↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Offline meta-reinforcement learning (OMRL) aims to enable AI agents to quickly adapt to new tasks using only past experience, which is safer than online learning. Context-based OMRL (COMRL) focuses on learning a universal policy conditioned on task representations, but existing methods struggle with generalization when the testing environment differs from the training data (context shift). Several methods have tried to improve generalization, but their approaches seemed disconnected.
This work proposes a unified information-theoretic framework called UNICORN, showing that existing COMRL algorithms essentially optimize the mutual information between task representations and their latent representations. This insight provides design flexibility for developing novel algorithms. UNICORN introduces a supervised and self-supervised implementation, demonstrating superior generalization across multiple RL benchmarks and context shift scenarios, offering a new perspective for understanding task representation learning in reinforcement learning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in offline meta-reinforcement learning. It offers a unified theoretical framework for understanding existing methods, provides design principles for novel algorithms, and demonstrates improved generalization performance across various benchmarks. The information-theoretic foundation presented opens avenues for more robust and efficient COMRL solutions, significantly impacting the field.
Visual Insights#
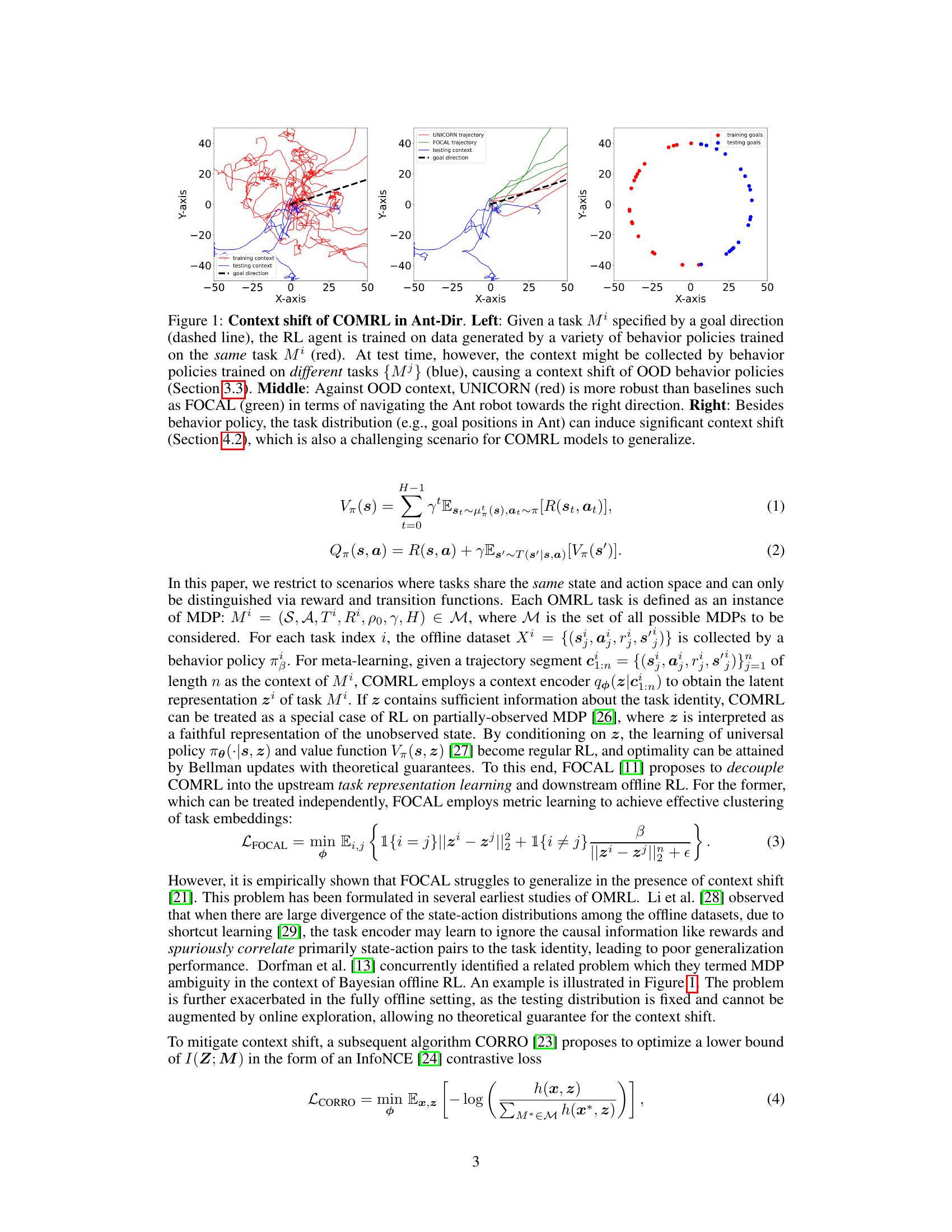
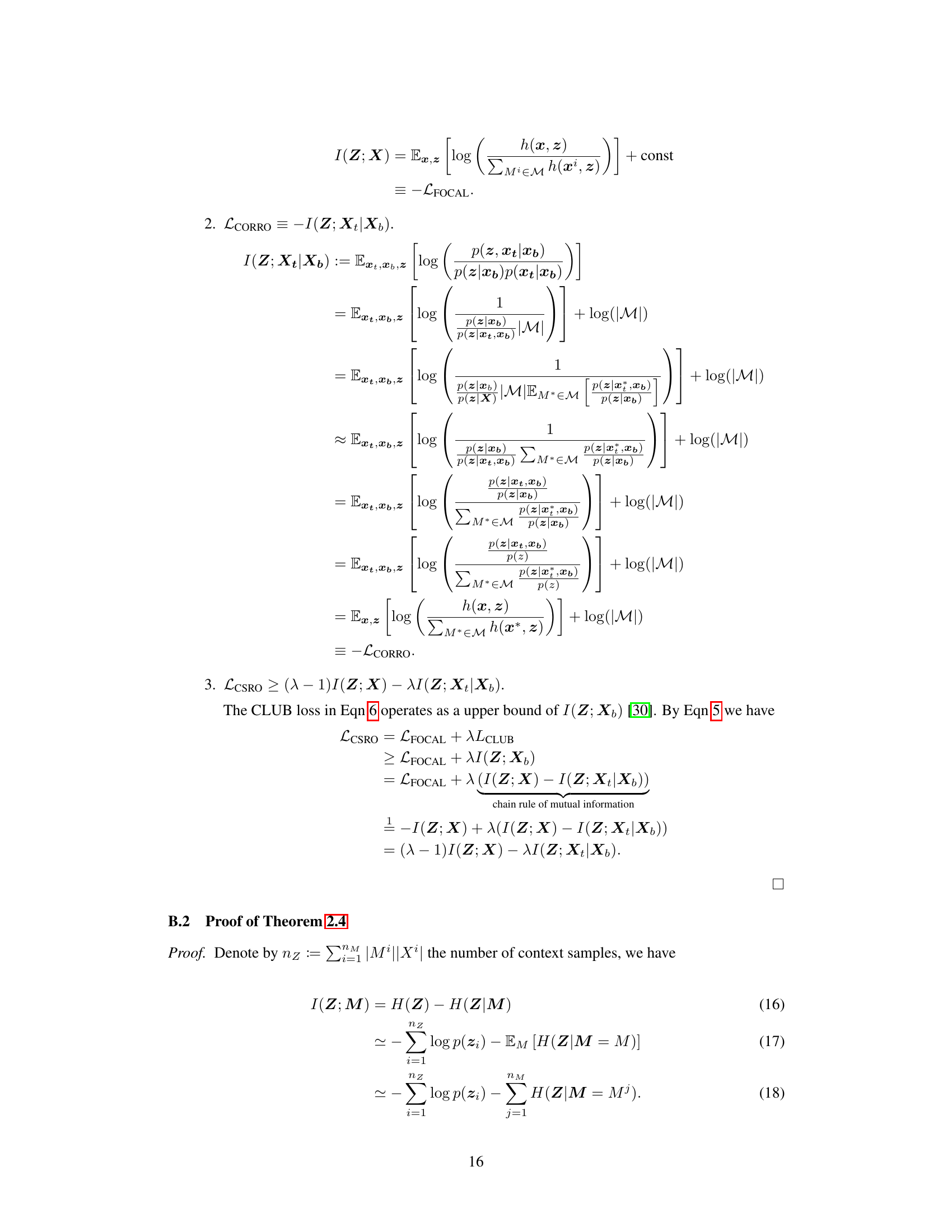
This figure demonstrates the concept of context shift in context-based offline meta-reinforcement learning (COMRL). The left panel shows how training data (red) from a single task is used to train the RL agent, but at test time, the context might be from different tasks (blue), leading to a context shift. The middle panel shows UNICORN’s superior robustness to this context shift compared to FOCAL, as evidenced by successful navigation towards the goal. Finally, the right panel illustrates how task distribution variation (e.g., different goal positions) can also induce significant context shift, highlighting the generalization challenge for COMRL models.

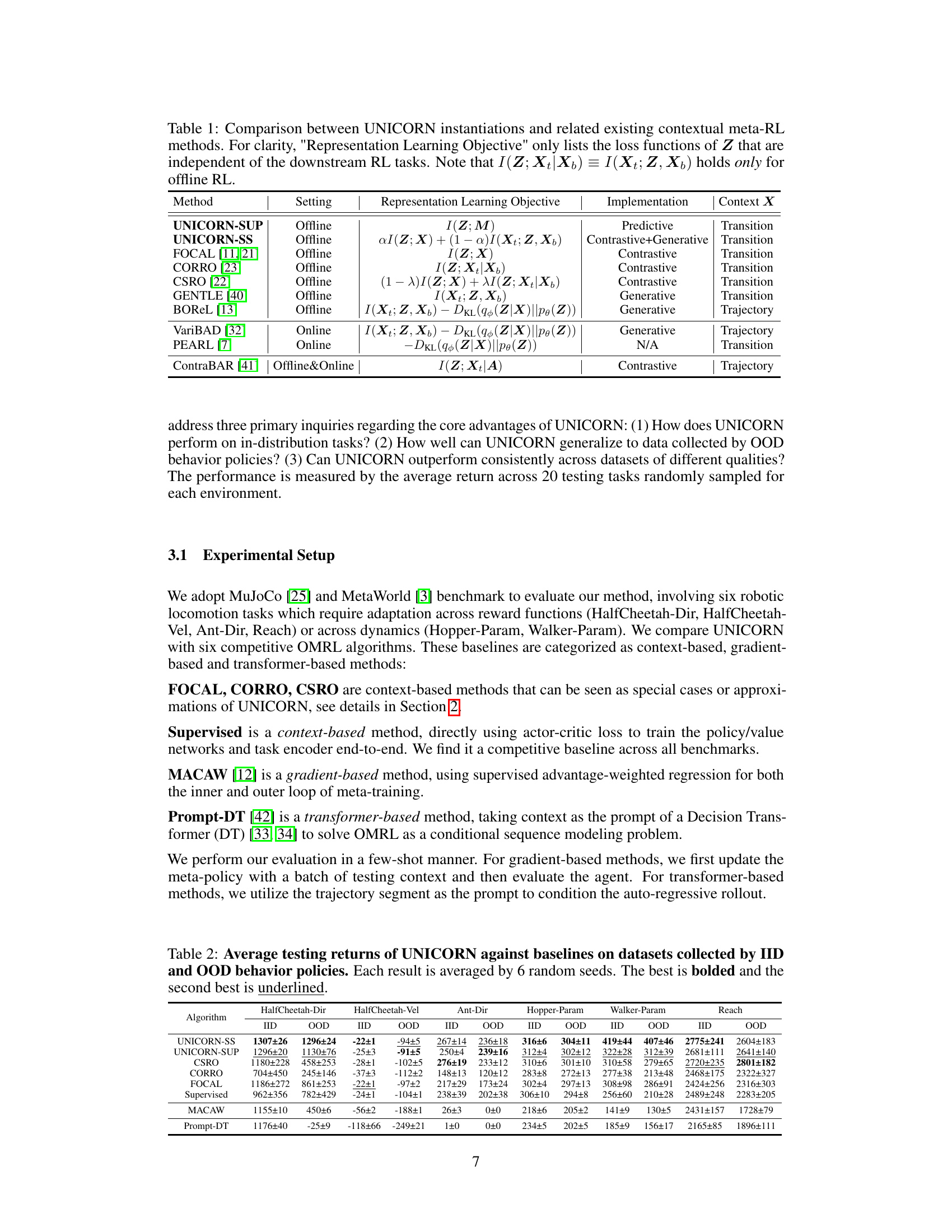
This table compares different contextual meta-reinforcement learning (COMRL) methods, including the proposed UNICORN and several baselines. It highlights the key differences in their settings (offline vs. online), representation learning objectives (the loss functions used to learn task representations Z), implementation details (e.g., contrastive, generative), and the type of context information (X) used. The table shows that UNICORN unifies and extends previous methods.
