↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Procedurally generated environments (PGEs) like Procgen are increasingly used in reinforcement learning, offering diverse and challenging training levels. However, how agents learn across these varying levels remains unclear. Existing research focuses primarily on explicitly designing curricula by arranging level difficulty. This paper investigates the learning process itself in PGEs, specifically focusing on whether an implicit curriculum emerges even without explicit level ordering.
To address this, the researchers created C-Procgen, an enhanced version of Procgen allowing explicit control over environment parameters. Using C-Procgen, they analyzed learning dynamics across different contexts (difficulty levels). They discovered an implicit curriculum, where agents gradually transition from simpler to more complex contexts. This suggests a potential mismatch between the loss and the distribution of samples, indicating inefficient learning from hard contexts in the initial phases. The C-Procgen benchmark is a valuable contribution, enhancing the flexibility and control of Procgen for future research in curriculum reinforcement learning. The insights on implicit curricula can guide the development of more effective training methods for agents in PGE.
Key Takeaways#
Why does it matter?#
This research is crucial because it reveals the presence of an implicit curriculum in multi-level training within procedurally generated environments. This finding challenges existing assumptions in reinforcement learning and opens exciting new avenues for research in curriculum learning and contextual reinforcement learning. The developed benchmark, C-Procgen, is a valuable tool, providing explicit control over environment parameters, thereby facilitating deeper understanding of learning dynamics in complex scenarios.
Visual Insights#
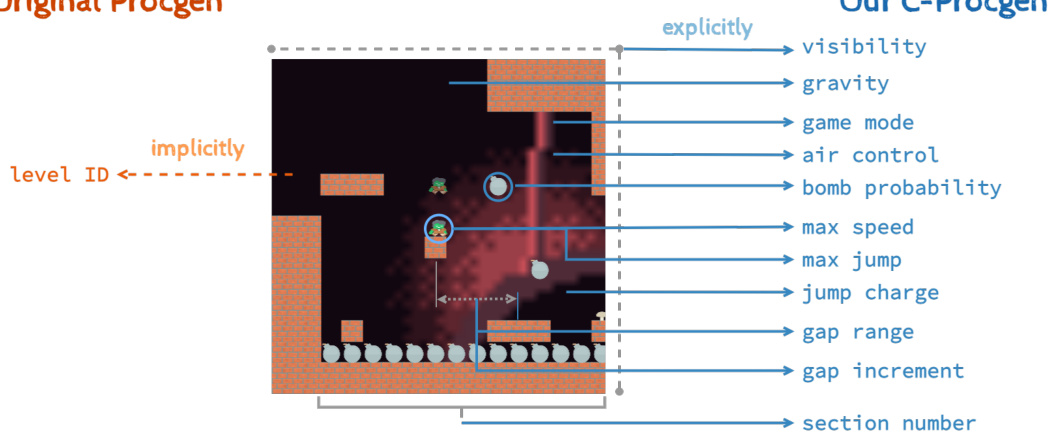
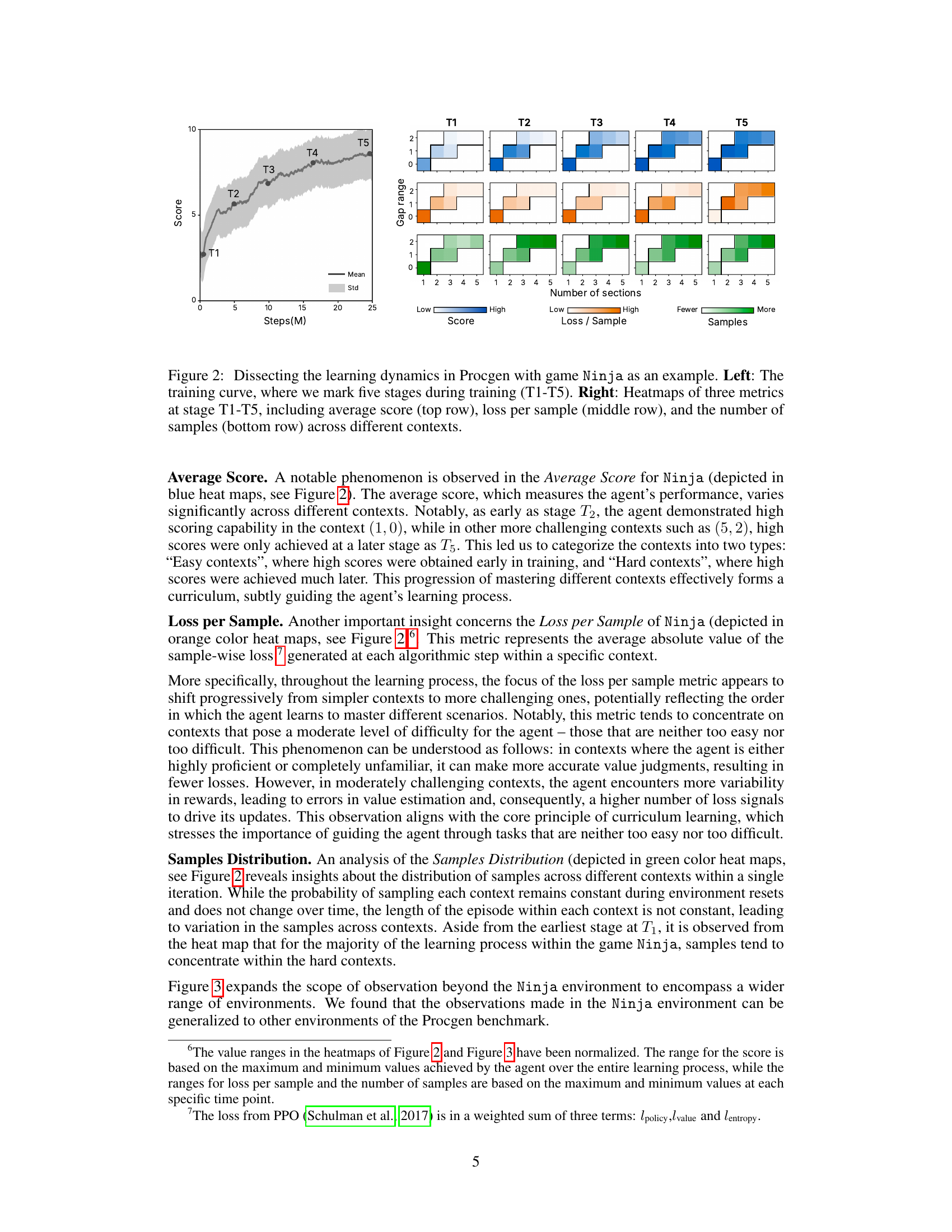
This figure uses a screenshot from a Procgen game to illustrate the difference between the original Procgen and the authors’ proposed C-Procgen. The original Procgen uses a single, implicit level ID to control the generation of game levels (contexts). In contrast, C-Procgen makes numerous parameters that define the game’s context explicitly controllable by the user, giving researchers more granular control over the game environment.
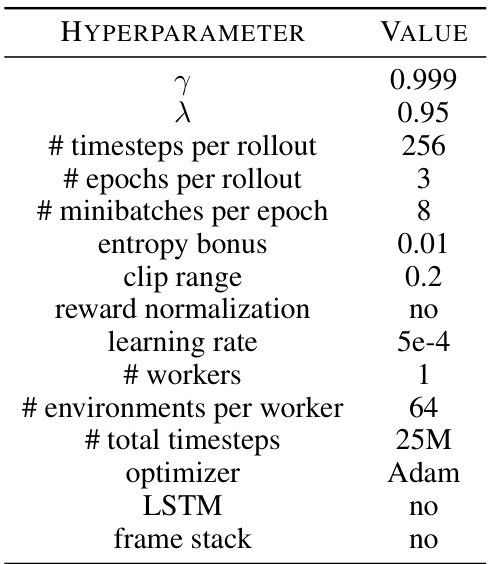
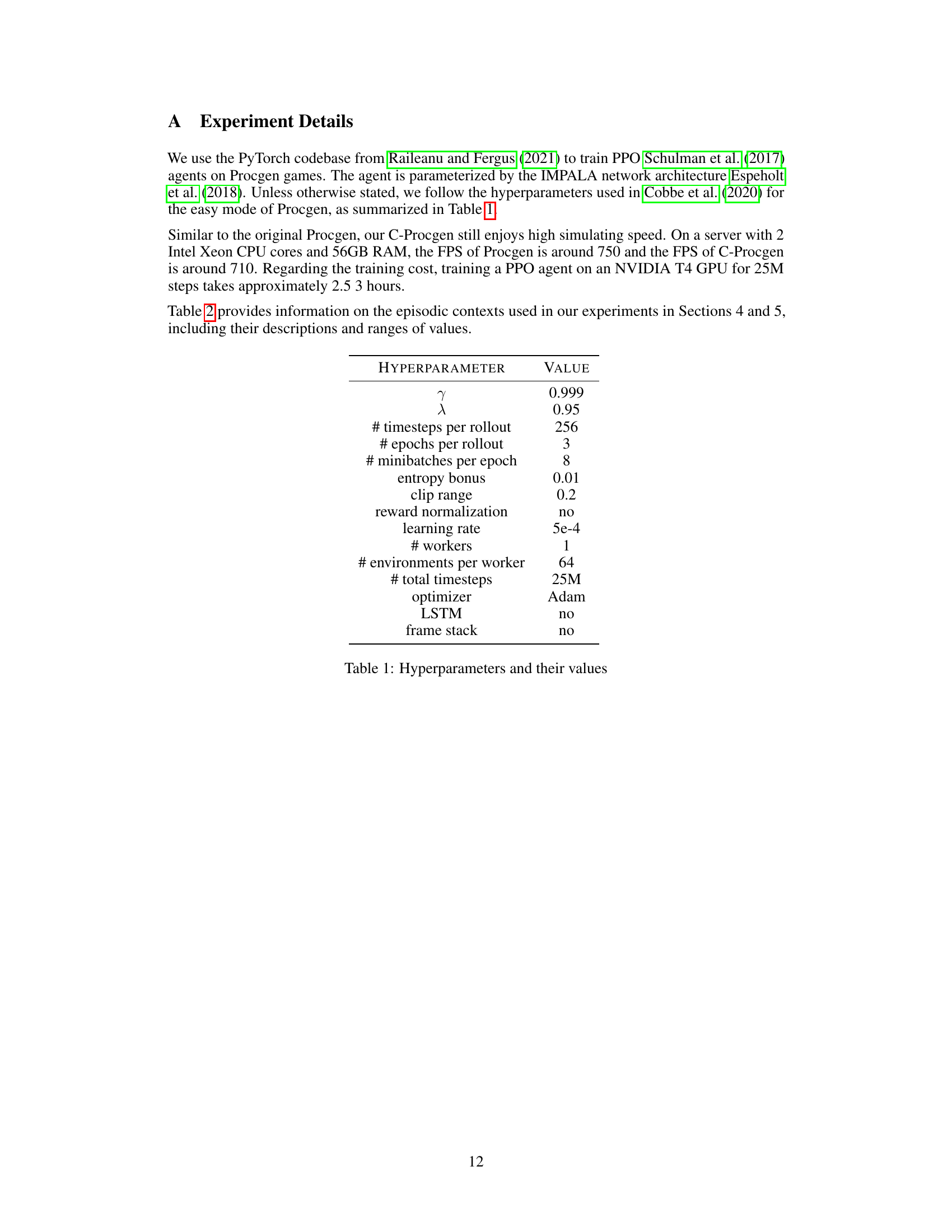
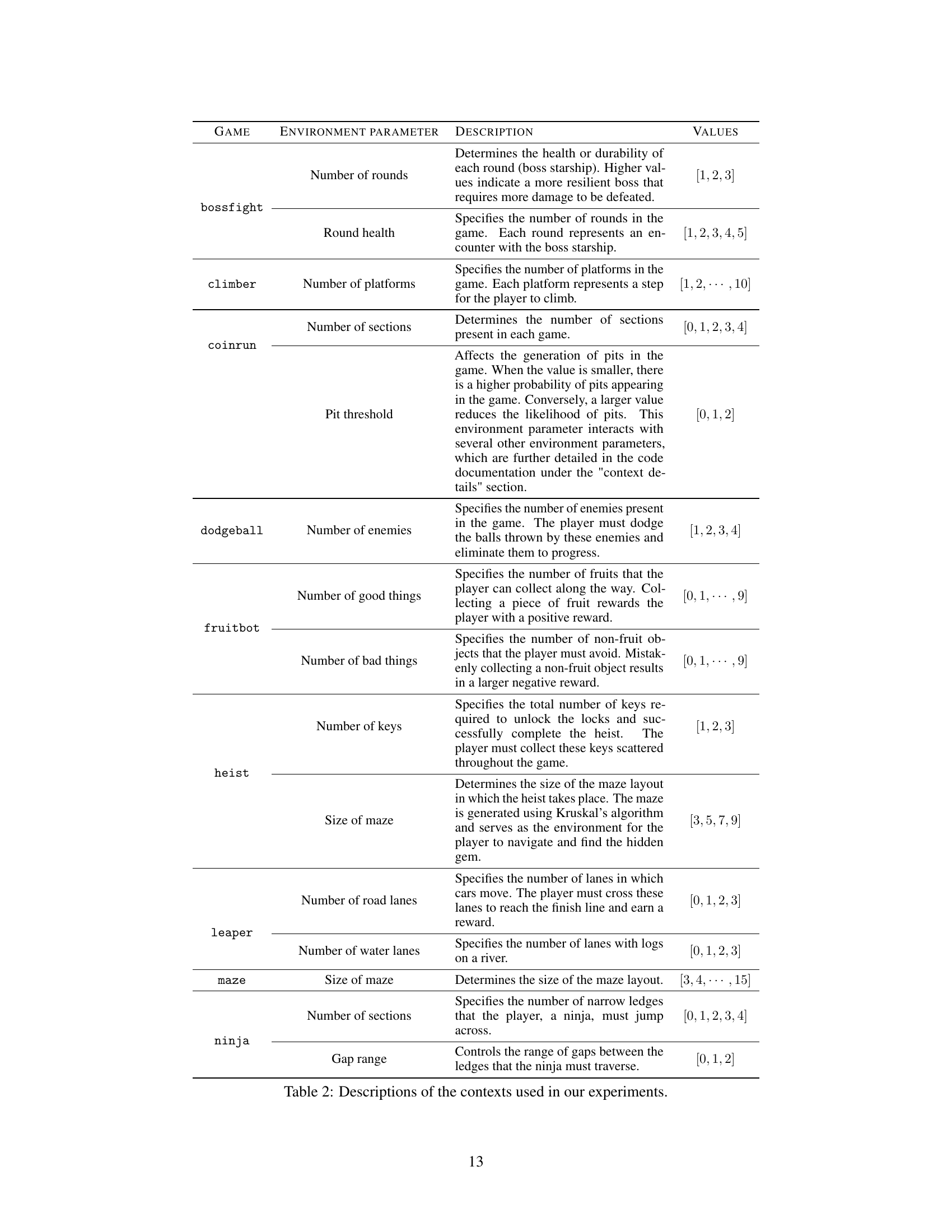
