top row shows a policy making decisions (actions) in the simulated world. Each action produces a noisy observation, which is then denoised using the diffusion model (bottom rows). The denoising process happens in reverse time, from a highly noisy observation back to a clean one. The denoised observation and action become the input for the next step, making it autoregressive and more realistic. The animation can be viewed at the provided link.
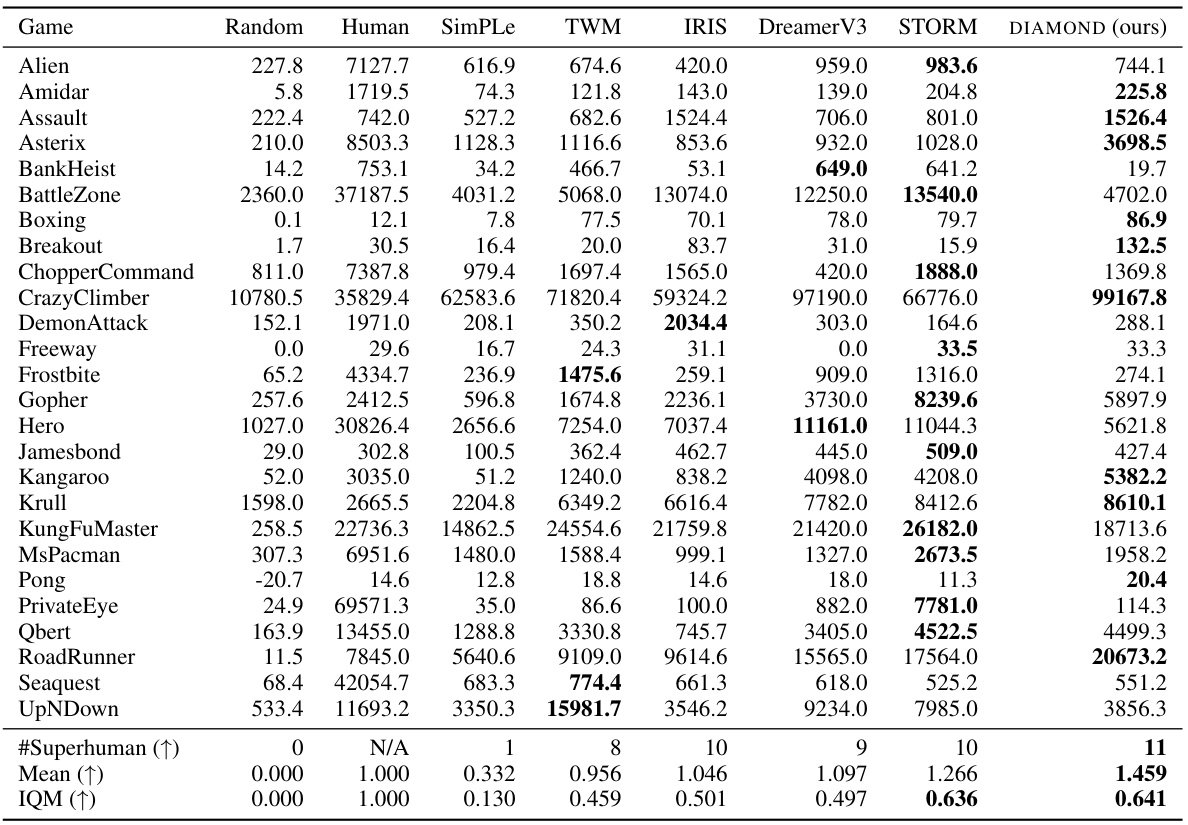
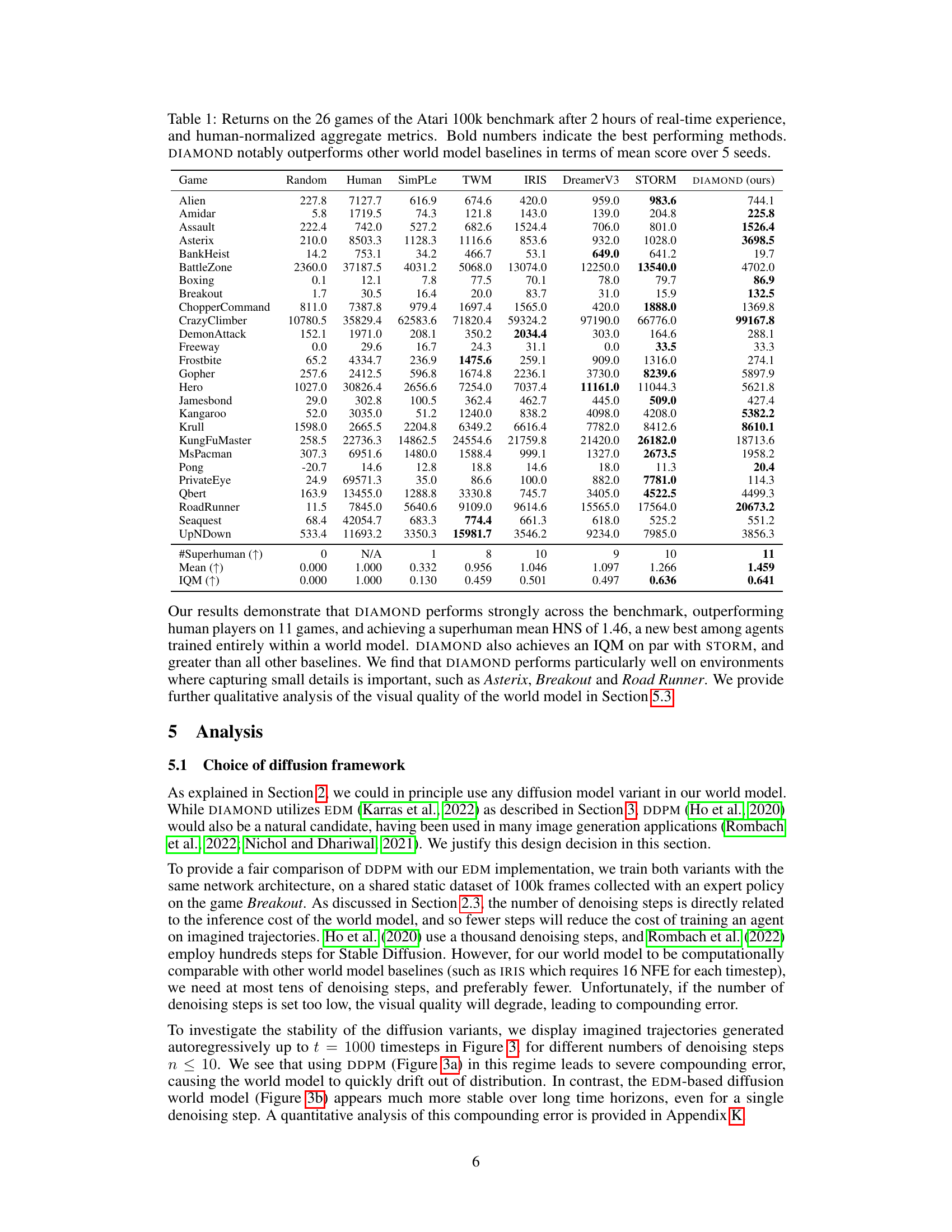
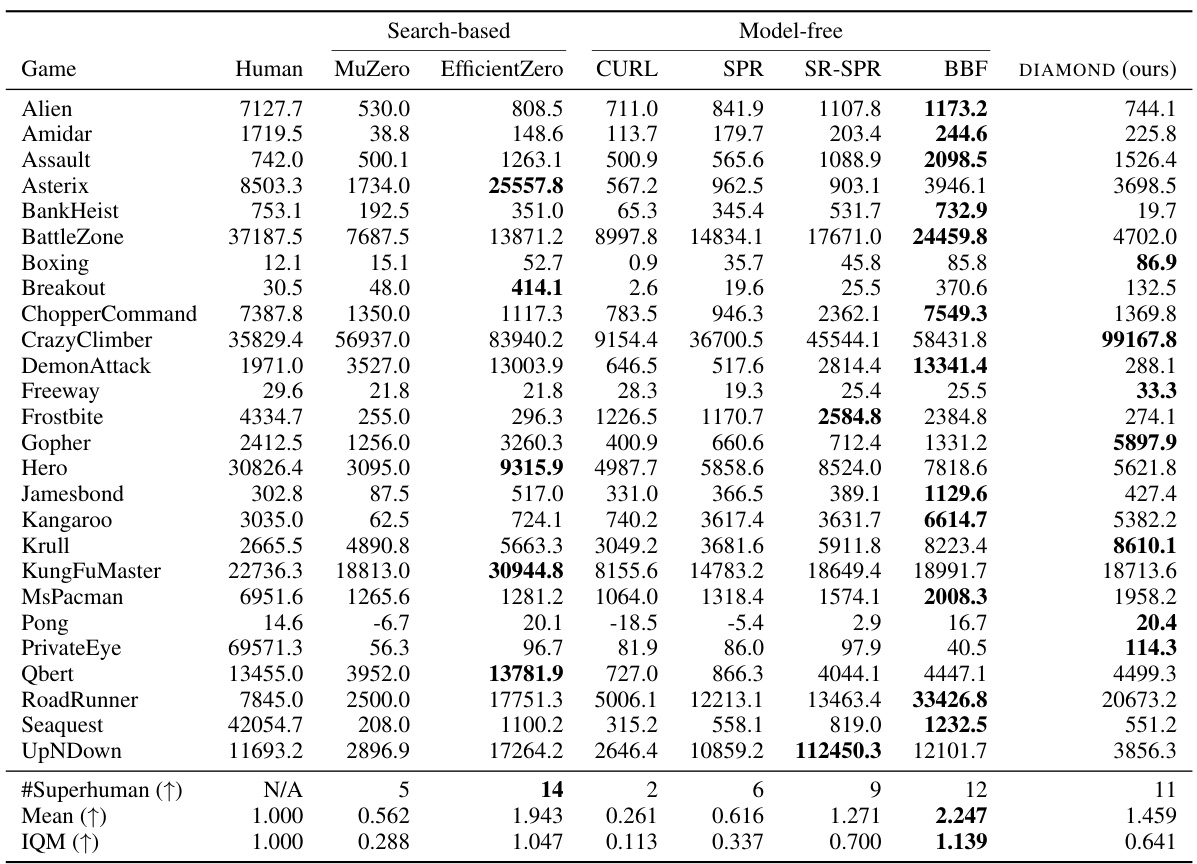
This table presents the performance of various world models on the Atari 100k benchmark after only 2 hours of real-world experience. It compares the scores achieved by different models on each of the 26 games in the benchmark, showing raw scores and human-normalized scores (HNS). Bold numbers highlight the best-performing model for each game. The table provides a comprehensive comparison across different algorithms, showcasing the relative strengths and weaknesses of each model in mastering various Atari games with limited experience.
In-depth insights#
Visual Detail’s Role#
The role of visual detail in world modeling is critical for achieving high performance in reinforcement learning. While previous world models often relied on compressed, discrete latent representations, ignoring fine-grained visual