In-depth insights#
Unified COMRL#
A Unified COMRL framework offers a powerful lens through which to view and analyze context-based offline meta-reinforcement learning algorithms. By unifying seemingly disparate approaches under a common information-theoretic objective, such a framework reveals fundamental connections and trade-offs. This unified perspective enables a deeper understanding of the strengths and weaknesses of existing methods, such as FOCAL, CORRO, and CSRO, highlighting how they approximate the core mutual information objective. Furthermore, a unified framework facilitates the design of novel algorithms by offering a principled roadmap for exploring alternative approximations or regularizations of the core objective. The success of a unified COMRL approach hinges on effectively capturing the relevant information about the task while mitigating spurious correlations present in the data. A key challenge is robustly addressing context shift, ensuring reliable generalization across diverse environments and data distributions. Finally, a successful unified framework must bridge theory and practice, offering both theoretical justifications and strong empirical validation demonstrating improved performance and generalization capabilities.
Info. Theo. Basis#
An information theoretic basis for context-based offline meta-reinforcement learning (COMRL) would rigorously establish the link between task representation learning and the resulting performance. A core concept would be to maximize the mutual information I(Z;M) between the task variable M and its latent representation Z. This would quantify how effectively Z captures relevant information about the task. Different COMRL algorithms could then be analyzed as approximations of this objective, with variations in their bounds and regularizations explaining their performance differences and robustness to context shifts. For instance, a tighter bound on I(Z;M) could lead to improved generalization. The framework should also incorporate causal reasoning to differentiate between spurious correlations and actual task characteristics, addressing the challenges of out-of-distribution generalization. This rigorous framework provides a valuable lens to analyze existing methods and inspire new algorithms, potentially paving the way for more efficient and robust offline meta-learning in complex scenarios.