This table lists the hyperparameters used in the PPO algorithm for training agents on Procgen games. The values were largely based on previous work (Cobbe et al., 2020) for the easy mode of Procgen, with some minor adjustments. The hyperparameters control various aspects of the training process, such as the number of timesteps per rollout, the number of epochs, the learning rate, the use of an LSTM, and reward normalization.
In-depth insights#
Implicit Curriculum#
The concept of “Implicit Curriculum” in the context of reinforcement learning, particularly within procedurally generated environments like Procgen, is fascinating. It suggests that while environments may not be explicitly structured with increasing difficulty, the learning agent implicitly follows a curriculum. This occurs because the agent’s progress naturally shifts from easier to harder contexts, likely due to a combination of reward signals and the inherent statistical properties of level generation. The researchers highlight this by demonstrating that even with uniform sampling of levels, the agent’s performance and loss distribution shift over time, focusing on easier tasks initially and then progressively tackling more difficult ones. This observation challenges the conventional approach of explicit curriculum design in RL, indicating that emergent structure can arise organically. A key contribution is the creation of C-Procgen, which offers controlled access to environment parameters, enabling deeper analysis of these implicit learning dynamics. Future research will benefit from this nuanced understanding of implicit curricula and C-Procgen’s capabilities for investigating them further.
C-Procgen Benchmark#
The C-Procgen benchmark represents a significant advancement in procedural content generation for reinforcement learning research. By explicitly exposing and controlling environment parameters, previously hidden within Procgen’s black-box generation process, C-Procgen offers unparalleled insight into the learning dynamics of agents across diverse contexts. This enhanced controllability allows researchers to systematically investigate the impact of various factors, fostering a deeper understanding of implicit curricula and contextual reinforcement learning. The benchmark’s comprehensive and challenging nature, inherited from Procgen, ensures its relevance to cutting-edge research, while the added transparency facilitates more robust and reproducible experimental results. Furthermore, C-Procgen’s accessibility and ease of use makes it a valuable tool for exploring a wide range of research questions in curriculum learning and contextual reinforcement learning, ultimately pushing the field forward.