information, this work highlights the importance of maintaining visual fidelity using a diffusion model. The improved visual detail leads to more reliable credit assignment, enabling the agent to learn more effectively from its experiences within the simulated environment. This is particularly apparent in games where subtle visual cues significantly impact gameplay, demonstrating that high-resolution, continuous visual representations provide a substantial advantage over their discrete counterparts. This approach enhances the model’s capacity for generalization and allows for a greater degree of interaction between the world model and the RL agent, ultimately leading to significantly improved performance as demonstrated in the experiments.
Diffusion World Model#
The concept of a ‘Diffusion World Model’ presents a novel approach to world modeling in reinforcement learning by leveraging the power of diffusion models. Instead of relying on discrete latent representations that can lose crucial visual details, this approach uses diffusion models to generate continuous image representations directly. This allows the agent to learn from and interact with a more visually rich and detailed simulation of its environment. A key advantage is the potential for improved sample efficiency and enhanced generalization by preserving visual nuances vital for effective decision-making. However, challenges remain in effectively conditioning diffusion models on long action sequences and maintaining computational efficiency. The success of this method hinges on addressing these challenges, making it a promising but still developing area of research in AI.
Atari Benchmark#
The Atari benchmark is a crucial element in evaluating reinforcement learning (RL) agents. Its use allows for a standardized comparison of various RL approaches, particularly in assessing sample efficiency and overall performance. The benchmark’s inherent complexity and diversity of games present a robust testbed for assessing generalization capabilities. The limited data constraint (100k actions) of the benchmark is particularly relevant, as it favors algorithms that can effectively learn from limited experiences. This focus on sample efficiency is a significant aspect, as real-world applications often require learning with minimal interactions. While the 26 games in the Atari suite provide a diverse set of challenges, there are limitations. The games’ inherent structure may not perfectly reflect real-world problem domains. Nevertheless, the Atari benchmark continues to serve as a significant evaluation metric in the RL field, prompting advancements in sample-efficient and generalizable RL algorithms. Its continued use ensures comparability and facilitates progress in the field.