Supervised/Unsupervised#
The dichotomy of supervised versus unsupervised learning in the context of offline meta-reinforcement learning (OMRL) is a crucial consideration. Supervised approaches, leveraging labeled data (task identities), offer a direct pathway to learn effective task representations. This allows for straightforward optimization of the mutual information between task variables and their latent representations. However, reliance on labeled data can limit generalizability and scalability. Unsupervised methods, conversely, aim to extract task representations from unlabeled data, often through self-supervised techniques such as contrastive learning or reconstruction. These methods are intrinsically more generalizable, as they don’t rely on pre-existing task labels. The trade-off lies in the difficulty of effectively capturing task-relevant information without explicit supervision. The choice between supervised and unsupervised approaches depends heavily on data availability, desired generalizability, and computational constraints. A hybrid approach, incorporating aspects of both paradigms, might offer the best of both worlds: leveraging labeled data where available to enhance learning while retaining the unsupervised methods’ robustness and flexibility for handling unseen tasks.
OOD Generalization#
Out-of-Distribution (OOD) generalization is a crucial aspect of offline meta-reinforcement learning (OMRL), focusing on an agent’s ability to adapt to unseen tasks or environments. Existing OMRL methods often struggle with OOD generalization because they may overfit to the training data distribution, failing to extrapolate knowledge to novel contexts. This is particularly challenging in offline settings where online interactions are not possible for refinement. The paper investigates this limitation through experiments and theoretical analysis, showing how a unified information theoretic framework, called UNICORN, provides insights into the causal relationships between the input data and task representations. UNICORN helps explain why some methods are more robust to context shifts than others, highlighting the tradeoff between leveraging causal correlations and mitigating spurious correlations. This is a significant contribution towards building more robust and adaptable RL agents, crucial for applying RL to real-world problems. The experiments demonstrate that UNICORN instantiations exhibit improved OOD performance compared to existing baselines, showing a clear path toward improving generalization capabilities in offline meta-RL.