Learning Dynamics#
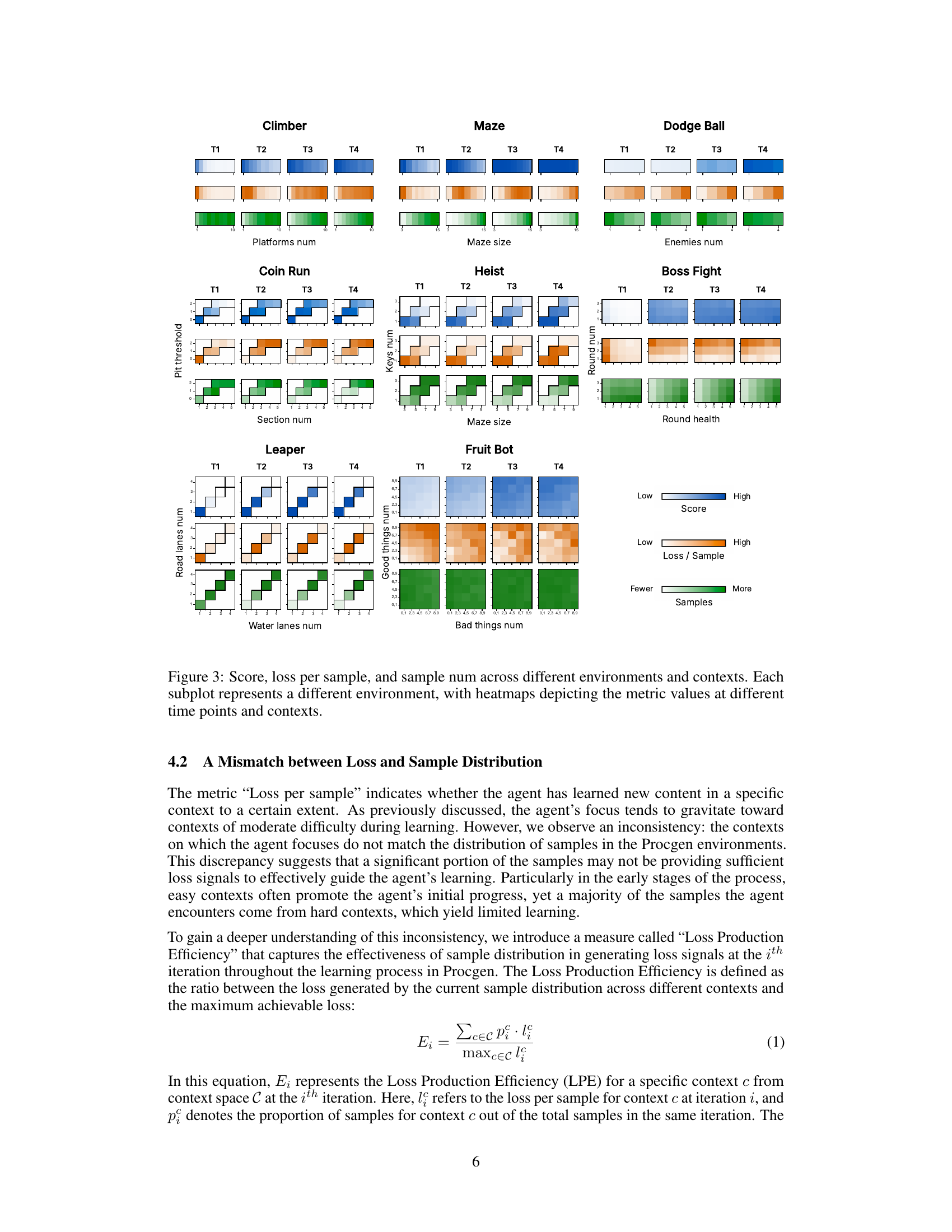
The section on Learning Dynamics in this research paper uses the C-Procgen benchmark to analyze how reinforcement learning agents progress across multiple contexts in procedurally generated environments. The key finding is the emergence of an implicit curriculum, where the agent naturally shifts focus from easier to harder contexts over time, even without explicit level prioritization. This is revealed through careful observation of metrics such as average score, loss per sample, and sample distribution across various contexts. A mismatch is observed between the loss concentration and the sample distribution, suggesting that a significant proportion of samples might be wasted on tasks already mastered. The analysis also investigates the impact of manipulating training contexts by masking or expanding the set, highlighting the crucial role some contexts play in enabling successful learning and the non-intuitive results that can arise from altering the context distribution. The findings offer valuable insights into implicit curriculum learning and the complexities of multi-context training, suggesting potential avenues for optimization techniques in curriculum reinforcement learning.
Context Effects#
The concept of ‘Context Effects’ in a reinforcement learning setting, particularly within procedurally generated environments like Procgen, is crucial. It highlights how an agent’s learning is significantly shaped by the specific characteristics of the environment it encounters at any given time. Variations in environment parameters (e.g., maze size, number of obstacles, agent speed) constitute different contexts, each impacting the difficulty of a task. A core observation is that agents don’t necessarily learn uniformly across all contexts; instead, there’s a natural progression, often starting with easier contexts and gradually moving towards more complex ones, even when contexts are randomly sampled. This implicitly creates a curriculum, revealing a fascinating self-organizing property of the learning process. This implicit curriculum, however, may lead to a mismatch between the distribution of training samples and where the learning progress is most concentrated. This is important because it suggests that the agent might be spending training resources on less crucial contexts. Understanding and controlling context effects is vital for improving sample efficiency and generalization performance in reinforcement learning, and may require targeted strategies for curriculum design or other context-aware learning algorithms.