CSGO Game Engine#
The research demonstrates a significant advancement in creating interactive game engines using diffusion models. By training a diffusion model on a massive dataset of Counter-Strike: Global Offensive (CS:GO) gameplay, the authors successfully generate realistic and coherent game environments. This approach surpasses traditional methods by producing higher-fidelity visuals and more stable, longer trajectories. The resulting CS:GO game engine is playable, showcasing the model’s ability to generate realistic game states, character actions, and environmental dynamics. The success here highlights the potential of diffusion models in creating more realistic and interactive virtual environments for gaming and other applications. However, challenges remain, particularly in terms of handling unseen game states, memory limitations and addressing compounding errors over long time horizons. Further research could investigate memory mechanisms and other model architectures to enhance the engine’s ability to maintain a consistent and coherent virtual world.
Future Directions#
Future research should prioritize extending DIAMOND’s capabilities to handle continuous control environments and improve the model’s long-term memory. Addressing these limitations could involve exploring more sophisticated memory mechanisms, such as autoregressive transformers over environment time. Furthermore, integrating reward and termination prediction directly into the diffusion model warrants investigation, potentially streamlining the learning process and improving model efficiency. Finally, scaling the model to even more complex environments presents a significant challenge and opportunity. Exploring techniques for efficient model scaling, such as decomposition methods, and rigorous evaluation on diverse, realistic benchmarks will be crucial for establishing DIAMOND’s broader impact and applicability.
More visual insights#
More on figures
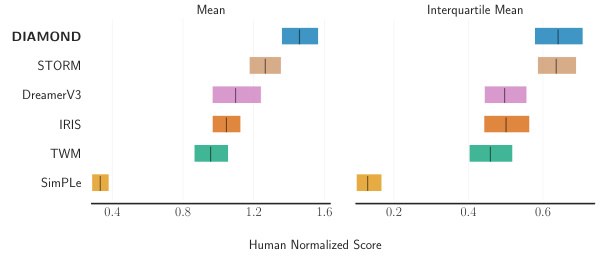