Future Directions#
Future research directions in offline meta-reinforcement learning (OMRL) could profitably explore several key areas. Improving the efficiency and scalability of OMRL algorithms is crucial, as current methods can be computationally expensive and challenging to train with large datasets. Developing more robust methods for handling context shifts and out-of-distribution data is also critical for reliable real-world application. This involves developing more sophisticated task representation learning techniques and/or incorporating uncertainty modeling. Investigating the theoretical foundations of OMRL more deeply, particularly regarding the interplay between generalization performance and the choice of mutual information bounds, would contribute to a more principled approach. Combining OMRL with other advanced RL techniques, such as model-based RL, hierarchical RL, and transfer learning, could unlock new capabilities and overcome current limitations. Finally, exploring more diverse and challenging application domains for OMRL is key to demonstrate its practical impact. This includes pushing the boundaries of safety-critical settings, such as robotics and healthcare, which present unique demands on data quality, robustness, and safety.
More visual insights#
More on figures
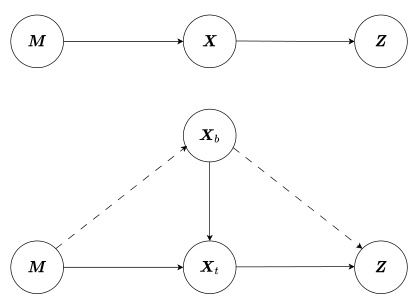
This figure presents two graphical models illustrating the causal relationships between variables in context-based offline meta-reinforcement learning (COMRL). The top model shows a simple Markov chain where the task variable (M) influences the context (X), which in turn influences the latent representation (Z). The bottom model provides a more nuanced perspective, breaking down the context (X) into two components: behavior-related (Xb) and task-related (Xt). The dashed lines indicate a weaker or indirect causal link, while solid lines represent a stronger, more direct relationship. This model highlights the distinctions between spurious correlations (Xb to Z) and causal relationships (Xt to Z) when learning task representations.
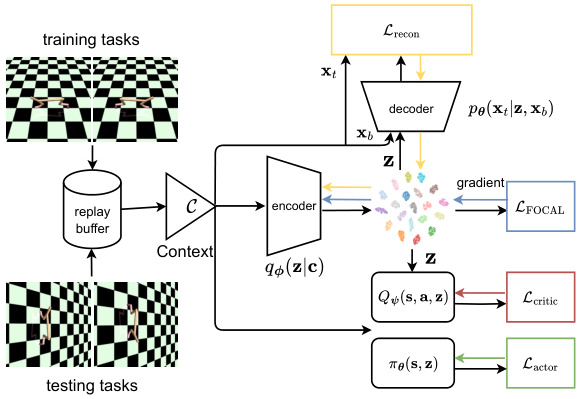
This figure shows the meta-learning procedure of the self-supervised variant of UNICORN (UNICORN-SS). It is composed of several components: a context encoder that processes the context information C from a replay buffer, a decoder that reconstructs the task-related component Xt of the context X, and a policy network πθ(s,z) that outputs actions conditioned on the state s and latent representation z. The training process involves minimizing the reconstruction loss Lrecon, the contrastive loss LFOCAL, and the actor-critic losses Lactor and Lcritic. The supervised variant UNICORN-SUP replaces the decoder with a classifier to directly predict the task label M from the latent representation z, optimizing a cross-entropy loss instead.
This figure demonstrates the concept of context shift in offline meta-reinforcement learning (OMRL). The left panel shows how training data might be collected with policies specific to one task, while testing occurs in a shifted context using policies from different tasks. The middle panel highlights UNICORN’s superior robustness to this context shift, contrasted with FOCAL. The right panel illustrates that variations in task distributions (e.g., the goal locations in the Ant environment) can also cause substantial context shifts, challenging the generalization of OMRL models. The figure visually represents the challenge of COMRL in handling unexpected context shifts during testing and showcases the improved performance of UNICORN.