Future Research#
Future research directions stemming from this work on implicit curricula in Procgen could explore several promising avenues. Investigating the interplay between the inherent complexity of different Procgen games and the emergence of implicit curricula is crucial. Further research should delve deeper into the dynamics of loss and sample distributions across various contexts and the relationship with agent performance. This includes examining whether specific context characteristics consistently predict the effectiveness of implicit curriculum learning. A particularly important area would be developing methods for proactively identifying and leveraging implicit curricula in other procedurally-generated environments and even in non-procedural settings. Finally, applying the findings to improve automatic curriculum learning algorithms is a key next step, focusing on techniques that can identify and exploit naturally occurring learning progressions.
More visual insights#
More on figures
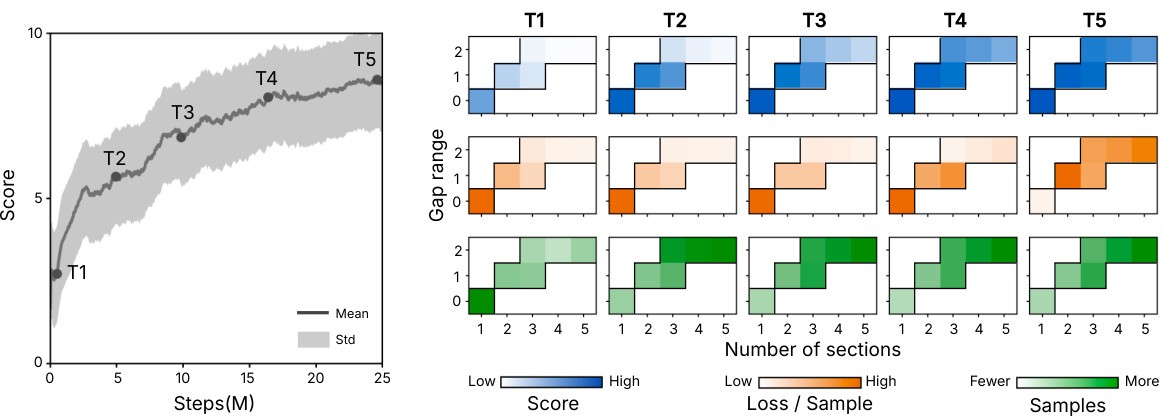
This figure analyzes the learning dynamics in the Procgen game Ninja. The left panel shows the training curve, highlighting five stages (T1-T5). The right panel uses heatmaps to visualize three key metrics across different contexts within each stage: average score, loss per sample, and the number of samples. This provides insights into how the agent’s performance, learning progress, and sampling distribution evolve across various levels of difficulty during the training process.