This figure compares the performance of DIAMOND against other world models on the Atari 100k benchmark. The x-axis represents the human-normalized score (HNS), which measures the performance relative to human players. The y-axis shows the different world models. The blue bars represent DIAMOND, indicating that it achieves a mean HNS of 1.46 and an interquartile mean (IQM) of 0.64, which is superior to other models. The IQM is a measure of central tendency that is less sensitive to outliers than the mean.
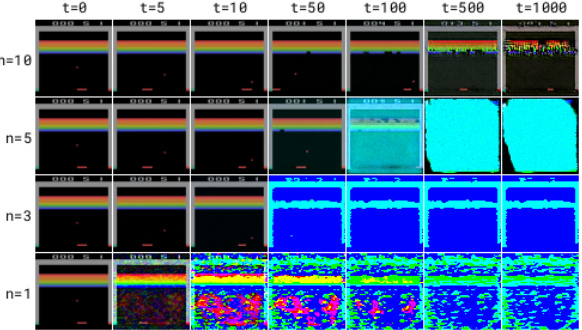
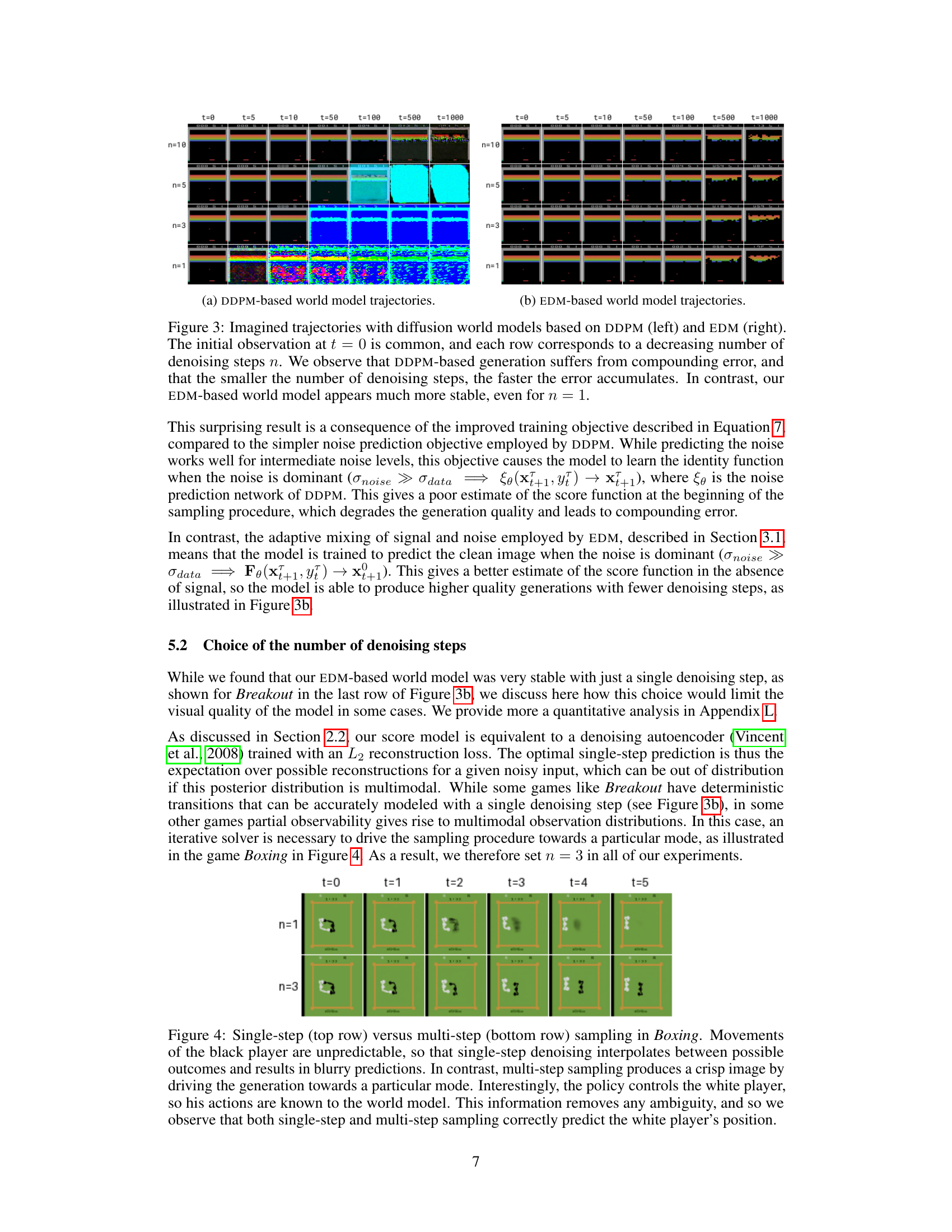
This figure compares the performance of two different diffusion models, DDPM and EDM, in generating imagined trajectories. The top row shows the initial observation which is the same for both models. Each subsequent row shows the result of increasing the number of denoising steps, from n=1 to n=10. As the number of denoising steps increases, the generated image becomes progressively more realistic and less noisy. However, this improvement is much more pronounced in EDM compared to DDPM. Specifically, it is observed that DDPM produces highly unstable and unrealistic trajectories when fewer denoising steps are used, while EDM is much more stable, even with a single denoising step.
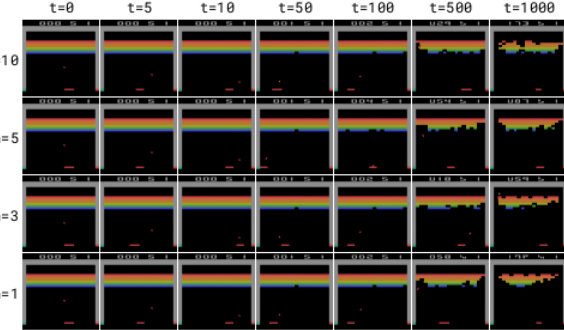
This figure compares the performance of two different diffusion models (DDPM and EDM) used for generating trajectories in a world model. Each row shows trajectories generated with a different number of denoising steps (n). The left column uses DDPM, which shows significant compounding error, especially with fewer denoising steps. The right column uses EDM, which is much more stable even with only one denoising step. This highlights EDM’s advantage for world modeling applications.
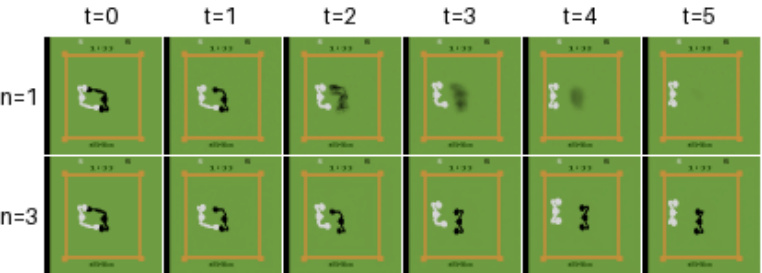
This figure compares single-step and multi-step sampling in the Boxing game, highlighting how single-step sampling results in blurry predictions due to the unpredictable movements of the black player, while multi-step sampling produces clearer images by focusing on specific outcomes. It also demonstrates that when the policy controls the white player (providing full information), both sampling methods accurately predict the player’s position.