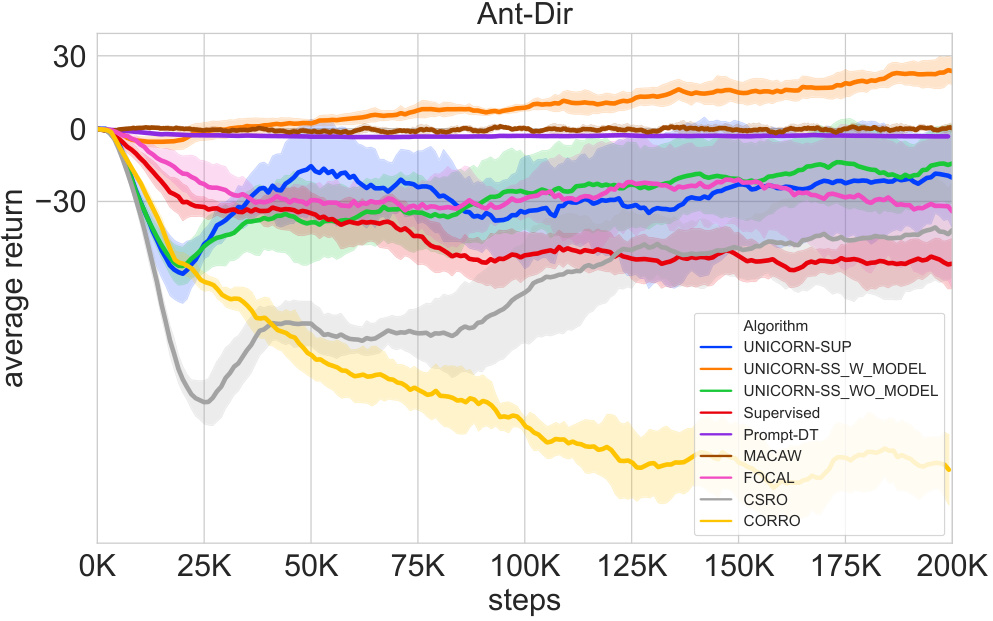
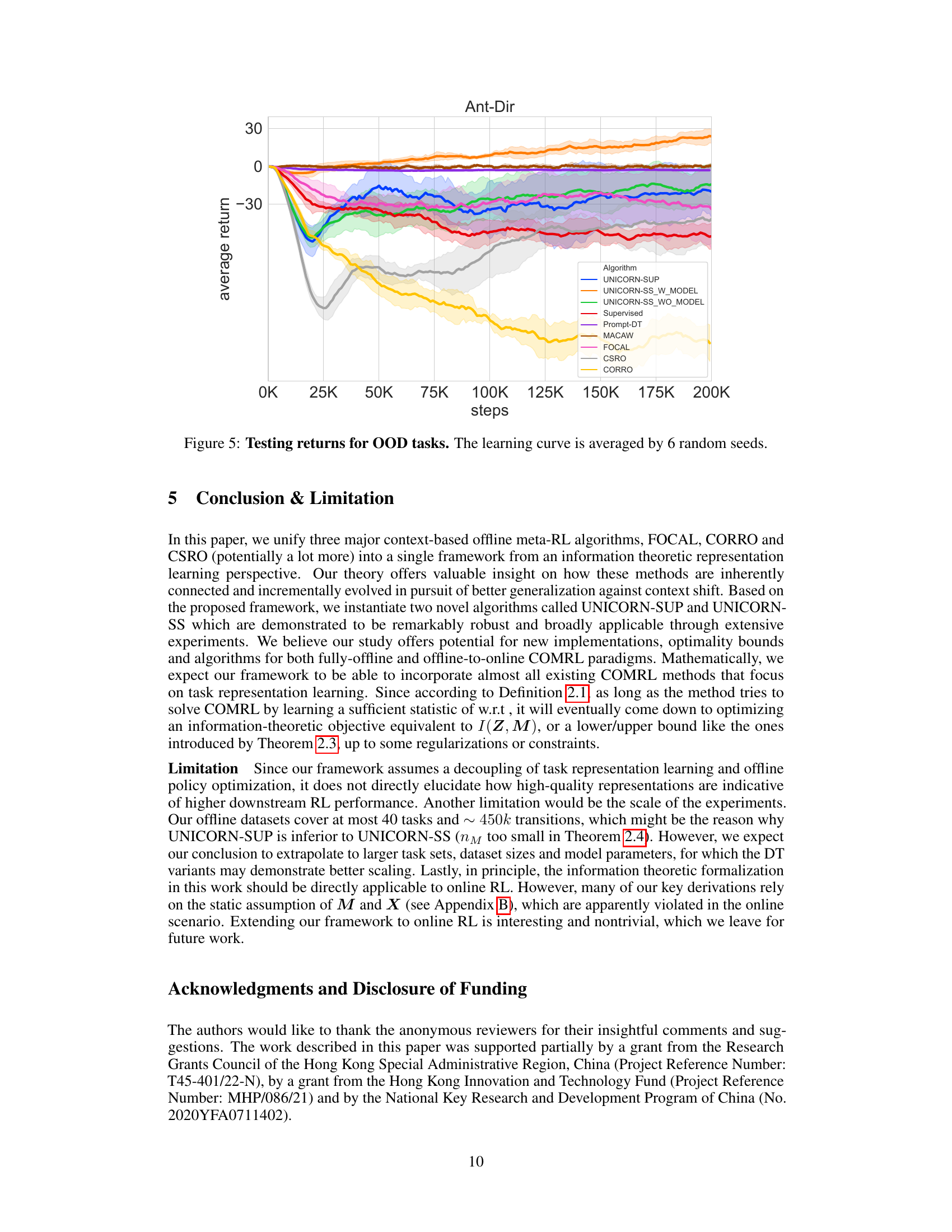
This figure displays the average testing return for out-of-distribution (OOD) tasks across different algorithms over 200k training steps. The performance of various offline meta-reinforcement learning algorithms, including UNICORN-SUP, UNICORN-SS with and without a model-based component, Supervised, Prompt-DT, MACAW, FOCAL, CORRO, and CSRO are compared. The results show the average return across multiple trials (averaged over 6 random seeds), highlighting the algorithms’ generalization capability in handling contexts from different behavior policies.