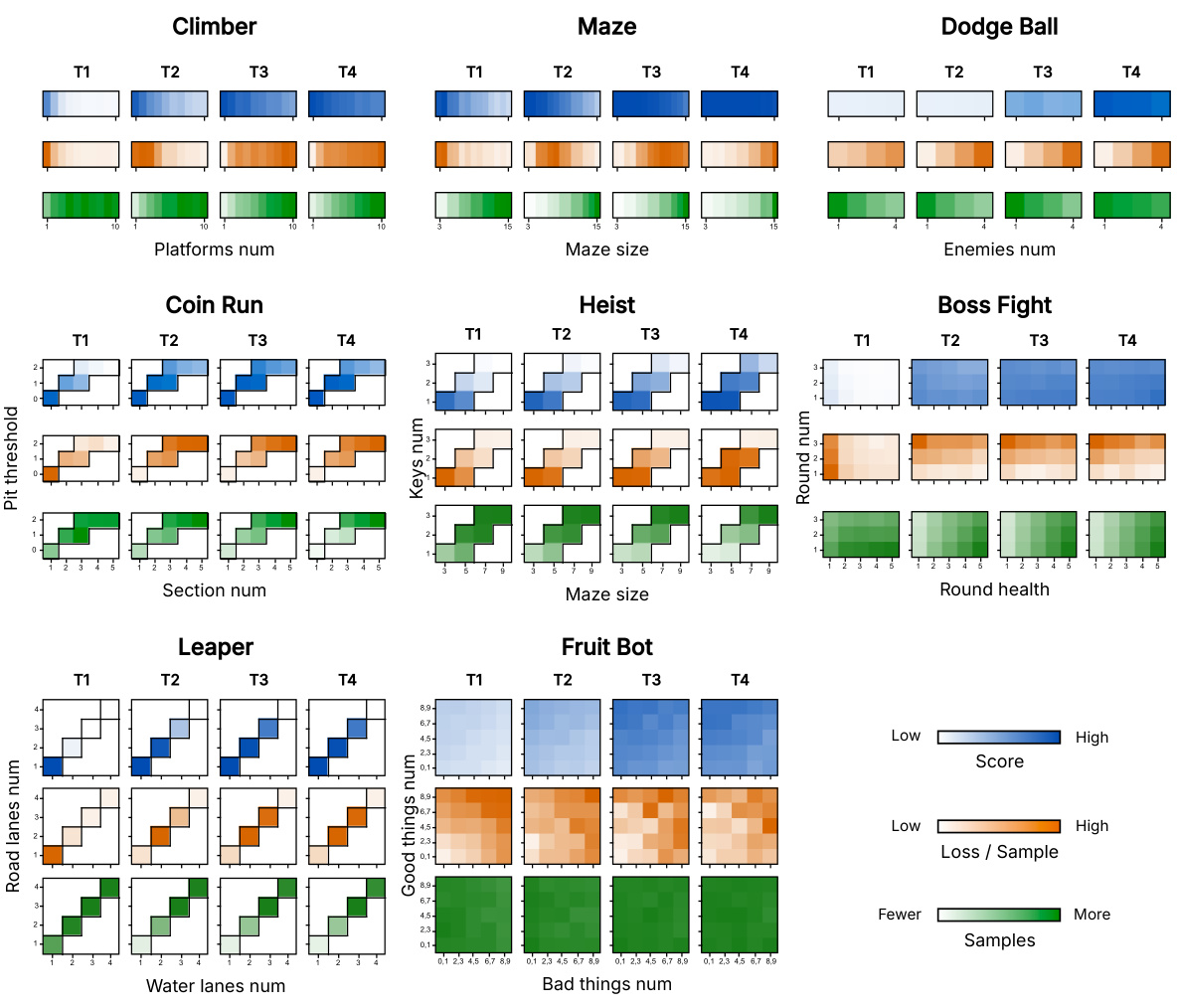
This figure presents a comprehensive analysis of learning dynamics across various Procgen environments and their associated contexts. It visualizes three key metrics: average score, loss per sample, and the number of samples collected for each context at different stages of training (T1-T5). Heatmaps are used to illustrate how these metrics vary across different contexts within each environment. The figure offers insights into the learning process, revealing how the agent’s focus shifts from simpler to more challenging contexts over time.
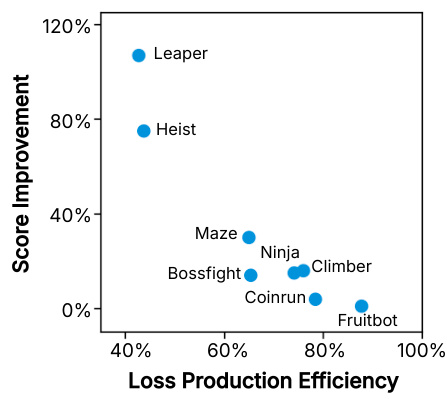
This figure shows the relationship between Loss Production Efficiency (LPE) and the performance improvement achieved by using the Prioritized Level Replay (PLR) algorithm in different Procgen games. The x-axis represents the LPE, a metric indicating the effectiveness of sample distribution in generating loss signals. The y-axis shows the score improvement (percentage increase) gained by employing PLR compared to using PPO alone. Each point represents a game from the Procgen benchmark. The figure suggests that games with lower LPE tend to see greater performance improvements when PLR is used, indicating that PLR is most beneficial in environments where the initial sample distribution is inefficient at guiding learning.