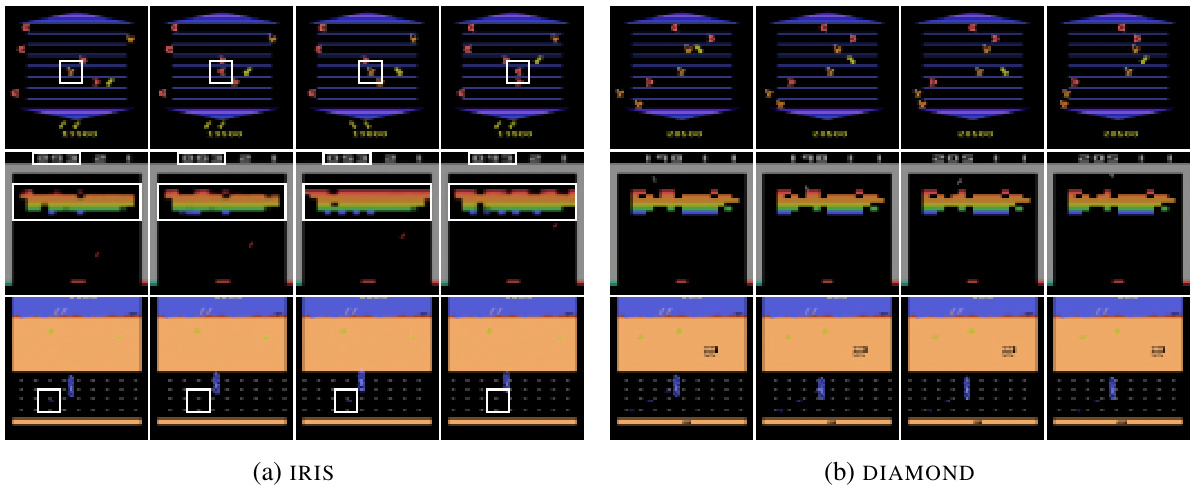
This figure compares the visual quality of imagined game trajectories generated by two different world models, IRIS and DIAMOND. IRIS, using a discrete autoencoder, shows inconsistencies in its generated frames. For example, in Asterix, an enemy is incorrectly displayed as a reward, then back as an enemy, and again as a reward. In Breakout, the bricks and score are not consistent across frames. In Road Runner, the rewards are inaccurately rendered. In contrast, DIAMOND’s diffusion model produces consistent and more accurate visual representations across all three games. This demonstrates DIAMOND’s ability to maintain fidelity to the environment even when generating longer sequences, unlike IRIS.

This figure shows a series of screenshots from a video game created using DIAMOND’s diffusion world model trained on 87 hours of CS:GO gameplay. The screenshots demonstrate the model’s ability to generate realistic and interactive game environments, making it function as a playable game engine. The videos showing the full sequence are available online at the URL provided in the caption.
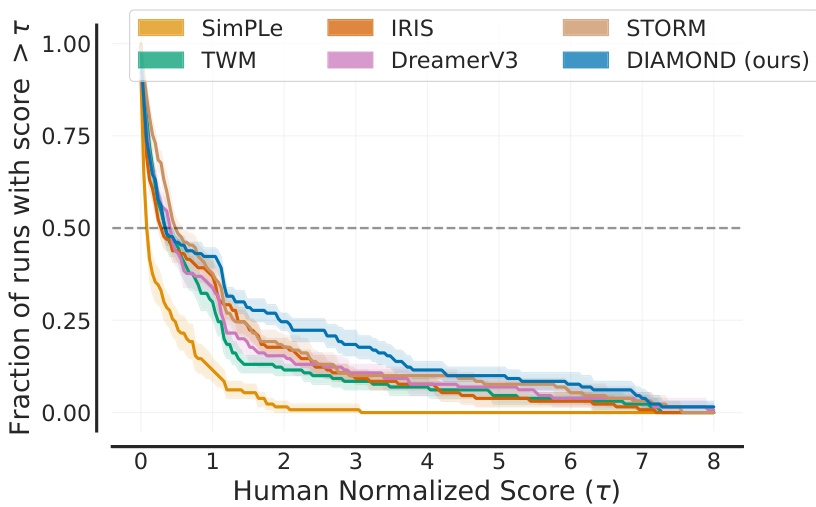
This figure shows performance profiles comparing DIAMOND with several other world models on the Atari 100k benchmark. A performance profile plots the fraction of games where a given method achieved a human-normalized score above a certain threshold (τ) across multiple runs (seeds). The x-axis represents the human normalized score threshold (τ), and the y-axis represents the fraction of runs that exceeded that score. A higher curve indicates better performance. The dashed horizontal line indicates the fraction of runs that exceeds human-level performance (HNS=1).