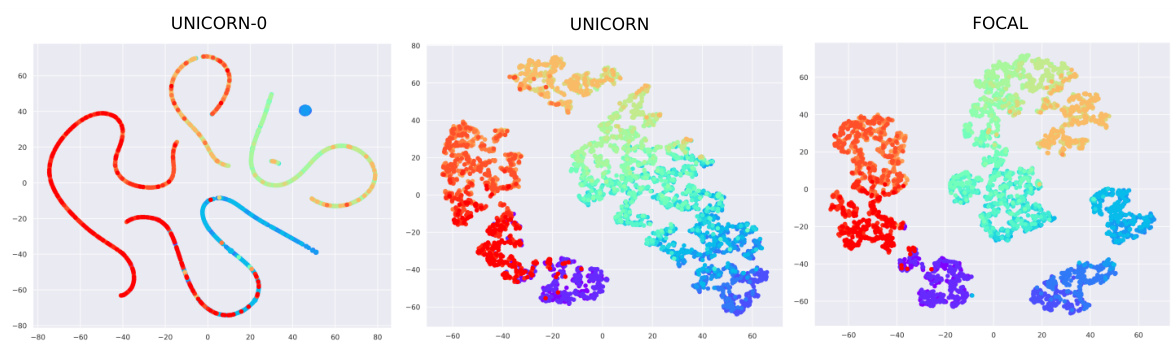
This figure shows the 2D projection of task representations learned by three different algorithms: UNICORN-0, UNICORN, and FOCAL. Each point represents a task, colored according to its goal direction (0 to 6, purple to red). The algorithms’ ability to cluster tasks based on similarity is visualized. UNICORN-0 shows some clustering but less distinct separation than UNICORN. FOCAL shows distinct clusters, but less smooth transition between clusters than UNICORN.
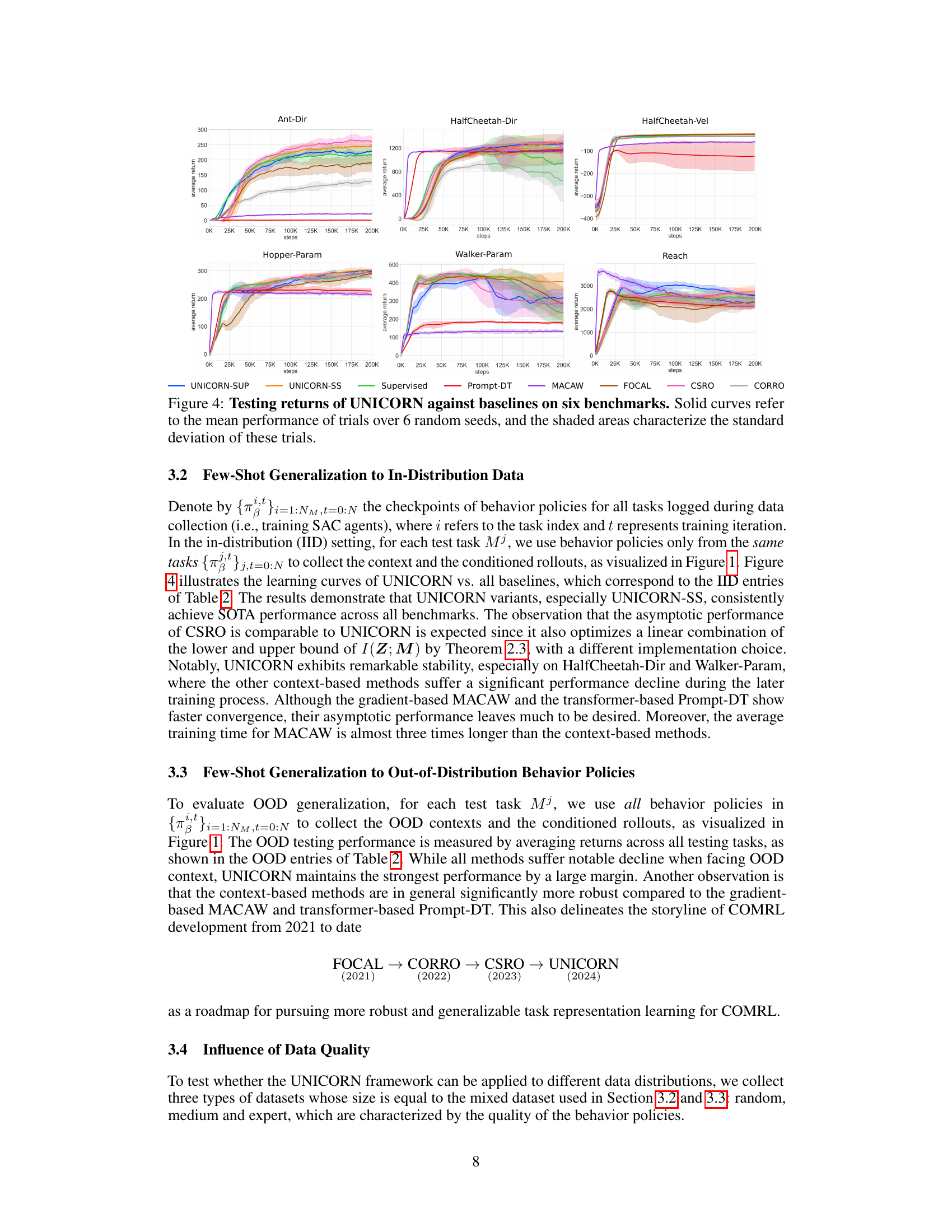
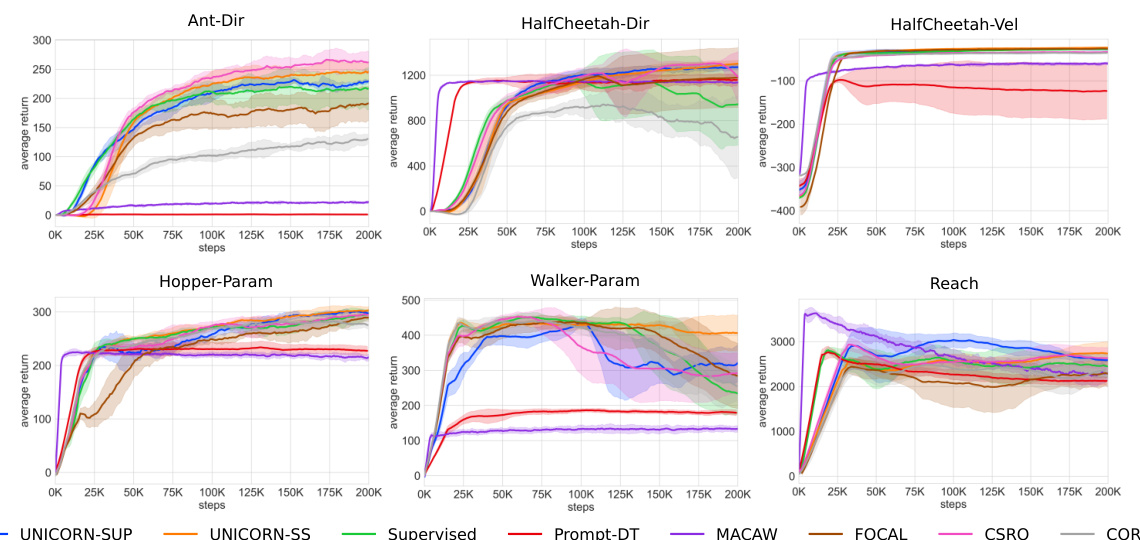
This figure compares the performance of UNICORN against other baselines (FOCAL, CORRO, CSRO, Supervised, MACAW, Prompt-DT) across six different MuJoCo and Metaworld benchmark tasks. The y-axis represents the average return of the RL agent, and the x-axis represents the number of training steps. Solid lines show the average performance over six trials for each algorithm on each task, and the shaded region represents the standard deviation across those trials, illustrating the variability in performance. This allows for a direct comparison of the algorithms’ learning curves and their final performance.