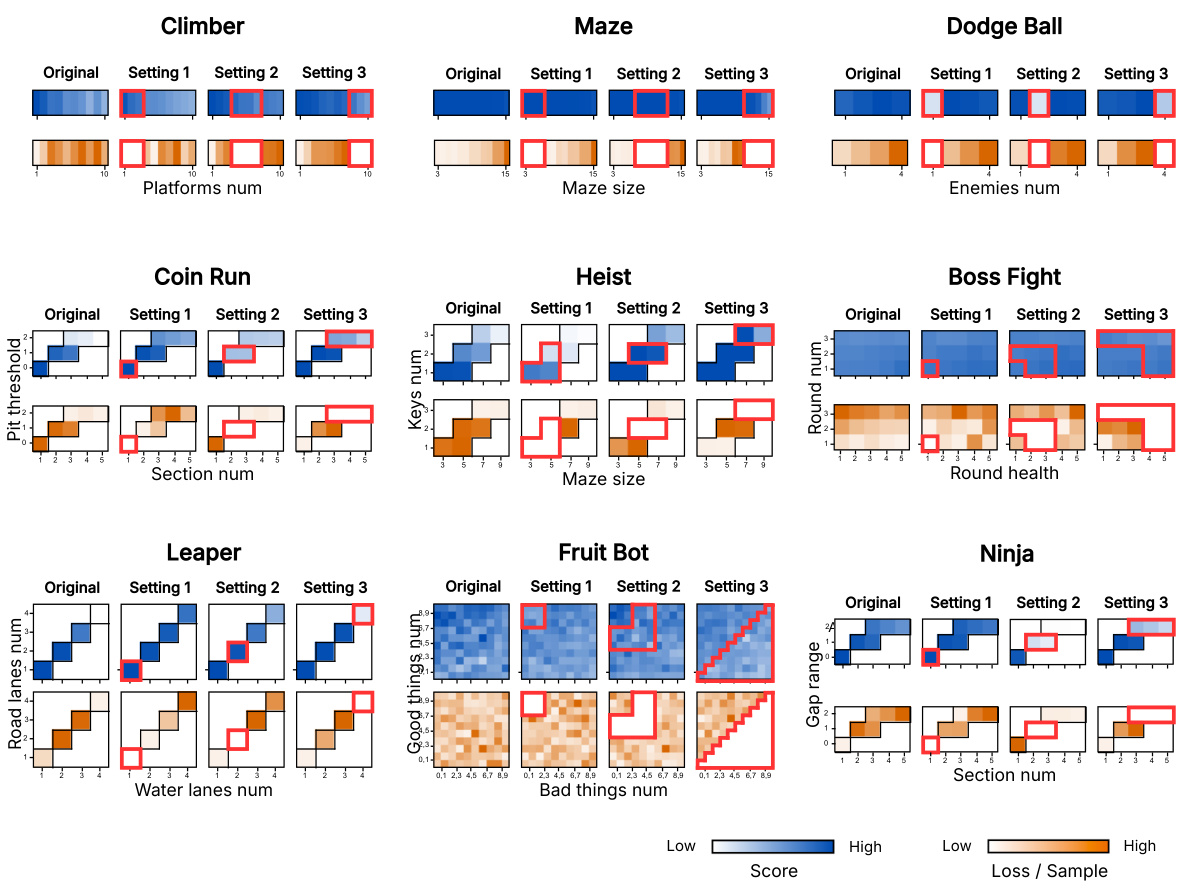
This figure visualizes the impact of modifying training contexts on the performance of reinforcement learning agents across nine different Procgen games. The leftmost column shows the performance under the original context settings. Subsequent columns represent three reconfigured settings where specific context groups were removed (masked, indicated by red boxes), showing how the agent’s score and loss per sample varied under different context configurations.
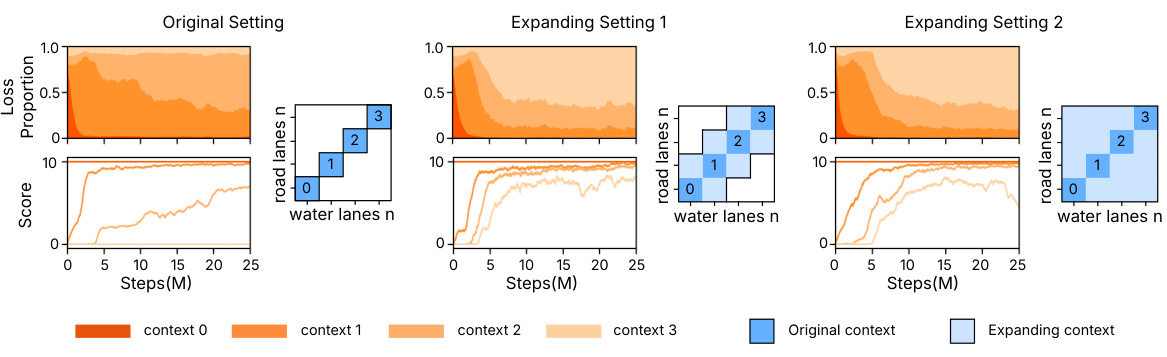
This figure displays the loss proportion and score curves for the game Leaper under three different context settings: Original Setting, Expanding Setting 1, and Expanding Setting 2. Each setting represents a different number of contexts (combinations of road lanes and water lanes). The plots show how the focus of loss (and learning progress) shifts across contexts over time. Expanding Setting 1 and 2 introduce more contexts and improved connectivity compared to the original, resulting in different learning dynamics. The heatmaps illustrate the distribution of contexts used in each setting.
Full paper#