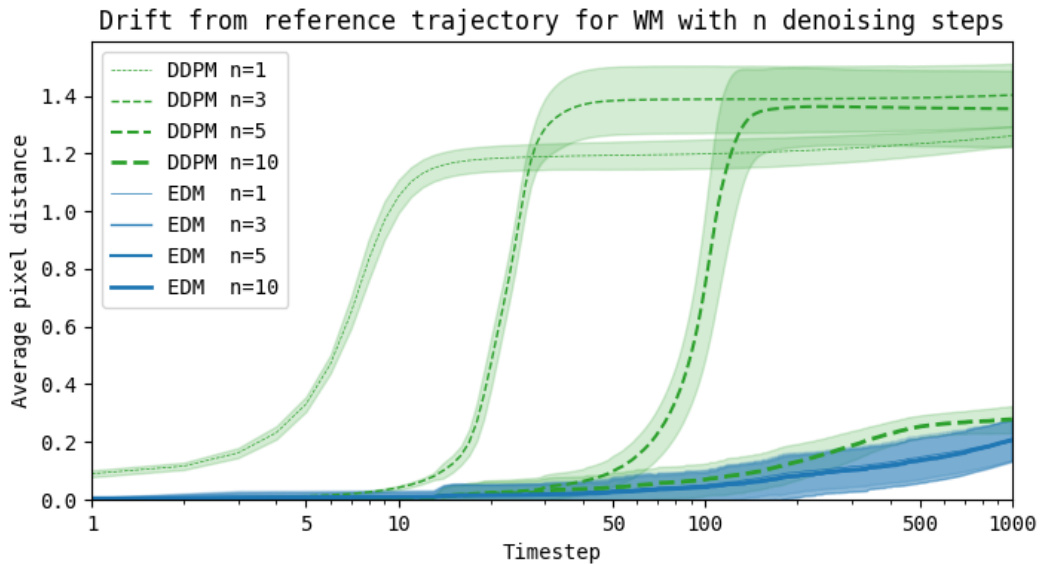
This figure shows a quantitative analysis of the compounding error in autoregressive world models. It compares the average pixel distance between imagined trajectories and reference trajectories (collected from an expert player) in the Breakout game, for both DDPM and EDM-based world models with varying numbers of denoising steps. The results show that EDM models are more stable and have less compounding error than DDPM models, even with a single denoising step.
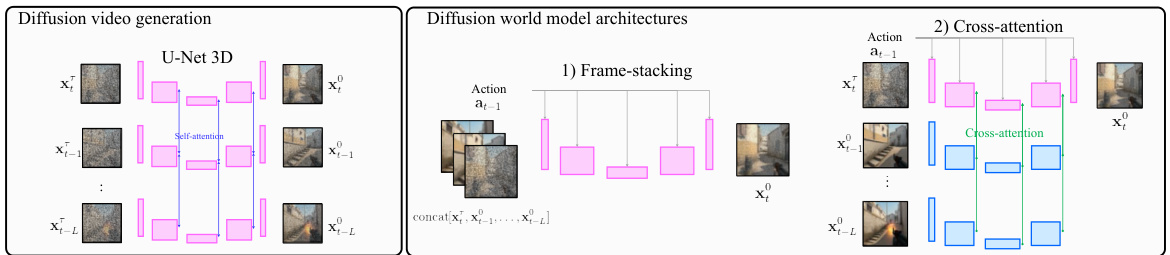
This figure compares three different architectures for diffusion models. The first is a U-Net 3D architecture commonly used in video generation, which processes all frames simultaneously. The other two are variations of U-Net 2D designed for world modeling, one uses frame-stacking, where the previous frames are concatenated to the input, and the other uses cross-attention, a more sophisticated method to consider past frames.

This figure shows example trajectories generated by the DIAMOND model for two different environments: CS:GO and motorway driving. The CS:GO example shows a first-person perspective, navigating a corridor and then going through a doorway. The motorway example depicts a car driving on a highway and plausibly overtaking another car. These examples illustrate the model’s ability to generate plausible and coherent trajectories in complex, visually rich environments. The trajectories are sampled every 25 timesteps.