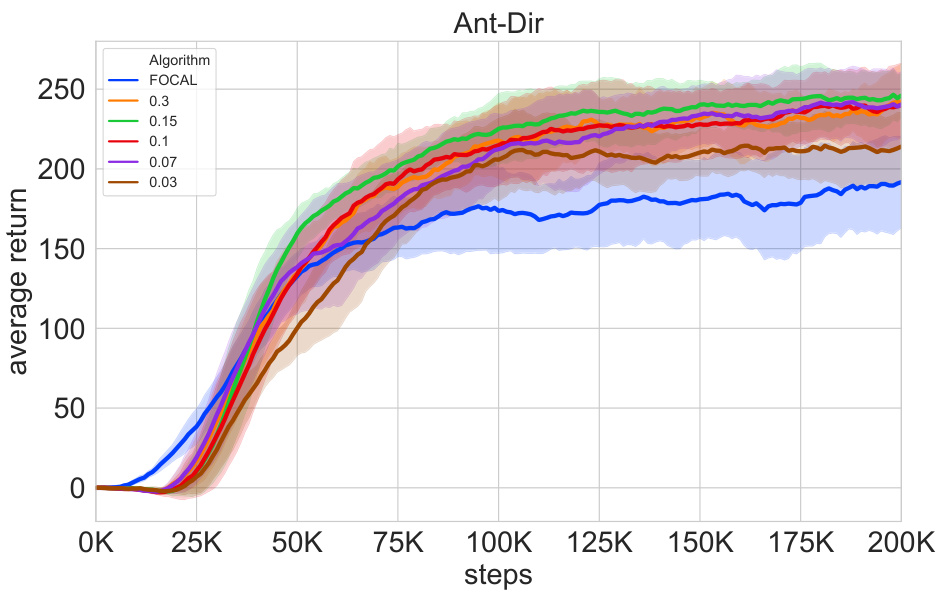
This figure shows the ablation study on the effect of the hyperparameter α on the performance of the UNICORN-SS algorithm. It shows that as α increases, performance generally improves, but excessively high values lead to decreased performance. This is consistent with the theoretical analysis presented in the paper which demonstrates a tradeoff between maximizing causal correlations and minimizing spurious correlations. The plot shows the mean and shaded area representing standard deviation across 6 random seeds.
More on tables
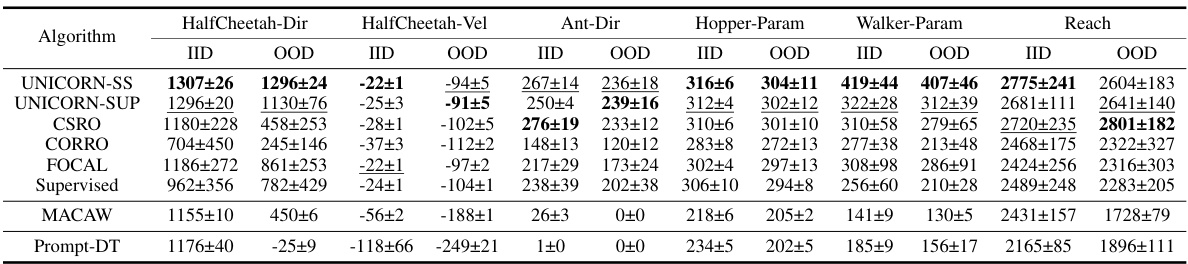
This table compares the proposed UNICORN method with other existing contextual meta-reinforcement learning methods. It highlights the differences in their settings (online vs. offline), implementations (predictive, contrastive, generative), the type of context used, and their representation learning objectives. The table helps illustrate how UNICORN unifies and extends previous methods within a common information-theoretic framework.
