↗ OpenReview ↗ NeurIPS Proc. ↗ Chat
TL;DR#
Reinforcement learning (RL) typically assumes rewards are observed only after actions. However, many real-world scenarios offer partial advance knowledge of future rewards (e.g., knowing prices before a transaction). This paper investigates the value of such
lookahead information using competitive analysis, a framework to measure the performance of an algorithm compared to an optimal one. The challenge is quantifying the performance increase resulting from lookahead information by comparing the reward an agent receives with and without this information. The issue is that reward improvements vary widely with different reward distributions and environment dynamics.
This paper addresses this challenge by focusing on the worst-case scenarios. The authors derive exact formulas for the worst-case performance ratio for different lookahead levels, showing connections to established concepts in offline RL and reward-free exploration. Notably, they find that long-shot reward distributions (high rewards with low probability) maximize the lookahead advantage. They provide tight bounds on this worst-case performance ratio, covering a wide range of lookahead from observing immediate rewards to all future rewards. These results are significant because they offer a way to quantify the potential benefits of using future information in RL, guiding the design of more efficient and robust algorithms.
Key Takeaways#
Why does it matter?#
This paper is crucial because it quantifies the value of incorporating future reward information in reinforcement learning. It bridges the gap between theoretical understanding and practical applications by providing concrete worst-case competitive ratios, which are important for designing robust and efficient RL agents. This work also connects RL with existing research on reward-free exploration and offline RL, potentially leading to significant advancements in both areas.
Visual Insights#
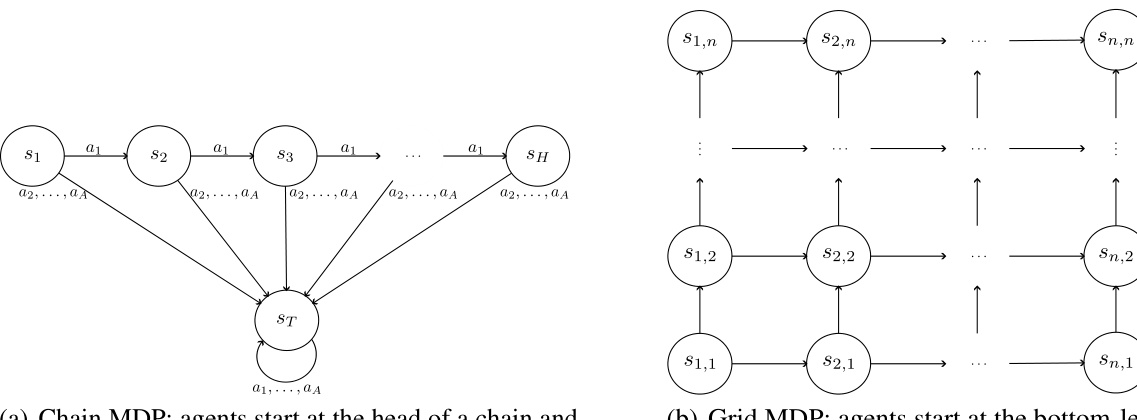
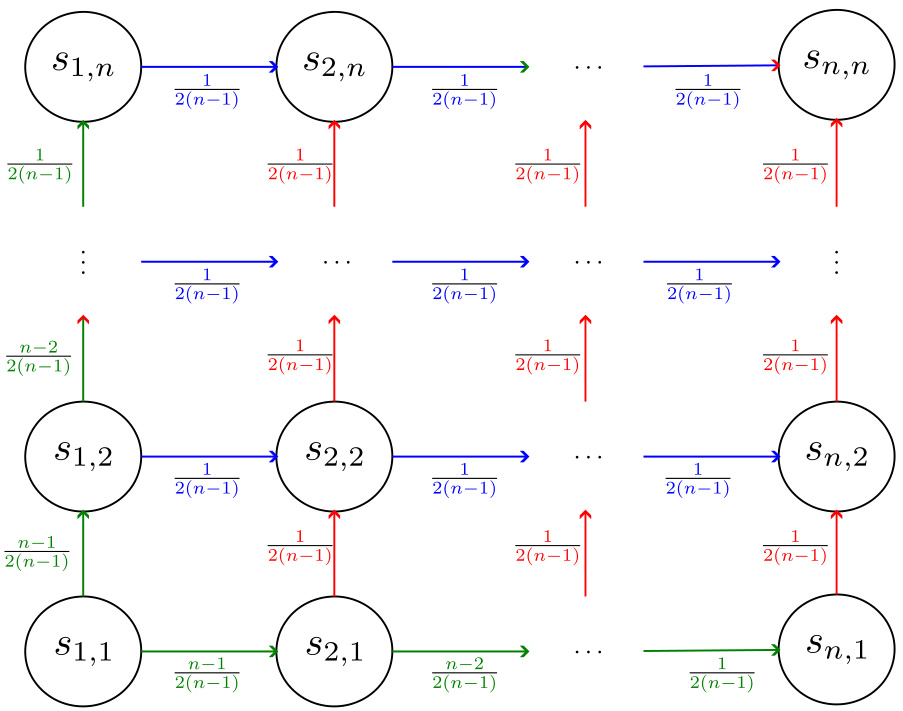
This figure shows two example Markov Decision Processes (MDPs) used in the paper to analyze the competitive ratio (CR) of reward lookahead. The first is a chain MDP, where an agent starts at the head of a chain and can either move forward or transition to an absorbing terminal state. The second is a grid MDP, where the agent starts at the bottom-left corner and can move up or right until reaching the top-right corner. These examples are used to illustrate how the CR changes in different MDP structures and to show that the worst-case CR could be achieved in simple environments.