The figure shows the effect of different actions on the model’s predictions for a motorway driving scenario. The model is given the same initial observations (six previous frames), but different actions are input (continue straight, steer left, steer right, slow down, speed up). The resulting trajectories show that the model is able to generate plausible continuations that correspond to the actions applied. Notably, when ‘slow down’ is applied, the model predicts the traffic ahead slowing down, showing an understanding of the scenario’s dynamics.

This figure shows the effect of applying different actions on the generated trajectories in the CS:GO environment. The model successfully generates the intended effects for short sequences, but for longer sequences it shows some instability and is unable to generate the plausible trajectories, suggesting that the model might not have encountered the similar scenarios in the training data. For example, when looking down, the model shifts to another area of the map instead of realistically showing the ground.
More on tables

This table presents the performance of DIAMOND and other methods on the Atari 100k benchmark. For each of the 26 games, it shows the raw scores achieved after only 2 hours of real-world experience (100,000 actions). It also displays human-normalized scores, which compare agent performance to that of a human player. Bold numbers highlight the top-performing method for each game. This allows for comparison of DIAMOND’s sample efficiency with other world models and provides an overall performance summary.

This table presents the performance of DIAMOND and other methods on the Atari 100k benchmark. For each of the 26 games, it shows the raw scores achieved after only 2 hours of real-world experience (100k actions). The scores are also normalized against human performance, providing human-normalized scores (HNS). The best performing method for each game is highlighted in bold.
This table presents the performance of DIAMOND and several baseline methods on the Atari 100k benchmark. The benchmark consists of 26 Atari games, and each agent is only allowed to train for 2 hours of real-time experience before evaluation. The table shows the raw scores achieved by each agent in each game, along with human-normalized scores (HNS) and aggregated metrics such as the mean and interquartile mean. The bold numbers highlight the best-performing methods for each game. This allows comparison of DIAMOND’s performance with other world model-based RL agents.
This table presents the performance of different reinforcement learning agents on the Atari 100k benchmark. The benchmark consists of 26 Atari games, each with a time limit of 100,000 actions (roughly 2 hours of human gameplay). The table shows the raw scores achieved by each agent on each game, along with human-normalized aggregate scores (mean and interquartile mean). The results illustrate the sample efficiency and overall performance of the agents compared to human performance.
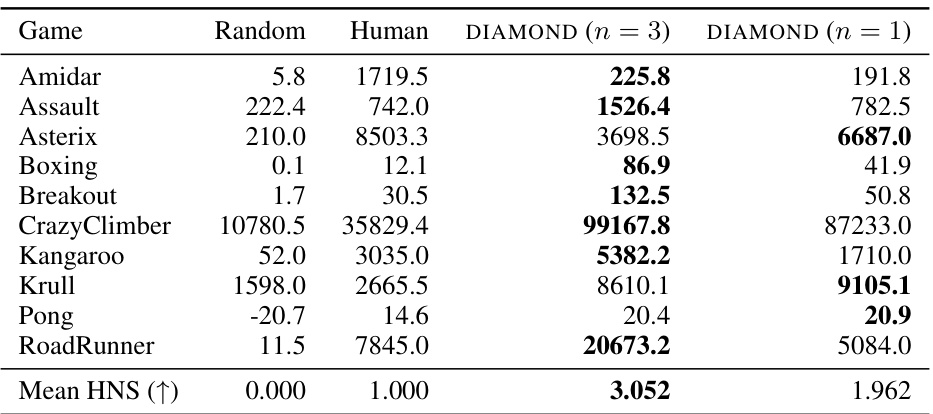
This table presents the results of the DIAMOND model and several baseline models on the Atari 100k benchmark. For each of the 26 games in the benchmark, the table shows the average return achieved by a random agent, a human player, and each of the tested models after a training period of approximately two hours of real-world experience. The results are also presented as a human-normalized score (HNS), which allows for a more meaningful comparison across different games. Bold values indicate the highest performance for each game.

This table presents a comparison of different world models on two 3D environments: CS:GO and Motorway driving. The models are evaluated based on FID, FVD, and LPIPS scores, which measure the visual quality of generated trajectories. The table also includes the sampling rate (observations per second) and the number of parameters for each model. The results show that DIAMOND, particularly the frame-stack version, outperforms the baselines in terms of visual quality, while maintaining a relatively high sampling rate and reasonable parameter count.
Full paper#