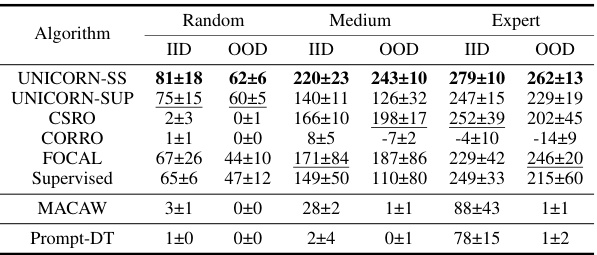
This table presents a comparison of the performance of UNICORN and other algorithms (CSRO, CORRO, FOCAL, Supervised, MACAW, Prompt-DT) on the Ant-Dir task in MetaWorld. The performance is evaluated on three datasets with varying data quality: Random, Medium, and Expert. For each data quality level and algorithm, the average return on in-distribution (IID) and out-of-distribution (OOD) tasks is reported, along with standard deviations.
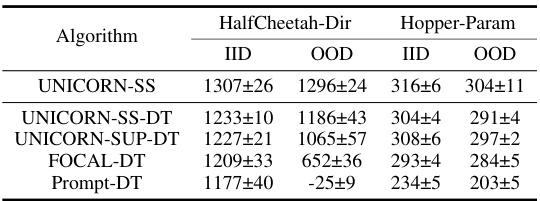
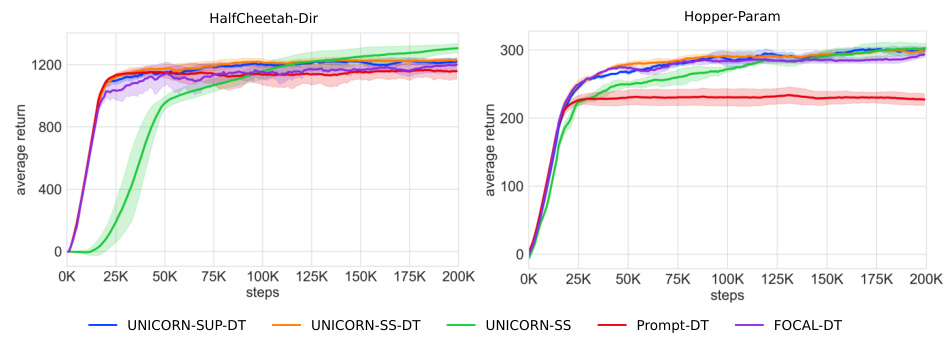
This table presents the results of applying the UNICORN framework with a Decision Transformer (DT) model to two robotic control tasks: HalfCheetah-Dir and Hopper-Param. It compares the performance of UNICORN-SS-DT, UNICORN-SUP-DT, FOCAL-DT, and Prompt-DT, showing the average return (across 6 random seeds) for both in-distribution (IID) and out-of-distribution (OOD) test tasks. The table highlights the effectiveness of the UNICORN approach when combined with a DT.
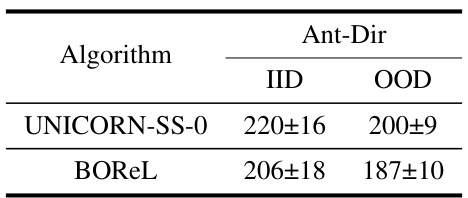
This table compares the performance of UNICORN-SS-0 (a label-free version of UNICORN-SS) and BOREL, another label-free COMRL method, on the Ant-Dir task. The comparison is done for both in-distribution (IID) and out-of-distribution (OOD) data. The results show the average return with standard deviation for both algorithms in each setting.
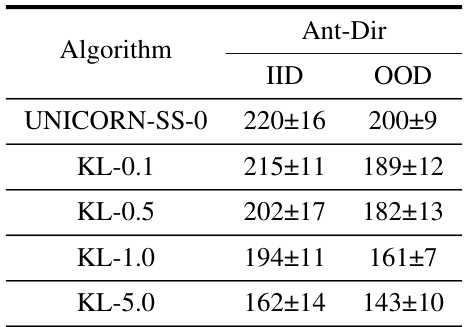
This table compares the performance of UNICORN-SS-0, a label-free version of the UNICORN algorithm, against another label-free COMRL method called BOREL. The comparison is done on the Ant-Dir environment, and the results show the average return (with standard deviation) for both in-distribution (IID) and out-of-distribution (OOD) scenarios.
This table compares different contextual meta-reinforcement learning (meta-RL) methods, including the proposed UNICORN and its variants (UNICORN-SUP, UNICORN-SS), along with several baselines (FOCAL, CORRO, CSRO, GENTLE, BOREL, PEARL, ContraBAR). The comparison is based on several key aspects: the setting of the method (offline vs online), the implementation approach (predictive, contrastive, generative), the type of context used (transition, trajectory), and the specific objective function used for representation learning. It highlights the theoretical connections between these methods, showing that several existing algorithms can be viewed as approximations or bounds of the mutual information objective I(Z; M).
Full paper#