In-depth insights#
Reward Lookahead Value#
The concept of “Reward Lookahead Value” explores the benefit of providing reinforcement learning (RL) agents with future reward information. Instead of receiving rewards solely after taking actions, lookahead grants access to upcoming rewards, allowing for more informed decision-making. This paper investigates this concept by employing competitive analysis, comparing the performance of standard RL agents against those with varying degrees of lookahead. A key finding is the characterization of worst-case reward distributions, which surprisingly link to existing offline RL and reward-free exploration concepts. The study goes further to quantify the value of lookahead through competitive ratios (CR), showing a strong dependence on the environment’s dynamics and lookahead extent. The results highlight a spectrum of possibilities, ranging from observing immediate rewards to having full foresight, providing valuable insights into the tradeoffs between increased performance and the cost of acquiring future reward information.
Worst-Case Analysis#
A worst-case analysis in a research paper usually focuses on identifying the least favorable conditions or inputs under which a system or algorithm might perform. It’s a pessimistic approach, aiming to establish lower bounds on performance or to expose potential vulnerabilities. In the context of reinforcement learning, a worst-case analysis might involve constructing adversarial environments or reward distributions that are specifically designed to challenge the learning agent. This helps in understanding the robustness and limitations of algorithms, and is particularly useful when dealing with uncertain or partially observable environments. The outcome is a guarantee of performance, even if it is a low one. Such analyses often reveal critical insights about the factors that most significantly impact an algorithm’s performance, enabling the development of more resilient algorithms. Finding tight bounds that are both upper and lower are particularly valuable, offering a more complete understanding of the algorithm’s behavior in the worst case.
Competitive Ratios#
Competitive ratios offer a powerful framework for analyzing the performance gains from incorporating reward lookahead in reinforcement learning. They provide a principled way to quantify the potential improvement by comparing the performance of an optimal agent with no lookahead to that of an agent that can access future rewards. By characterizing the worst-case scenarios, competitive ratios help determine the maximum possible loss incurred from not using this additional information. This is particularly crucial when the cost of obtaining or processing lookahead data is significant. The analysis often involves identifying worst-case reward distributions, which maximize the advantage of lookahead agents, and worst-case environment dynamics, leading to tight bounds on the competitive ratio. These bounds are frequently linked to fundamental quantities in offline RL and reward-free exploration, suggesting a deeper theoretical connection between these seemingly distinct areas. The results illuminate the tradeoffs between computational complexity and performance gains associated with incorporating reward lookahead. The spectrum of lookahead capabilities, from observing immediate rewards to having full foresight, is systematically explored, revealing how the potential benefit scales with the amount of future reward information available.
Multi-Step Lookahead#
The concept of multi-step lookahead in reinforcement learning significantly enhances the capabilities of agents by allowing them to consider future rewards before making decisions. This contrasts sharply with traditional RL, where agents only observe rewards after taking actions. By incorporating this future information, lookahead agents can make more informed choices, potentially leading to significantly improved overall reward accumulation. The value of multi-step lookahead is analyzed through competitive analysis, comparing the performance of lookahead agents against those with no lookahead. The analysis delves into characterizing the worst-case reward distributions, determining the scenarios where lookahead provides the greatest advantage. This includes exploring scenarios with long-shot rewards and tight bounds on the competitive ratio, providing insights into the trade-offs between computational complexity and the gains obtained from lookahead. The findings reveal a close relationship between lookahead and established quantities within reward-free exploration and offline RL, which offers valuable insights into this advanced RL concept.
Future Work#
The paper’s “Future Work” section suggests several promising avenues. Extending the competitive analysis framework to transition lookahead is crucial, as it would offer a more realistic model of real-world scenarios where agents might have imperfect knowledge of future states. Investigating approximate planning techniques for multi-step lookahead is vital to bridge the gap between theoretical results and practical applications. This requires developing efficient algorithms that can leverage lookahead information without incurring excessive computational costs. The authors also propose analyzing the impact of approximate future reward information, a realistic scenario given uncertainties in real-world problems. Finally, exploring the connections between the derived competitive ratios and other concentrability coefficients in offline RL and reward-free exploration is important to unify and deepen our understanding of exploration in reinforcement learning.
More visual insights#
More on figures
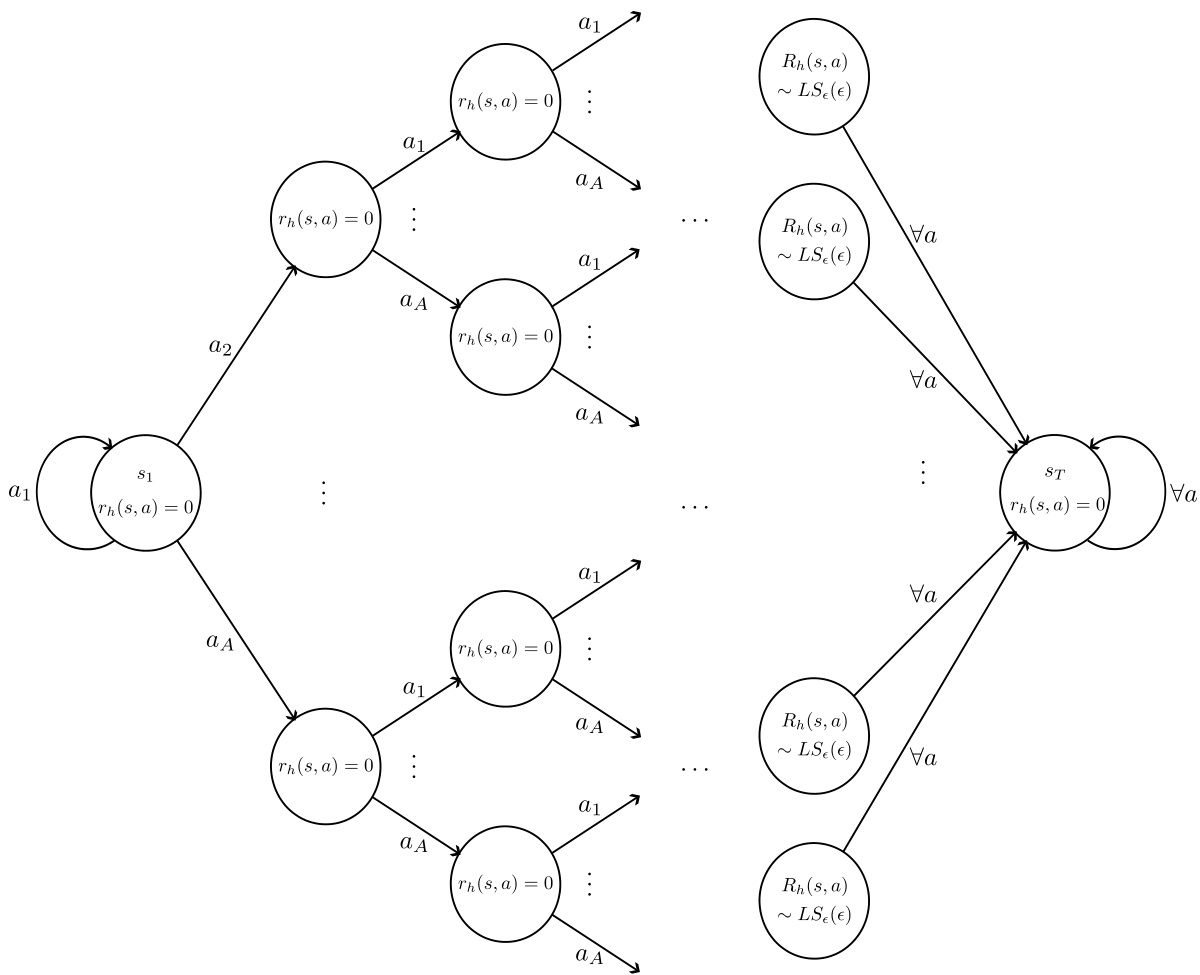
This figure shows a tree-like Markov Decision Process (MDP) used to illustrate a near-worst-case scenario for the competitive ratio (CR). The agent starts at the root and can choose to stay there or traverse the tree. Once traversal begins, the agent must continue until reaching a leaf node. Leaf nodes have a long-shot reward distribution (very high reward with low probability). All other nodes have zero reward. This structure is designed to highlight the difference in performance between agents with and without reward lookahead.
This figure shows a tree-like Markov Decision Process (MDP) used to illustrate a near worst-case scenario for the competitive ratio. The agent starts at the root node and can choose to either stay at the root or traverse down the tree. Once traversal starts, it must continue to a leaf node. Leaf nodes have a long-shot reward (high reward with low probability), while all other nodes have zero reward. The structure forces a trade-off between immediate rewards and long-term rewards, making it a challenging environment to analyze lookahead.
Full paper#



















